Download
1 / 55
640 likes | 998 Views
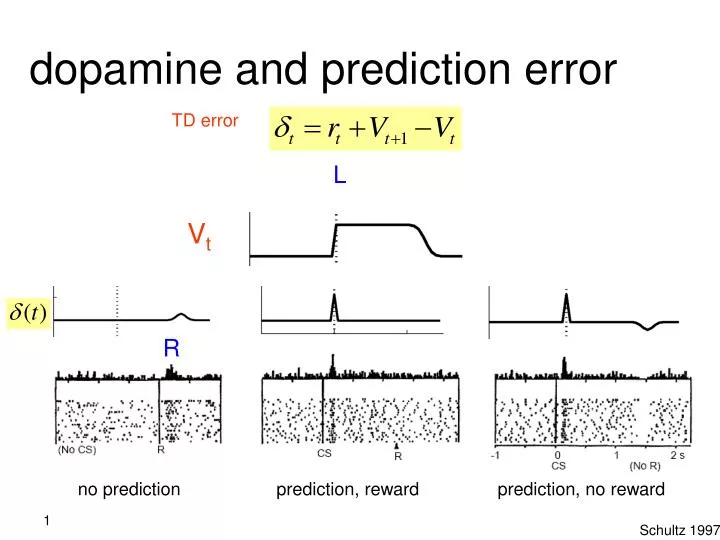
dopamine and prediction error. TD error. L. R. V t. R. no prediction. prediction, reward. prediction, no reward. Schultz 1997. humans are no different. dorsomedial striatum/PFC goal-directed control dorsolateral striatum habitual control ventral striatum

E N D
dopamine and prediction error TD error L R Vt R no prediction prediction, reward prediction, no reward Schultz 1997
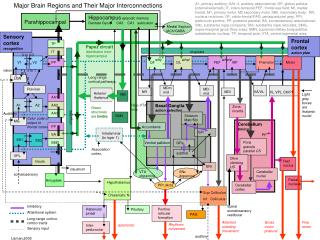
humans are no different • dorsomedial striatum/PFC • goal-directed control • dorsolateral striatum • habitual control • ventral striatum • Pavlovian control; value signals • dopamine...
< 1 sec 5 sec ISI 0.5 sec 2-5sec ITI You won 40 cents in humans… 5 stimuli: 40¢ 20¢ 0/40¢ 0¢ 0¢ 19 subjects (dropped 3 non learners, N=16) 3T scanner, TR=2sec, interleaved 234 trials: 130 choice, 104 single stimulus randomly ordered and counterbalanced
raw BOLD (avg over all subjects) prediction errors in NAC unbiased anatomical ROI in nucleus accumbens(marked per subject*) can actually decide between different neuroeconomic models of risk * thanks to Laura deSouza
Polar Exploration Peter Dayan Nathaniel Daw John O’Doherty Ray Dolan
Exploration vs. exploitation Classic dilemma in learned decision making For unfamiliar outcomes, how to trade off learning about their values against exploiting knowledge already gained
Exploration vs. exploitation • Exploitation • Choose action expected to be best • May never discover something better Reward Time
Exploration vs. exploitation • Exploitation • Choose action expected to be best • May never discover something better • Exploration: • Choose action expected to be worse Reward Time
Exploration vs. exploitation • Exploitation • Choose action expected to be best • May never discover something better • Exploration: • Choose action expected to be worse • If it is, then go back to the original Reward Time
Exploration vs. exploitation • Exploitation • Choose action expected to be best • May never discover something better • Exploration: • Choose action expected to be worse Reward Time
Exploration vs. exploitation • Exploitation • Choose action expected to be best • May never discover something better • Exploration: • Choose action expected to be worse • If it is better, then exploit in the future Reward Time
Exploration vs. exploitation • Exploitation • Choose action expected to be best • May never discover something better • Exploration: • Choose action expected to be worse • Balanced by the long-term gain if it turns outbetter • (Even for risk or ambiguity averse subjects) • nb: learning non trivial when outcomes noisy or changing Reward Time
Bayesian analysis (Gittins 1972) • Tractable dynamic program in restricted class of problems • “n-armed bandit” • Solution requires balancing • Expected outcome values • Uncertainty (need for exploration) • Horizon/discounting (time to exploit) • Optimal policy: Explore systematically • Choose best sum of value plus bonus • Bonus increases with uncertainty • Intractable in general setting • Various heuristics used in practice Value Action
Experiment • How do humans handle tradeoff? • Computation: Which strategies fit behavior? • Several popular approximations • Difference: what information influences exploration? • Neural substrate: What systems are involved? • PFC, high level control • Competitive decision systems (Daw et al. 2005) • Neuromodulators • dopamine (Kakade & Dayan 2002) • norepinephrine (Usher et al. 1999)
Task design Subjects (14 healthy, right-handed) repeatedly choose between four slot machines for points (“money”), in scanner Trial Onset Slots revealed
Task design Subjects (14 healthy, right-handed) repeatedly choose between four slot machines for points (“money”), in scanner + Trial Onset +~430 ms Slots revealed Subject makes choice - chosen slot spins.
Task design Subjects (14 healthy, right-handed) repeatedly choose between four slot machines for points (“money”), in scanner + Trial Onset +~430 ms Slots revealed + obtained 57 Subject makes choice - chosen slot spins. points +~3000 ms Outcome: Payoff revealed
Task design + + obtained 57 points + Subjects (14 healthy, right-handed) repeatedly choose between four slot machines for points (“money”), in scanner Trial Onset +~430 ms Slots revealed Subject makes choice - chosen slot spins. +~3000 ms Outcome: Payoff revealed +~1000 ms Screen cleared Trial ends
Payoff structure Noisy to require integration of data Subjects learn about payoffs only by sampling them
Payoff structure Noisy to require integration of data Subjects learn about payoffs only by sampling them
Payoff structure Payoff
Payoff structure Nonstationary to encourage ongoing exploration (Gaussian drift w/ decay)
Analysis strategy • Behavior: Fit an RL model to choices • Find best fitting parameters • Compare different exploration models • Imaging: Use model to estimate subjective factors (explore vs. exploit, value, etc.) • Use these as regressors for the fMRI signal • After Sugrue et al.
Behavior model 1. Estimate payoffs mgreen, mredetc sgreen, sredetc 2. Derive choice probabilities Pgreen, Predetc Choose randomly according to these
Behavior model Kalman filter Error update (like TD) Exact inference 1. Estimate payoffs mgreen, mredetc sgreen, sredetc 2. Derive choice probabilities Pgreen, Predetc Choose randomly according to these
Behavior model Kalman filter Error update (like TD) Exact inference x 1. Estimate payoffs x payoff mgreen, mredetc sgreen, sredetc x 2. Derive choice probabilities t+1 trial t Pgreen, Predetc Choose randomly according to these
Behavior model Kalman filter Error update (like TD) Exact inference x 1. Estimate payoffs x payoff mgreen, mredetc sgreen, sredetc x 2. Derive choice probabilities t+1 trial t Pgreen, Predetc Choose randomly according to these
Behavior model Kalman filter Error update (like TD) Exact inference x x 1. Estimate payoffs x payoff mgreen, mredetc sgreen, sredetc x 2. Derive choice probabilities t+1 trial t Pgreen, Predetc Choose randomly according to these
Behavior model Kalman filter Error update (like TD) Exact inference x x 1. Estimate payoffs x x payoff mgreen, mredetc sgreen, sredetc x x 2. Derive choice probabilities t+1 trial t Pgreen, Predetc Choose randomly according to these
Behavior model Kalman filter Error update (like TD) Exact inference 1. Estimate payoffs payoff mgreen, mredetc sgreen, sredetc 2. Derive choice probabilities t+1 trial t Pgreen, Predetc Choose randomly according to these Behrens & volatility
Behavior model Kalman filter 1. Estimate payoffs mgreen, mredetc sgreen, sredetc Compare rules: How is exploration directed? 2. Derive choice probabilities Pgreen, Predetc Choose randomly according to these
Behavior model mgreen, mredetc sgreen, sredetc Compare rules: How is exploration directed? 2. Derive choice probabilities Pgreen, Predetc Choose randomly according to these
Behavior model mgreen, mredetc sgreen, sredetc Value Compare rules: How is exploration directed? 2. Derive choice probabilities Action (dumber) (smarter)
Behavior model mgreen, mredetc sgreen, sredetc Value Compare rules: How is exploration directed? 2. Derive choice probabilities Action Randomly “e-greedy” Probability (dumber) (smarter)
Behavior model mgreen, mredetc sgreen, sredetc Value Compare rules: How is exploration directed? 2. Derive choice probabilities Action Randomly “e-greedy” By value “softmax” Probability (dumber) (smarter)
Behavior model mgreen, mredetc sgreen, sredetc Value Compare rules: How is exploration directed? 2. Derive choice probabilities Action Randomly “e-greedy” By value “softmax” By value and uncertainty “uncertainty bonuses” Probability (dumber) (smarter)
Model comparison • Assess models based on likelihood of actual choices • Product over subjects and trials of modeled probability of each choice • Find maximum likelihood parameters • Inference parameters, choice parameters • Parameters yoked between subjects • (… except choice noisiness, to model all heterogeneity)
Behavioral results e-greedy softmax uncertainty bonuses -log likelihood (smaller is better) • Strong evidence for exploration directed by value • No evidence for direction by uncertainty • Tried several variations 4208.3 3972.1 3972.1 # parameters 19 19 20
Behavioral results e-greedy softmax uncertainty bonuses -log likelihood (smaller is better) • Strong evidence for exploration directed by value • No evidence for direction by uncertainty • Tried several variations 4208.3 3972.1 3972.1 # parameters 19 19 20
Imaging methods • 1.5 T Siemens Sonata scanner • Sequence optimized for OFC (Deichmann et al. 2003) • 2x385 volumes; 36 slices; 3mm thickness • 3.24 secs TR • SPM2 random effects model • Regressors generated using fit model, trial-by-trial sequence of actual choices/payoffs.
Imaging results L • TD error: dopamine targets (dorsal and ventral striatum) • Replicate previous studies, but weakish • Graded payoffs? vStr x,y,z= 9,12,-9 dStr p<0.01 x,y,z= 9,0,18 p<0.001
Value-related correlates probability (or exp. value) of chosen action: vmPFC L vmPFC vmPFC % signal change p<0.01 p<0.001 probability of chosen action x,y,z=-3,45,-18 payoff amount: OFC L mOFC mOFC % signal change p<0.01 p<0.001 payoff x,y,z=3,30,-21
Exploration • Non-greedy > greedy choices: exploration • Frontopolar cortex • Survives whole-brain correction L rFP rFP p<0.01 p<0.001 LFP x,y,z=-27,48,4; 27,57,6
Timecourses Frontal pole IPS