Download

1 / 47
470 likes | 487 Views
Learn about replication strategies like primary-backup protocol, passive and active replication, and replica coordination for system reliability and availability. Explore consistency models for data-centric client communication.

E N D
Replication • Improves reliability • Improves availability (What good is a reliable system if it is not available?) • Replication must be transparent and create the illusion of a single copy.
Updating replicated data shared Separate replicas F F’ F’’ Alice Bob Alice Bob Update and consistency are primary issues.
Each client communicates with one replica called the primary server Each client maintains a variable L (leader) that specifies the replica to which it will send requests. Requests are queued at the primary server. Backup servers ignore client requests. Passive replication 4 L=3 1 3 L=3 primary 2 clients backup
Receive. Receive the request from the client and update the state if appropriate. Broadcast. Broadcast an update of the state to all other replicas. Reply. Send a response to the client. Primary-backup protocol client req reply primary update backup
If the client fails to get a response due to the crash of the primary, then the request is retransmitted until a backup is promoted as the primary. {The switch should ideally be Instantaneous, but practically it is not so} Failover time is the duration when there is no primary server. Primary-backup protocol New primary elected client req reply primary update heartbeat ? backup election
Each server receives client requests, and broadcasts them to the other servers. They collectively implement a fault-tolerant state machine. In presence of crash, all the correct processes reach the same next state. Active replication input Next state State
Fault-tolerant state machine This formalism is based on a survey by Fred Schneider. The clients must receive correct responseeven if up to m replica servers fail(either fail-stop or byzantine). For fail-stop, ≥ (m+1) replicas are needed. If a client queries the replicas, the first one that responds gives a correct value. For byzantine failure ≥ (2m+1) replicas are needed. m bad responses can be voted out by the (m+1) good responses. But the states of the good processes must be correctly Updated (byzantine consensus is needed) Fault intolerant Fault tolerant
Replica coordination Agreement. Every correct replica receives all the requests. Order. Every correct replica receives the requests in the same order. Agreement part is solved by atomic multicast. Order part is solved by total order multicast. The order part solves the consensus problem where servers will agree about the next update. It requires a synchronous model. Why? server client
Agreement client With fail-stop processors, the agreement part is solved by reliable atomic multicast. To deal with byzantine failures, an interactive consistency protocol needs to be implemented. Thus, with an oral message protocol, n ≥ 3m+1 processors will be required. server
Order client Let timestamps determine the message order. A request is stable at a server, when the it does not expect to receive any other client request with a lower timestamp. Assume three clients are trying to send an update, the channels are FIFO, and their timestamps are 20, 30, 42. Each server will first update its copy with the value that has the timestamp 20. 30 20 server 42
Order But some clients may not have any update. How long should the server wait? Require clients to send null messages (as heartbeat signals) with some timestamp ts. A message (null, 35) means that the client will not send any update till ts=35. These can be part of periodic heartbeat messages. An alternative is to use virtual time, where processes are able to undo actions. client 30 null 35 server 42
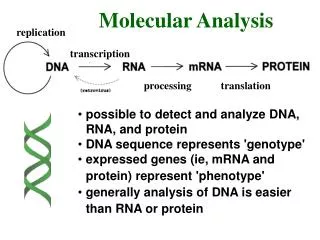
What is replica consistency? replica clients Consistency models define a contract between the data manager and the clients regarding the responses to read and write operations.
Replica Consistency • Data Centric Client communicates with the same replica • Client centric Client communicates with different replica at different times. This may be the case with mobile clients.
Data-centric Consistency Models 1. Strict consistency 2. Linearizability 3. Sequential consistency • Causal consistency • Eventual consistency (as in DNS) • Weak consistency There are many other models
Strict consistency Strict consistency corresponds to true replication transparency. If one of the processes executes x:= 5 at real time t and this is the latest write operation, then at a real time t’ > t, every process trying to read x will receive the value 5. Too strict! Why? W(x:=5) p1 R(x=5) p2 t t’ {Assume the read or write operations are non-blocking}
Sequential consistency Some interleaving of the local temporal order of events at the different replicas is a consistent trace. W(x:=100) W(x:=99] R(x=100) R(x=99)
Sequential consistency Is sequential consistency satisfied here? Initially x = y = 0 W(x:=10) W(x:=8] R(x:=10) W(x=20) R(x=20) R(x=10)
Causal consistency All writes that are causally related must be seen by every process in the same order. W(x:=10) W(x:=20) R(x=10) R(x=20) R(x=10) R(x=20)
Linearizability Linearizability is a correctness criterion for concurrent object (Herlihy & Wing ACM TOPLAS 1990). It provides the illusion that each operation on the object takes effect in zero time, and the results are “equivalent to” some legal sequential computation.
Linearizability A trace is in a read-write system is consistent, when every read returns the latest value written into the shared variable preceding that read operation. A trace is linearizable, when (1) it is consistent, and (2) the temporal ordering among the reads and writes is respected (may be based on real time or logical time). W (x:=0) R (x=1) W (x:=0) ts=10 ts=21 ts=27 R(x=1) W (x:=1) (Initially x=y=0) ts=19 ts=38 Linearizability is stronger than sequential consistency, i.e. every linearizable object is also sequentially consistent. Is it a linearizable trace?
Exercise What consistency model is satisfied by the above?
Implementing consistency models Why are there so many consistency models? Each model has a use in some type of application. The cost of implementation (as measured by message complexity) decreases as the models become “weaker”.
Implementing linearizability W (x:=20) Read x W(x:=10) Read x Needs total order multicast of all reads and writes
Implementing linearizability • The total order multicast forces every process to accept and handle all reads and writes in the same temporal order. • The peers update their copies in response to a write, but only send acknowledgments for reads.After all updates and acknowledgments are received, the local copy is returned to the client.
Implementing sequential consistency Use total order broadcast all writes only, but for reads, immediately return local copies.
Eventual consistency Only guarantees that all replicas eventually receive all updates, regardless of the order. The system does not provide replication transparency but large scale systems like Bayou allows this. Conflicting updates are resolved using occasional anti-entropy sessions that incrementally steer the system towards a consistent configuration.
Implementing eventual consistency Updates are propagated via epidemic protocols. Server S1 randomly picks a neighboring server S2, and passes on the update. Case 1. S2 did not receive the update before. In this case, S2 accepts the update, and both S1 and S2 continue the process. Case 2. S2 already received the update from someone else. In that case, S1 loses interest in sending updates to S2 (reduces the probability of transmission to S2 to 1/p (p is a tunable parameter) There is always a finite probability that some servers do not receive all updates. The number can be controlled by changing p.
Anti-entropy sessions 30 These sessions minimize the “degree of chaos” in the states of the replicas. During such a session, server S1 will “pull” the update from S2, and server S3 can “push” the update to S4 Timestamp of update 30 S4 26 32 30 S3 S2 S1 24
Exercise Let x, y be two shared variables Process PProcess Q {initially x=0} {initially y=0} x :=1; y:=1; if y=0 x:=2 fi; if x=0 y:=2 fi; Print x Print y If sequential consistency is preserved, then what are the possible values of the printouts? List all of them.
Client centric consistency model Relevant in the cloud storage environment
Client-centric consistency model Read-after-read If read from A is followed by read from B then the second read should return a data that is as least as old the previous read. A B Iowa City San Francisco {All the emails read at location A must be marked as read in location B}
Client-centric consistency model Read-after-write (a.k.a read your writes} Consider a large distributed store containing a massive collection of music. Clients set up password-protected accounts for purchasing and downloading music. Alice changed her password in Iowa City, traveled to a Minneapolis, and tried to access the collection by logging into the account using her new password, then she must be able to do so.
Client-centric consistency model Write-after-read (a.k.a. write-follows-read) Each write operation following a read should take effect on the previously read copy, or a more recent version of it. Use your bank card to pay $500 in a store in Denver Alice then went to San Francisco Balance = $1500 Balance:=balance-$500 Write should take effect on Balance = $1500 Balance in Iowa city bank after your paycheck was credited But the payment did not go through! Write-after-read consistency was violated
Client-centric consistency model Write-after-write (a.k.a. monotonic write) When write at S is followed by write at a different server S’, the updates at S must be visible before the data is updates at S’. S’ S San Francisco Dallas Alice then went to San Francisco Only ½ of the updates at S are visible here Alice gave a raise to each of her 100 employees Alice then decided to give a 10% bonus on the new salary to every employee ½ of the employees will receive a lower bonus Write-after-read consistency was violated
Implementing client-centric consistency Read set RS, write set WS Before an operation at a different server is initiated, the appropriate RS or WS is fetched from another server.
Quorum-based protocols A quorum system engages only a designated minimum number of the replicas for every read or write operation – this number is called the read or write quorum. When the quorum is not met, the operation (read or write) is not performed. Improves reliability, availability, and reduces the load on individual servers
Quorum-based protocols Use 2-phase locking to update all the copies (value, version #) Write quorum Thomas rule To write, update > N/2 of them, and tag it with new version number. To read, access > N/2 replicas, and access the value from the copy with the largest version number. Otherwise abandon the read Read quorum
Rationale N = no of replicas. Ver 3 Ver 2 If different replicas store different version numbers for an item, the state associated with a larger version number is more recent than the state associated with a smaller version number. We require that R+W > N, i.e., read quorums always intersect with write quorums. This will ensure that read results always reflect the result of the most recent write (because the read quorum will include at least one replica from the most recent write).
How it works N = no of replicas. 1. Send a write request containing the state and new version number to all the replicas and waits to receive acknowledgements from a write quorum. At that point the write operation is complete. The replicas are locked when the write is in progress. 2. Send a read request for the version number to all the replicas, and wait for replies from a read quorum.
Quorum-based protocols After a partition, only the larger segment runs the protocol. The smaller segment contains stale data, until the network is repaired. Ver.1 Ver.0
Quorum-based protocols:Generalized version Asymmetric quorum: W + R > N W > N/2 No two writes overlap No read overlaps with a write. R = read quorum W = write quorum This generalization is due to Gifford.
Brewer’s CAP Theorem In an invited talk in the PODC 2000 conference, Eric Brewer presented a conjecture: that it is impossible for a web service to provide all three of the following guarantees: consistency (C), Availability (A), and partition-tolerance (P). Individually each of these guarantees is highly desirable, however, a web-service can meet at most two of the three guarantees.
A High-level View of CAP Theorem For consistency and availability, propagate the update from the left to the right partition. But how can you do it? So sacrifice partition tolerance If you prefer partition tolerance and availability, the sacrifice consistency. Or if you prefer both partition-tolerance and consistency, then sacrifice availability – users in the right partition will wait indefinitely until the partition is restored and the update is propagated to the right.
Amazon Dynamo Amazon’s Dynamo is a highly scalable and highly available key-value storage designed to support the implementation of its various e-commerce services. Dynamo serves tens of millions of customers at peak times using thousands of servers located across numerous data centers around the world Dynamo uses distributed hash tables (DHT) to map its servers in a circular key space using consistent hashingcommonly used in many P2P networks. .
Amazon Dynamo (a) The key K is stored in the server SG and is also replicated in servers like SH and SA (b) The evolution of multi-version data as reflected by the values of the vector clocks.
Amazon Dynamo Multiple versions of data are however rare. In a 24-hour profile of the shopping cartservice, 99.94% of requests saw exactly one version, and 0.00057% of requests saw 2 versions. Write: the coordinator generates the vector clock for the new version, and sends it to the top T reachable nodes. If at least W nodes respond, then the write is considered successful. Read: the coordinator sends a request for all existing version to the T top reachable servers. If it receives R responses then the read is considered successful Uses sloppy quorum-- T, R, and W are limited to the first set of reachable non-faulty servers in the consistent hashing ring -- this speeds up the read and the write operations by avoiding the slow servers. Typically, (T,R,W) = (3,2,2)
Amazon Dynamo Maintains the spirit of “always write” When a designated server S is inaccessible or down, the write is directed to a different server S’ with a hint that this update is meant for S . S’ later delivers the update to S when it recovers (Hinted handoff). Service level agreement Quite stringent -- a typical SLA requires that 99.9% of the read and write requests execute within 300ms, otherwise customers lose interest and business suffers.