Download

1 / 18
180 likes | 441 Views
Architettura delle GPU e Pipeline di Rendering. Prof. Roberto Pirrone. Sommario. Pipeline di rendering Cenni storici sui controllori grafici Implementazione della pipeline di rendering Pipeline logica programmabile Pipeline mappata sul processore Architetture dei sistemi GPU

E N D
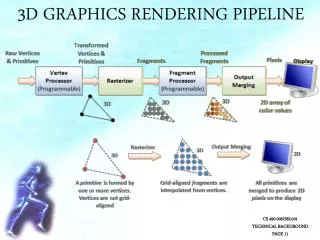
Architettura delle GPU e Pipeline di Rendering Prof. Roberto Pirrone
Sommario • Pipeline di rendering • Cenni storici sui controllori grafici • Implementazione della pipeline di rendering • Pipeline logica programmabile • Pipeline mappata sul processore • Architetture dei sistemi GPU • Cenni alla programmazione delle GPU
Cenni storici sui controllori grafici • Video and Graphics Array controller - VGA (<1990) • Controllore di una memoria DRAM chiamata framebuffere generatore di segnali (RAMDAC) collegato direttamente al video • Basato sul principio della grafica vettoriale • Implementa l’aritmetica intera indicizzata • 1990 – 1997 circa • Si aggiungono funzioni al controllore VGA • Gestione triangoli • Rasterizzazione triangoli • Shading
Cenni storici sui controllori grafici • Anni 2000 • Chip integrato che incorpora praticamente tutti gli elementi di una pipeline di rendering • Nasce la Graphics Processing Unit (GPU) • > 2005 • GPU con implementazione dell’aritmetica in virgola fissa e mobile • GPU programmabili • API di alto livello (OpenGL, Direct3D) • shadersdelle geometrie, dei vertici e dei pixel
Cenni storici sui controllori grafici Variante: Architettura UMA (Unified Memory Architecture) CPU e GPU condividono la stessa DDR2 RAM
Architettura GPU Unificata di base • Adesso (>2008 circa) • Da luogo a differenti implementazioni tutte compatibili “verso l’alto” • I processori sono massicciamente paralleli e multithread • Streaming Processors (SP) a flusso continuo • Gli SP sono organizzati in Streaming Multiprocessors(SM) • La memoria è condivisa due livelli • Dentro lo SM tra gli SP • Tramite rete di interconnessione tra gli SM • Soluzione scalabile
Pipeline mappata su schiera di processori • Adesso (>2008 circa) • L’esecuzione degli shaders viene mappata sulla “schiera di processori unificati”
Architettura di una GPU unificata Arch. TESLA 112 SP 14 SM 1 SP 96 thread DRAM 64 bit NVIDIA GeForce 8800
Programmazione Grafica • Tre livelli • API grafiche • OpenGL • Direct3D • Linguaggi di shading • GLSL • HLSL • Cg • API di programmazione diretta dei core SP • CUDA • OpenCL
API grafiche • Sono API di alto livello che definiscono logicamente la pipeline di rendering • L’applicazione si sviluppa definendo i vari stadi con primitive di alto livello • I dettagli sono nascosti allo sviluppatore e gestiti dalle API
Linguaggi di shading • Gestiscono i tre tipi di shader • Shader dei vertici • Mappano la posizione dei vertici dei triangoli nello schermo, modificando posizione, colore e orientamento • Shader delle geometrie • Lavorano sulla base di primitive geometriche (ad es. interi triangoli) definite come insiemi di vertici; le modificano ovvero ne aggiungono di nuove • Shader dei pixel (o dei frammenti) • Dipingono il pixel sullo schermo e gestiscono gli artefatti visivi
Linguaggi di shading Gli shader sono programmati a “a flusso continuo” cioè su sequenze ininterrotte di dati; l’I/O è implicito Le strutture di dati su cui operano consentono un elevato parallelismo e quindi possono essere lanciati più thread dello stesso shader Hanno primitive per operazioni trigonometriche e su matrice, interpolazione, filtraggio …
Linguaggi di shading Shader Cg per environmentmapping
Programmazione dei core SP • Sono API per programmazione general purpose su GPU • GPGPU: General Purposecomputing on GPU • Il problema viene parallelizzato mappandolo sull’architettura • Il programmatore CUDA scrive una procedura detta kernel che istanzia tante esecuzioni di thread paralleli
Programmazione CUDA I thread sono organizzati gerarchicamente in blocchi1D, 2D o 3D i quali sono organizzati in griglie 1D, 2D o 3D Il mapping dipende dai core SP disponibili ed è scelto dal programmatore
Programmazione CUDA Calcola n valori in parallelo con nthread organizzati in blocchi da 256 thread ciascuno