Download

1 / 48
480 likes | 495 Views
This framework addresses challenges in managing and extracting valuable information from vast amounts of data generated by petascale simulations, optimizing workflow automation and fast I/O. It integrates technologies for scalable I/O workflows, analysis, visualization, and data management. The framework abstracts the API from I/O implementation, offers easy-to-use, scalable architecture, metadata-rich output, and provenance tracking. It provides a simple API similar to standard Fortran or C calls, with external XML configuration for metadata and I/O control settings. The design goals focus on efficiency for multiple platforms without changing source code, utilizing existing IO techniques. Architecture includes data groupings and flexible IO methods selection for optimized performance.

E N D
End to End Scientific Data Management Framework for Petascale Science ESMF 9/23/2008 Scott Klasky, Jay Lofstead, Mladen Vouk ORNL, Georgia Tech, NCSU
Outline • EFFIS (Klasky) • ADIOS. • ADIOS Overview (Klasky) • ADIOS Advanced Topics (Lofstead) • Workflow. (Vouk) • Dashboard. (Vouk) • Conclusions. (Klasky)
Supercomputers creating a hurricane of data. • Some simulations are starting to produce 100TB/day on the 270 TF Cray XT at ORNL. • Old way of run now, and look at results later has problems. • Data will be eventually archived on tape. • Lots of files from 1 run with multiple users gives us a data management headache. • Need to keep track of data over multiple system. • Extracting information from files needs to be easy. • Example: min/max of 100GB arrays needs to be almost instant.
Vision • Problem: Managing the data from a petascale simulation, and debugging the simulation, and extracting the science involves. • Tracking the codes: Simulation, Analysis. • Tracking the input files/parameters • Tracking the output files, from the simulation and then analysis programs. • Tracking the machines and environment the codes ran on. • Gluing everything together. • Visualizing the results, and analyzing the results without requiring users to know all of the file names. • Fast I/O which can be easily tracked.
Vision • Workflow Automation to automate all of the mundane tasks. • Analyzing the results, without knowing all of the file locations/names. • Moving data from the simulation side to remote locations without knowledge of filename(s)/locations. • Monitoring results in real-time, • Requirements. • Want technologies integrated together; easy to talk to one another. • Want to make the system scalable in the I/O workflow, analysis, visualization, data management.
Outline • EFFIS • ADIOS. • ADIOS Overview • BP format, and compatibility with hdf5/netcdf. • Workflow. • Dashboard. • Conclusions.
ADIOS: Motivation • “Those fine fort.* files!” • Multiple HPC architectures • BlueGene, Cray, IB-based clusters • Multiple Parallel Filesystems • Lustre, PVFS2, GPFS, Panasas, PNFS • Many different APIs • MPI-IO, POSIX, HDF5, netCDF • GTC (fusion) has changed IO routines 8 times so far based on performance when moving to different platforms. • Different IO patterns • Restarts, analysis, diagnostics • Different combinations provide different levels of IO performance • Compensate for inefficiencies in the current IO infrastructures to improve overall performance
ADIOS Overview Scientific Codes • Allows plug-ins for different I/O implementations. • Abstracts the API from the method used for I/O. • Simple API, almost as easy as F90 write statement. • Best practices/optimize IO routines for all supported transports “for free” • Componentization. • Thin API • XML file • data groupings with annotation • IO method selection • buffer sizes • Common tools • Buffering • Scheduling • Pluggable IO routines External Metadata (XML file) ADIOS API buffering schedule feedback pHDF-5 MPI-IO MPI-CIO pnetCDF POSIX IO Viz Engines LIVE/DataTap Others (plug-in)
ADIOS Overview • ADIOS is an IO componentization, which allows us to • Abstract the API from the IO implementation. • Switch from synchronous to asynchronous IO at runtime. • Change from real-time visualization to fast IO at runtime. • Combines. • Fast I/O routines. • Easy to use. • Scalable architecture(100s cores) millions of procs. • QoS. • Metadata rich output. • Visualization applied during simulations. • Analysis, compression techniques applied during simulations. • Provenance tracking.
ADIOS Philosophy (End User) • Simple API very similar to standard Fortran or C POSIX IO calls. • As close to identical as possible for C and Fortran API • open, read/write, close is the core • set_path, end_iteration, begin/end_computation, init/finalize are the auxiliaries • No changes in the API for different transport methods. • Metadata and configuration defined in an external XML file parsed once on startup. • Describe the various IO grouping including attributes and hierarchical path structures for elements as an adios-group • Define the transport method used for each adios-group and give parameters for communication/writing/reading • Change on a per element basis what is written • Change on a per adios-group basis how the IO is handled
Design Goals • ADIOS Fortran and C based API almost as simple as standard POSIX IO • External configuration to describe metadata and control IO settings • Take advantage of existing IO techniques (no new native IO methods) Fast, simple-to-write, efficient IO for multiple platforms without changing the source code
Architecture • Data groupings • logical groups of related items written at the same time. • Not necessarily one group per writing event • IO Methods • Choose what works best for each grouping • Vetted, improved, and/or written by experts for each • POSIX (Wei-keng Liao, Northwestern) • MPI-IO (Steve Hodson, ORNL) • MPI-IO Collective (Wei-keng Liao, Northwestern) • NULL (Jay Lofstead, GT) • Ga Tech DataTap Asynchronous (HasanAbbasi, GT) • phdf5 • others.. (pnetcdf on the way).
Related Work • Specialty APIs • HDF-5 – complex API • Parallel netCDF – no structure • File system aware middleware • MPI ADIO layer – File system connection, complex API • Parallel File systems • Lustre – Metadata server issues • PVFS2 – client complexity • LWFS – client complexity • GPFS, pNFS, Panasas – may have other issues
Supported Features • Platforms tested • Cray CNL (ORNL Jaguar) • Cray Catamount (SNL Redstorm) • Linux Infiniband/Gigabit (ORNL Ewok) • BlueGene P now being tested/debugged. • Looking for future OSX support. • Native IO Methods • MPI-IO independent, MPI-IO collective, POSIX, NULL, Ga Tech DataTap asynchronous, Rutgers DART asynchronous, Posix-NxM, phdf5, pnetcdf, kepler-db
Initial ADIOS performance. • MPI-IO method. • GTC and GTS codes have achieved over 20 GB/sec on Cray XT at ORNL. • 30GB diagnostic files every 3 minutes, 1.2 TB restart files every 30 minutes, 300MB other diagnostic files every 3 minutes. • DART: <2% overhead forwriting 2 TB/hour withXGC code. • DataTap vs. Posix • 1 file per process (Posix). • 5 secs for GTCcomputation. • ~25 seconds for Posix IO • ~4 seconds with DataTap
Codes & Performance • June 7, 2008: 24 hour GTC run on Jaguar at ORNL • 93% of machine (28,672 cores) • MPI-OpenMP mixed model on quad-core nodes (7168 MPI procs) • three interruptions total (simple node failure) with 2 10+ hour runs • Wrote 65 TB of data at >20 GB/sec (25 TB for post analysis) • IO overhead ~3% of wall clock time. • Mixed IO methods of synchronous MPI-IO and POSIX IO configured in the XML file
Chimera IO Performance (Supernova code) 2x scaling • Plot minimum value from 5 runs with 9 restarts/run • Error bars show maximum time for the method.
Chimera Benchmark Results • Why ADIOS is better than pHDF5? ADIOS_MPI_IO vs. pHDF5 w/ MPI Indep. IO driver Use 512 cores, 5 restart dumps. Conversion time on 1 processor for the 2048 core job = 3.6s (read) + 5.6s (write) + 6.9 (other) = 18.8 s Number above are sum among all PEs (parallelism not shown)
ADIOS Advanced Topics • J. Lofstead
ADIOS API Fortan Example Fortan90 code: ! initialize the system loading the configuration file adios_init (“config.xml”, err) ! open a write path for that type adios_open (h1, “output”, “restart.n1”, “w”, err) adios_group_size (h1, size, total_size, comm, err) ! write the data items adios_write (h1, “g_NX”, 1000, err) adios_write (h1, “g_NY”, 800, err) adios_write (h1, “lo_x”, x_offset, err) adios_write (h1, “lo_y”, y_offset, err) adios_write (h1, “l_NX”, x_size, err) adios_write (h1, “l_NY”, y_size, err) adios_write (h1, “temperature”, u, err) ! commit the writes for asynchronous transmission adios_close (h1, err) … ! do more work ! shutdown the system at the end of my run adios_finalize (mype, err) XML configuration file: <adios-config> <adios-group name=“output” coordination-communicator=“group_comm”> <var name=“group_comm” type=“integer”/> <var name=“g_NX” type=“integer” /> <var name=“g_NY” type=“integer”/> <var name=“lo_x” type=“integer”/> <var name=“lo_y” type=“integer”/> <var name=“l_NX” type=“integer”/> <var name=“l_NY” type=“integer”/> <global-bounds dimensions=“g_NX,g_NY” offsets=“lo_x,lo_y”> <var name=“temperature” dimensions=“l_NX,l_NY”/> </global-bounds> <attribute name=“units” path=“/temperature” value=“K”/> </adios-group> … <!-- declare additional adios-groups --> <method method=“MPI” group=“output”/> <!-- add more methods --> <buffer size-MB=“100” allocate-time=“now”/> </adios-config>
ADIOS API C Example C code: // parse the XML file and determine buffer sizes adios_init (“config.xml”); // open and write the retrieved type adios_open (&h1, “restart”, “restart.n1”, “w”); adios_group_size (h1, size, &total_size, comm); adios_write (h1, “n”, n); // int n; adios_write (h1, “mi”, mi); // int mi; adios_write (h1, “zion”, zion); // float zion [10][20][30][40]; // write more variables ... // commit the writes for synchronous transmission or // generally initiate the write for asynchronous transmission adios_close (h1); // do more work ... // shutdown the system at the end of my run adios_finalize (mype); XML configuration file: <adios-config host-language=“C”> <adios-group name=“restart”> <var name=“n” path=“/” type=“integer” /> <var name=“mi” path=“/param” type=“integer”/> … <!-- declare more data elements --> <var name=“zion” type=“real” dimensions=“n,4,2,mi”/> <attribute name=“units” path=“/param” value=“m/s”/> </adios-group> … <!-- declare additional adios-groups --> <method method=“MPI” group=“restart”/> <method priority=“2” method=“DATATAP” iterations=“1” type=“diagnosis”>srv=ewok001.ccs.ornl.gov</method> <!-- add more methods --> <buffer size-MB=“100” allocate-time=“now”/> </adios-config>
BP File Format • netCDF and HDF-5 are excellent, mature file formats • APIs can have trouble scaling to petascale and beyond • metadata operations bottleneck at MDS • coordination among all processes takes time • MPI Collective writes/reads add additional coordination • Non-stripe-sized writes impact performance • Read/write mode is slower than write only • Replicate some metadata for resilience
BP File Format • Solution: Use an intermediate API and format • ADIOS API and BP format • API natively writes BP format (netCDF coming) • converters to netCDF and HDF-5 available • Convert files at speeds limited by the performance of disk and the netCDF/HDF-5 API
BP File Format • File organization • Move the “header” to the end • last 28 bytes are 3 index locations and version + endian-ness flag • Each process writes completely independently • First part of file a series of “Process Groups”, each the output from a single process for a single IO grouping • Coordinate only twice • Once at start for writing location • Once at end for metadata collection to process 0 and writing by process 0 only • Replicate some metadata • Each “Process Group” is fully self-contained with all related meta-data • Indexes contain copies of “highlights” of the metadata
BP File Format • Index Structure • Process Group Index • ADIOS group, process ID, timestep, offset in file • Vars Index • Set of unique vars listing group, name, path, datatype, characteristics (see next slide) • Uniqueness based on group name, var name, var path • Attributes Index • Set of unique attributes listing group, name, path, datatype, characteristics (see next slide) • Uniqueness based on group name, attribute name, attribute path
BP File Format • Data Characteristics • Idea: collect information about the var/attribute for quickly characterizing the data • Examples: • Offset in file • Value (only for “small” data) • Minimum • Maximum • Instance array dimensions • Structure setup for adding more without changing file format
BP File Format • Write operation (n processes) • Gather data sizes to process 0 • Process 0 generates offset to write for each process • Scatter offsets back to processes • Everybody write data independently • Gather the local index from each process to process 0 • Merge all indices together • Process 0 write indices at the end of the file
BP File Format • Compromises using BP Format • Each “Process Group” can have different variables defined and written (also an advantage)
BP File Format • Advantages using BP Format • Each process writes independently • Limited coordination • File organization more natural for striping • Rich index contents • “Append” operations do not require moving data • Indices read by process 0 on start and used as base index • First new Process Group overwrites old indicies • Index corruption does not potentially destroy entire file • Process Group corruption isolated by still getting access to the rest of the process groups (via indices)
Outline • EFFIS • ADIOS. • ADIOS Overview • BP format, and compatibility with hdf5/netcdf. • Workflow. • Dashboard. • Conclusions.
Scientific Workflow Capture how a scientist works with data and analytical tools • data access, transformation, analysis, visualization • possible worldview: dataflow-oriented (cf. signal-processing) Scientific workflows start where script-based data-management solutions leave off. Scientific workflow (wf) benefits (v.s. script-based approaches): • wf automation • wf & component reuse, sharing, adaptation, archiving • wf design, documentation • built-in (model) concurrency (task-, pipeline-parallelism) • built-in provenance support • distributed ¶llel exec: Grid & cluster support • wf fault-tolerance, reliability • Other … Why a W/F System? Higher-level “language” vs. assembly-language nature of scripts
Two typical types of Workflows for SC • Real-time Monitoring (Server Side Workflows) • Job submission. • File movement. • Launch Analysis Services. • Launch Visualization Services. • Launch Automatic Archiving. • Post Processing (Desktop Workflows). • Read in Files from different locations. • File movement. • Launch Analysis Services. • Launch Visualization Services. • Connect to Databases. • Obviously there are other types of workflows. • Parameter study/sensitivity analysis workflows.
Workflow + Provenance • Process provenance. • the steps performed in the workflow, the progress through the workflow control flow, etc. • Data provenance. • history and lineage of each data item associated with the actual simulation (inputs, outputs, intermediate states, etc.); • Workflow provenance. • history of the workflow evolution and structure; • System provenance. • All external (environment) information relevant to a complete run. • Compilation history of the codes. • Information about the libraries. • Source of the codes. • Run-time environment settings. • Machine information • etc. • Dashboard displays provenance information for • Data lineage. • Source Code for a simulation, analysis. • Performance Data from PAPI. • Workflow Provenance to determine if something went wrong with the workflow. • Other …
Modular Framework Auth Storage Supercomputers + Analytics Nodes Kepler Data Store Rec API Disp API Dash Management API Orchestration Meta-Data about: Processes, Data, Workflows, System, Apps & Environment • ADIOS is being modified • to send the IO (+ coupling) • metadata to Kepler • (e.g., file path, variables, • control commands, …)
So what are the requirements? • Reliability (autonomics) • Usability (Must be EASY to use and functional) • Good user support, and long-term DOE support. • Universality and Reuse - The workflow should work for all of my workflows. (NOT just for the Petascale computers; multiple platforms) • Integration - Must be easy to incorporate my own services into the workflow. • Customization and adaptability - Must be customizable by the users. • Users need to easily change the workflow to work with the way users work. • Other - You tell us!
Kepler Scientific Workflow System Kepler is a cross-project collaboration Latest release available from the website Builds upon the open-source Ptolemy II framework Vergil is the GUI, but Kepler also runs in non-GUI and batch modes. Ptolemy II: A laboratory for investigating design KEPLER: A problem-solving support environment for Scientific Workflow development, execution, maintenance KEPLER = “Ptolemy II + X” for Scientific Workflows http://www.kepler-project.org
Vergil is the GUI for Kepler… … but Kepler can also run in batch mode as a command-line engine. Data Search Actor Search • Actor ontology and semantic search for actors • Search -> Drag and drop -> Link via ports • Metadata-based search for datasets
Actor-Oriented Modeling Ports each actor has a set of input and output ports denote the actor’s signature produce/consume data (a.k.a. tokens) parameters are special “static” ports Actors • single component or task • well-defined interface (signature) • generally a passive entity: given input data, produces output data
Actor-Oriented Modeling Dataflow Connections actor “communication” channels Directed edges connect output ports with input ports
Actor-Oriented Modeling Sub-workflows / Composite Actors composite actors “wrap” sub-workflows like actors, have signatures (i/o ports of sub-workflow) hierarchical workflows (arbitrary nesting levels)
Actor-Oriented Modeling Directors define the execution semantics of workflow graphs executes workflow graph (some schedule) sub-workflows may have different directors enables reusability
Some Directors • Directed Acyclic Graph (DAG) • Common among Grid workflows: no loops, each actor fires at most once (no streaming / pipeline parallelism) • Example: DAGMan • Synchronous Dataflow (SDF) • Connections have queues for sending/receiving fixed numbers of tokens at each firing. Schedule is statically predetermined. SDF models are highly analyzable and used often in SWFs. • Process Networks (PN) • Generalize SDF. Actors execute as a separate thread/process, with queues of unbounded size. Related to Kahn/MacQueen semantics. The workflow is executed in parallel and pipeline parallel fashion. • Continuous Time (CT) • Connections represent the value of a continuous time signal at some point in time ... Often used to model physical processes. • Discrete Event (DE) • Actors communicate through a queue of events in time. Used for instantaneous reactions in physical systems. • Dynamic Dataflow (DDF) • Connections have queues for sending/receiving arbitrary numbers of tokens at each firing. Schedule is dynamically calculated. DDF models enable branching and looping/ (conditionals). The workflow is sequential. • …
Types • tokens, ports have types • available types • int, float (double precision), complex, string, boolean, object • array, record, matrix (2D only) • type resolution at workflow start-up actors can support different types • e.g. Count, Sleep, Delay work on any type • a type lattice is pre-defined to determine relationships among types (casting) string and int tokens are added as strings int tokens are added as ints
Machine monitoring. • Allow for secure logins with OTP. • Allow for job submission. • Allow for killing jobs. • Search old jobs. • See collaborators jobs.
Analysis Collaborative Features • Base analysis which will workon both the portable dashboard and the “mother-dashboard” and will feature. • Calculator for simple math, done inpython. • Hooks into “R” for pre-set functions. • Ability to save the analysis into anew function, available to otherusers. • Calculator will create new movies that are viewable on the dashboard. • First version will work with xy +(t) plots. • Second version will work with x,y,z + (t)plots. • Advanced analysis will contain. • Parallel backend to VisIT server, VisTrails, Parallel R, and custom mpi/c/f90 code. • We will allow users to place executable code into the dashboard. (Still working this out). How to execute, ….
Conclusions • ADIOS is an IO componentization. • ADIOS is being integrated integrated into Kepler. • Achieved over 20 GB/sec for several codes on Jaguar. • Used daily by CPES researchers. • Can change IO implementations at runtime. • Metadata is contained in XML file. • Kepler is used daily for • Monitoring CPES simulations on Jaguar/Franklin/ewok. • Runs with 24 hour jobs, on large number of processors. • Dashboard uses enterprise (LAMP) technology. • Linux, Apache, MySQL, PHP
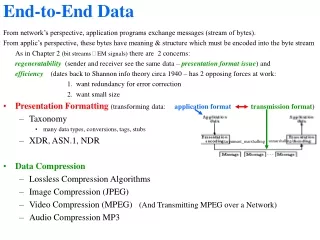
Dashboard Visualization Wide-area Data Movement Workflow Code Coupling Provenance and Metadata Adaptable I/O EFFIS • From SDM center* • Workflow engine – Kepler • Provenance support • Wide-area data movement • From universities • Code coupling (Rutgers) • Visualization (Rutgers) • Newly developed technologies • Adaptable I/O (ADIOS)(with Georgia Tech) • Dashboard (with SDM center) Foundation Technologies Enabling Technologies Approach: place highly annotated, fast, easy-to-use I/O methods in the code, which can be monitored and controlled, have a workflow engine record all of the information, visualize this on a dashboard, move desired data to user’s site, and have everything reported to a database.