Download

1 / 36
360 likes | 391 Views
Single Cell RNAseq at PF2. Plate-forme Transcriptome et Epigénome – Biomics – CITECH. Odile Sismeiro and Marie-Agnès Dillies. 22/09/2015. Presentation. Why the Single Cell ?. Standard RNASeq. Single Cell RNASeq. Person of the year 2013 Time Magazine. Uniformity. Specificity.

E N D
Single Cell RNAseq at PF2 Plate-forme Transcriptome et Epigénome – Biomics – CITECH • Odile Sismeiro and Marie-Agnès Dillies • 22/09/2015
Why the Single Cell ? Standard RNASeq Single Cell RNASeq Person of the year 2013 Time Magazine Uniformity Specificity
Cell Isolation Methods Angela Wu et al, NATURE METHODS, 2013
Fluidigm workflow Lysis, RT & Amplify Preparelibrary Sequence Wash & Stain Isolate Cells Load & Capture SMARTer kit (Clontech) Libraries cDNA Nextera XT DNA kit (Illumina) Illumina systems C1 Single Cell Auto Prep System (Fluidigm) 8,5 hours (night) 2 hours 3 days
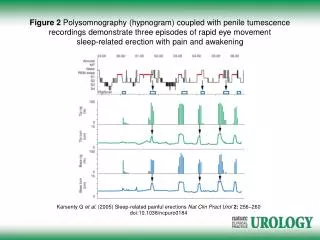
The spikes 92 ≠ RNAs The spikes are equally distributed in all the 96 wells Positive control of the RT and PCR reactions Independent of the presence of cells Data modeling tool
Quality Control Lysis, RT & Amplify Preparelibrary Sequence Wash & Stain Isolate Cells Load & Capture SMARTer kit (Clontech) Libraries cDNA Nextera XT DNA kit (Illumina) Illumina systems C1 Single Cell Auto Prep System (Fluidigm) cDNA + spikes Library No cDNA, spikesonly Bioanalyser DNA High Sensitivity chip (Agilent)
Pilot experiment In the context of the transcriptomic study of amoeba (ANR Genamibe) 96 wells Amoeba 25-40 µm, motiles (Entamoeba histolytica) 50 cells ERCC spikes 24 cDNA + Human Cells 10-20 µm (Liver sinusoidal endothelial cells) 24 libraries 2 lanes on the Illumina HiSeq2000
Samples Cells % Human Amoeba 20 Libraries % 4 Human Amoeba
Results Sequences of 50 bases 12 samples multiplexed per lane of the HiSeq2000 Illumina sequencer
Results Sequences of 50 bases
Results Sequences of 50 bases > Alignment on the genome
Results Sequences of 50 bases > Alignment on the genome > Alignment on the spikes RNAs Between 3 and 15 %
Analysis of the 20 human cells A B Countings Genome Gene A 4 Gene B 14 Human 1 Human 2 Human 3 Human 4 Analysis . . . . Human 20
Detection of heterogeneous transcription • Genes with varying expression level within a homogeneous cell population • Count data with very high level of technical noise, due to a small amount of starting biological material (RNA from a single cell) • We look for genes exhibiting an expression level variability higher than technical noise • Proposed statistical method : • Based on the hypothesis that technical noise intensity depends on the mean expression level • Derives a model of technical noise from spikes included in the experiment • Detects genes with a between-cell variability significantly higher than technical variability
Relationship between noise and amount of RNA • Dilutions to reduce the starting amount of RNA • Low mean read count : high level of technical noise • High mean read count : low level of technical noise • Difference between dilutions : the count level at which the noise becomes dominant
Paper data sets • Arabidopsis thaliana • 7 GL2 cells • 6 QC cells • Technical variance is measured from total RNA extracted from human Hela cells + 92 ERCC spikes (External RNA Control Consortium) • Mus musculus • 91 cells • ERCC spikes
Principle of the analysis process DESeq Normalisation Technical Data Technical noise model (GLM) Threshold ath One-sided test: H0 : aBi < athi Counts DESeq Normalisation Biological Data Estimate the per gene variability aBi Reject H0: highly variant gene
The SMARTer kit (Clontech) o/n (8,5 hrs) 21 cycles
The SMARTer (Clontech) and Nextera (Illumina) kits o/n (8,5 hrs) 2 hrs
The Nextera XT kit 12 cycles
Costs Reagents and consumables