Download

1 / 16
160 likes | 299 Views
Caching Queues in Memory Buffers . Rajeev Motwani (Stanford University) Dilys Thomas (Stanford University). Problem. Memory: fast, expensive and small Disk: large (infinite), inexpensive but slow Maintaining Queues: motivated by DataStreams, Distributed Transaction Processing, Networks

E N D
Caching Queues in Memory Buffers Rajeev Motwani (Stanford University) Dilys Thomas (Stanford University)
Problem • Memory: fast, expensive and small Disk: large (infinite), inexpensive but slow • Maintaining Queues: motivated by DataStreams, Distributed Transaction Processing, Networks • Queues to be maintained in memory, but may be spilled onto disk.
Model • Queue updates and depletion * single/multiple queues • Cost Model: * unit cost per read/write * extended cost model: c0 + c1٭numtuples seek time=5-10ms, transfer rates=10-160MBps
Contd.. • Online algorithms for different cost models. • Competitive analysis • Acyclicity
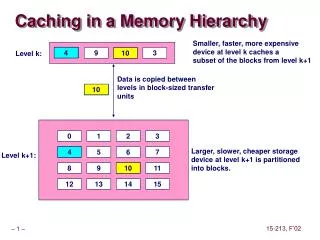
Algorithm HALF TAIL HEAD Memory size = M SPILLED HEAD < SPILLED < TAIL SPILLED empty => TAIL empty SPILLED nonempty => HEAD, TAIL < M/2
HEAD SPILLED TAIL
Initially all tuples in HEAD First write: M/2 newest tuples from HEAD to SPILLED. Then, tuples enter TAIL when SPILLED non-empty *WRITE-OUT: TAIL > M/2 write(M/2) TAIL →SPILLED *READ-IN: HEAD empty, SPILLED nonempty read(M/2) SPILLED→ HEAD *TRANSFER: after READ-IN if SPILLED empty move (rename) TAIL → HEAD //to maintain invariant 3
m/2 w1 m/2 w2 m/2 w3 m/2 w4 m/2 w5 m/2 w6 m m m m m m Analysis HALF is acyclic (M/2 windows disjoint) Alternate M-windows disjoint. Atleast one tuple from each M-window has to be written to disk by any algorithm including offline These have to be distinct writes. Hence 2-competitive wrt writes. Reads analysis similar. Lower bound of 2 by complicated argument: see paper.
Multiple(n) Queues • Queue additions adversarial as in previous setting. • Queue depletions: Round-Robin Adversarial Static allocation of buffer between n queues cannot be competitive
Multiple Queues: BufferedHead • Dynamic memory allocation • Write out newest M/2n of the largest queue in memory when no space in memory for incoming tuples • Read-ins in chunks of M/2n • Analysis: see paper
Multiple Queues: BufferedHead *BufferedHead is acyclic *Round-Robin: BufferedHead is 2n-competitive √n lower bound on acyclic algorithms *Adversarial: no o(M) competitive algorithm * However if given M/2 more memory than adversary then BufferedHead is 2n-competitive
ExtendedCost Model: GreedyChunk Cost model: c0 + c1٭t Let block-size, T=c0/c1 All read-ins, write-outs in chunks of size T T=100KB- few MB Simple algorithm: GREEDY-CHUNK *Write-out newest T tuples when no space in memory *Read-in T oldest tuples if oldest tuple on disk
Extended Cost Model: GreedyChunk If M > 2T Algorithm GREEDY-CHUNK Else Algorithm HALF Algorithm is 4-competitive, acyclic. Analysis see paper. Easy extension to Multiple Queues.
Practical Significance • Gigascope: AT&T’s network monitoring tool: SIGMOD 03 – drastic performance decrease on disk usage • DataStream systems: good alternative to approximation, no spilling algorithms previously studied.
Related Work • IBM MQSeries: spilling to disk • Related work on Network Router Design: using SRAM and DRAM memory hierarchies on the chip Open Problems Acyclicity: remove for multiple queues. Close the gap between the upper and the lower bound.