Download

1 / 53
530 likes | 550 Views
This outlines the infrastructure for sharing microarray data, covering topics like gene expression, data availability, repositories, and standards. Learn about the complexities of sharing gene expression data, types of data matrices, sample annotations, and the importance of standards in data exchange. Discover the evolution of microarray data sharing through meetings like MGED and the founding of the MGED Society with its standards like MIAME. Explore the checklist for authors and reviewers under MIAME to ensure proper data representation.

E N D
Establishing the infrastructurefor sharing microarray data Alvis Brazma European Bioinformatics Institute EMBL-EBI Microarray Gene Expression Data Society
Outline • Establishing the infrastructure for sharing microarray data – MGED, MIAME, MAGE-ML, databases • Microarray Informatics at the EBI
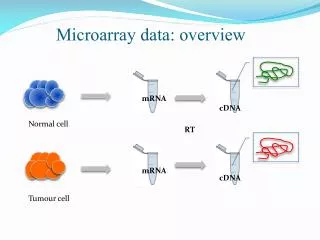
Microarrays - a tool for the golden age of genome discoveries
Some questions for the golden age of genomics • How gene expression differs in different cell types? • How gene expression changes when the organism develops and cells are differentiating? • How gene expression differs in a normal and diseased (e.g., cancerous) cell? • How gene expression changes when a cell is treated by a drug? • How gene expression is regulated – which genes regulate which and how?
Potential amounts of microarray data • Experiments: ~ 30 000 genes in a human genome ~ 320 cell types in a human organism • 2000 compounds for screening • 2 concentrations • 3 time points • 5 replicates • Data ~ 1012 data-points 1 Tera Byte
Making microarray data available to the public • Authors web-sites • Local, lab based public databases (Stanford University, Whitehead,…) • Journal web-sites • There is a wide community consensus that there is a need for public repositories for microarray data, analogous to DDBJ/EMBL/Genbank for sequence data
Quantitation matrices Gene expression data matrix Raw data Array scans Quantitations Samples Spots Genes Gene expression levels Which data to share?
Sample annotations problem 1 Gene expression levels – problem 2 Gene annotations Annotations Samples Gene expression matrix Genes
source Sample Design treatment protocols RNA extract elements (spots) labelled nucleic acid array image quantitation matrix hybridisation Sample annotation Gene annotation
Sample Sample Sample Sample Sample Design Design Design Design Design RNA extract RNA extract RNA extract RNA extract RNA extract elements (spots) elements (spots) elements (spots) elements (spots) elements (spots) labelled nucleic acid labelled nucleic acid labelled nucleic acid labelled nucleic acid labelled nucleic acid hybridisation hybridisation hybridisation hybridisation hybridisation array array array array array Gene expression data matrix transformation integration Experiment Gene expression measurements
Problem 4 • The nature and structure of the above described gene expression data and annotations are complex • For the public repositories to make the maximum use out of these data, standards for representing and communicating it should be established
Standards for microarray data • Understanding and agreement what data and annotations should be provided • Standard controlled vocabularies (ontologies) that can be used in such annotations • Standard format for exchange of annotated data • Understanding how to compare different datasets
Microarray Gene Expression Database meeting was organised in Cambridge, UK, November 1999 to discuss these problems
Affymetrix DDBJ DKFZ EMBL Gene Logic Incyte Max Plank Institute NCGR NHGRI Sanger Centre Stanford University Uni Pennsylvania Uni Washington, Seattle Whitehead Institute MGED 1 – some participants
MGED working groups • Experiment annotation • Data exchange format and modelling • Ontologies • Data normalisation and transformations • Queries
MGED meetings MGED 2, Heidelberg, May 2000 MGED 3, Stanford University, April 2001 MGED 4, Boston, February 2002 MGED 5, Tokyo, September 2002
MGED Society was founded in June 2002 Microarray Gene Expression Data (MGED) society is an international organisation for facilitating sharing of functional genomics and proteomics array data Board of 17 directors www.mged.org
MGED standards • Annotation content – MIAME • Data representation and exchange format MAGE-OM (MAGE-ML) – jointly with OMG
MIAME – Minimum Information About a Microarray experiment An attempt to outline the minimum information required to interpret unambiguously and potentially reproduce and verify an array based gene expression experiment www.mged.org/miame
Sample Sample Sample Sample Sample Design Design Design Design Design RNA extract RNA extract RNA extract RNA extract RNA extract elements (spots) elements (spots) elements (spots) elements (spots) elements (spots) labelled nucleic acid labelled nucleic acid labelled nucleic acid labelled nucleic acid labelled nucleic acid hybridisation hybridisation hybridisation hybridisation hybridisation array array array array array Gene expression data matrix normalization integration Experiment MIAME – the content (annotation) of all boxes and lines should be given
MIAME ‘checklist’ to authors and reviewers • Experimental design • Samples used, RNE extraction and labelling • Hybridisation • Measurement data and specifications • Array Design • (Row images) • Image quantitation (data and specification) • Gene expression data matrix (data and transformations)
MIAME ‘checklist’ • An open letter was sent to the journals last week - all the information in MIAME ‘checklist’ should be made available as a requirement for accepting publications • The Lancet has indicated that it will adopt MIAME checklist as a requirement • Nature will adjust its policy in the line with MIAME recommendations
A need for a supporting infrastructure • MIAME itself will not solve the problem • A standard format is needed for representing and exchanging this information
MGED standards 2 • Data exchange format – MicroArray Gene Expression Mark-up language – MAGE-ML – an XML based file format able to capture all MIAME required information • Based on object model MAGE-OM (Paul Spellman, Michael Miller, Jason Stewart, Ugis Sarkans, …) • Adopted by OMG as a standard for microarrays www.mged.org/mage
BioEvent Protocol Treatment HigherLevelAnalysis Transformation Experiment BioMaterial BioAssayData BioAssay Description QuantitationType Array BQS DesignElement ArrayDesign Measurement AuditAndSecurity BioSequence UML Packages of MAGE
Use case of MAGE:ArrayExpress architecture MAGE-OM MAGE-ML (DTD) ArrayExpress (Oracle) data loader Tomcat object/ relational mapping Castor MAGE-ML (doc) MAGE-ML (doc) Java servlets MAGE-ML (doc) Velocity template engine MIAMEexpress Web page template Web page template Browser
MGED standards 3 • MGED ontologies – organism part, cell type, diseased state, genotype, chemical compounds (Chris Stoeckert, Helen Parkinson, Susanna Sansone,…) • Symposium “Standards and Ontologies for Functional Genomics” – November 17-20, Cambridge, UK www.mged.org/ontology
MGED standards 4 • Data transformation and normalisation (Cathy Ball, John Quackenbush, Gavin Sherlock, …) www.mged.org/normalization
Infrastructure for sharing microarray data • Standard for experiment annotation • Standard for data exchange • Public repositories • Local databases and LIMS • Ways of comparing the data
ArrayExpress – a MIAME/MAGE supportive public repository for microarray data at EBI ArrayExpress MAGE-ML MAGE-ML MIAMExpress Expression Profiler Internet Submissions Queries, Analysis www
Public repositories MAGE-ML Microarray data sharing infrastructure Data submissions Data queries, retrieval, and analysis www Array descriptions (from manufacturers) www Data analysis software LIMS MAGE-ML MAGE-ML LIMS Data analysis software MIAMExpress local instalations MAGE-ML www Other databases www html www html
MIAME/MAGE supportive software • Sanger Institute LIMS (MIDAS) • TIGR LIMS • Gene Traffic (Iobion) • Affymetrix • MAXDB (Manchester) • Rosetta Resolver (Rosetta Biosoftware) • Base (Lund) • J-Express (Molmine) • MIAMExpress (EBI) • ArrayExpress (EBI)
Acknowledgements • MGED supporters • Rob Andrews (Sanger) • Wilhelm Ansorge (EMBL) • Mike Cherry (Stanford) • Peter Dansky (Affymetrix) • David Hancock (Manchester) • Frank Holstege (Utrecht) • Michael Miller (Rosetta) • Kate Rice (Sanger) • Christian Schwager (EMBL) • Joe White (TIGR) • Rick Young (MIT) • EBI Microarry Team • Niran Abeygunawardena • Helen Parkinson • Philippe Rocca-Sera • Susanna Sansone • Ugis Sarkans • Mohammadreza Shojatalob • Jaak Vilo • MGED board • Cathy Ball (Stanford) • Helen Causton (Imperial Col) • Terry Gaasterland (Rockefel) • Jason Gonzales (Iobion) • Pascal Hingamp (Marseille) • Barbara Jasny (Science) • Helen Parkinson (EBI) • John Quackenbush (TIGR) • Martin Ringwald (Jackson) • Gavin Sherlock (Stanford) • Paul Spellman (Berkely) • Jason Stewart (Open Inf) • Chris Stoeckert (Uni Penns) • Yoshio Tateno (DDBJ) • Ron Taylor (Colorado) • Charles Troup (Agilent)
Microarray informatics at the EBI • ArrayExpress (Helen Parkinson) • Expression profiler data analysis tool and promoter analysis (Jaak Vilo) • Reconstructing and analysing gene networks
Gene Networks – graphs: nodes are genes, arcs are relationships
- The product of gene G1 is a transcription factor, which binds to the promoter of gene G2 – physical interaction network G1 G2 - The disruption of gene G1 changes the expression level of gene G2 – data interpretation network G1 G2 - Gene G2 is mentioned in a paper about gene G1 – literature networks G1 G2 Different ways to build a gene network
Data for over 200 gene disruptions in Yeast Hughes et al, Cell, 102 (2000)
Discretization of the data: The normalized expression log(ratios) are discretized using different thresholds = 2, 2.1 , … , 4 : X < d(X) = 1 X d(X) = 0 X > d(X) = 1
DA DC DB C A gene A gene B gene C B D gene D Gene disruption network
Data for over 200 gene disruptions in Yeast Hughes et al, Cell, 102 (2000)
Mutation network Dg=2, filtered for the genes marked in red (mating) Thomas Schlitt, Johan Rung
Comparison to literature network derived from YPD Result Overlap between calculated networks and YPD-graph is always larger than overlap between randomised networks and the YPD-graph
Network modularity • Is there one “big” dominant connected component and possibly a number of small components, or several components of comparable sizes? • Can the network be broken down in several components of comparable size by removing nodes of high degree (i.e., nodes with many incoming or outgoing edges)?