Download
1 / 39
390 likes | 592 Views
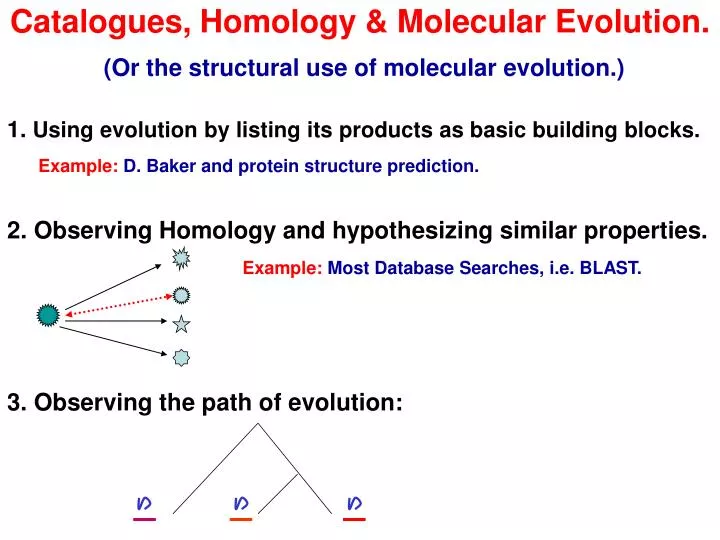
Catalogues, Homology & Molecular Evolution. (Or the structural use of molecular evolution.). 1. Using evolution by listing its products as basic building blocks. Example: D. Baker and protein structure prediction. . 2. Observing Homology and hypothesizing similar properties.

E N D
Catalogues, Homology & Molecular Evolution. (Or the structural use of molecular evolution.) 1. Using evolution by listing its products as basic building blocks. Example:D. Baker and protein structure prediction. 2. Observing Homology and hypothesizing similar properties. Example:Most Database Searches, i.e. BLAST. 3. Observing the path of evolution:
Molecular Evolution & Structure # # C T A G G T C C # # # # # # # # # Fundamental Observation: The Molecular Evolution of a position in a molecule depends on its Structure. Consequence: Observing Molecular Evolution contains information about the Structure.
Overview. Three examples of the use of observing molecular evolution: Protein Secondary Structure RNA Secondary Structure Comparative Genome Annotation Technicalities: Structure Description Hidden Markov Models: Protein Secondary Structure/Gene Finding Context Free Grammars: RNA Structure, regulatory signals Molecular Evolution Description The Generality of the Problem
Structure Dependent Molecular Evolution I Protein Secondary Structure L L L a a NDAHIWFHWWYVKHGCDNDAHIWFHWWYVKHGCDVVHISA L a From Goldman et al.(1996) JMB.
Structure Dependent Molecular Evolution II RNA Secondary Structure From Durbin et al.(1998) Biological Sequence Comparison Secondary Structure : Set of paired positions. A-U + C-G can base pair. Some other pairings can occur + triple interactions exists. Pseudoknot – non nested pairing: i < j < k < l and i-k & j-l.
Structure Dependent Molecular Evolution III Genes Bases in non-coding & coding: 1 2 3 A .249 .245 .294 .171 C .251 .247 .227 .279 G .251.362 .179 .293 T .249.146 .301 .256 Coding Non-coding m .225 .350 ts/tv 2.5 1.89 dN/dS .14about 1 Diffs .15.30
Goldman, Thorne & Jones: ”Structure” + ”Evolution” 1 3 2 4 1 A S D F G H J K L P 2 A S D F G H J K L P 3 D S D F G K J K L C 4 D S D F G K J K L C HMM x x x x x x x L x x x
Three Questions O1 O2O3 O4O5 O6O7 O8 O9 O10 H1 H2 H3 What is the probability of the data? What is the most probable ”hidden” configuration? What is the probability of specific ”hidden” state? Training: Given a set of instances, find parameters making them probable if they were independent.
Goldman-Thorne-Jones: Application to 7 Xylanases From Goldman et al.(1996) JMB.
A few small RNA Structures 1 1 1 1 2 2 2 2 3 3 3 3 1 1 1 1 1 1 2 2 2 2 2 2 3 3 3 3 3 3 4 4 4 4 4 4 Three nucleotides: Four nucleotides: .......... Forbidden: (Pseudo knot)
Simple String Generators Terminals(capital)---Non-Terminals(small) i. Start with SS --> aT bS T --> aS bT One sentence – odd # of a’s: S-> aT -> aaS –> aabS -> aabaT -> aaba ii. S--> aSa bSb aa bb One sentence (even length palindromes): S--> aSa --> abSba --> abaaba
Secondary Structure Generators S --> LSL .869 .131 F --> dFdLS .788 .212 L --> s dFd .895 .105
Chomsky Linguistic Hierarchy Source: Biological Sequence Comparison W nonterminal sign, a any sign are strings, but , not null string. Empty String i. Regular Grammars: W --> aW’ W --> a ii. Context-Free Grammars W --> iii. Context-Sensitive Grammars 1W2 --> 12 iv. Unrestricted Grammars 1W2 --> The above listing is in increasing power of string generation. For instance "Context-Free Grammars" can generate all sequences "Regular Grammar" can in addition to some more.
SCFG Analogue to HMM calculations O1 O2O3 O4O5 O6O7 O8 O9 O10 H1 H2 H3 HMM/Stochastic Regular Grammar: SCFG - Stochastic Context Free Grammars: W WL WR j L 1 i i’ j’
Comparative Gene Finding Non-Comparative Gene Finding Gene Characteristics HMMs (i.e. GeneScan) Comparative Gene Finding Structure + Homology Procrustes: Protein Databases & Gene Finding Alignment, then conserved exons, etc. (TwinScan,GLASS, Rosetta) Alignment with Gene Finding (Huson, Scharling, Blayo,..) Structure + Evolution Skou Pedersen, Irmtraud Meyer
Quality-of-Performance Measures Burset & Guigo in Genomics 34.354-
The Total Gene Finding Problem ESTs Data: Genomes, proteins & ESTs (Expressed Sequence Tags) Proteins Genomes Tasks:Gene Grammar/Knowledge of Genes. Genome Sequence Alignment. Genome - (protein/EST) alignment. Combined Gene Finding
Gene and non-gene characteristics. Gene characteristics: i. dinucleotide, codon & dicodon characteristics ii. regulatory regions iii. start - splice - termination signals iv. vague characteristics found by Neural Networks. v. Gene Evolution: replacement/silent substitutions < 1, few insertion-deletion, most of length k*3. Non-gene characteristics: i. Many repeats ii. Non-Gene Evolution: replacement/silent substitutions = 1, many insertion-deletion also would-be frame-shifts.
Gene Finding and Protein (HMM) Descriptors Burge & Karlin jmb 96 Make gene characteristics to each nucleotide. Extract legal prediction by dynamical programming. B. Use HMM to describe biological knowledge of gene structure.
GENSCAN:Gene Finding and Protein (HMM) Descriptors Burge & Karlin jmb 96
Molecular Evolution and Gene Finding:Two HMMs AGTGGTACCATTTAATGCG..... Pcoding{ATG-->GTG} or AGTGGTACTATTTAGTGCG..... Pnon-coding{ATG-->GTG} Simple Prokaryotic Simple Eukaryotic
Molecular Evolution and Gene Finding Meyer/Durbin/Goldman from Sanger Centre/Cambridge is working on highly similar approach. W-H-Li, T.Speed .. is has simlar methods. Many have similar, but non-evolutionary approaches.
Performance as sequence number grows. Simulated Sequences related by a binary tree analyzed using the ”true” model. Prob. that predicted gene is there. Prob. that existing gene is predicted.
Gene Finding & Protein Homology (Gelfand, Mironov & Pevzner, 1996) Protein Database Exon Ordering Graph Spliced Alignment: 1. Define set of potential exons in new genome. 2. Make exon ordering graph - EOG. 3. Align EOG to protein database. T Y G H L P T Y G H L P T Y - - L P M Y L P M T W Q
Simultaneous Alignment & Gene Finding Bafna & Huson, 2000, T.Scharling,2001 & Blayo,2002. Align by minimizing Distance/ Maximizing Similarity: Align genes with structure Known/unknown:
Simultaneous Alignment & Gene Finding Bafna & Huson, 2000, T.Scharling,2001 & Blayo,2002. Can only be done using similarity maximisation. 1- Type Similarity Recursion: Si,j= Max{Si-1,j-1+si,j, Si-1,j- g, Si,j-1 - g} si,j = log(Pi,j/PiPj) Simple Model of Genome: Fastly & Slowly Evolving Single Positions. 2- Type Similarity Recursion: (a) SFi,j= Max{SFi-1,j-1+sFi,j , SFi-1,j- g , SFi,j-1 - g SSi-1,j-1+sSi,j -c, SSi-1,j- g -c, SSi,j-1 - g -c} (b) SSi,j= Max{SSi-1,j-1+sSi,j , SSi-1,j- g , SSi,j-1 - g SFi-1,j-1+sFi,j -c, SFi-1,j- g -c, SFi,j-1 - g -c}
Trivial Suboptimal Solutions Suboptimal Solutions in Dynamical Programming/String Matching: i. Solutions within e of optimum ii. Label Edges/Nodes touched by SubOpt. 50/60 42/50 32/40 27/30 17/20 22/10 19/0 G 40/50 32/40 22/30 17/20 22/10 17/2 27/10 T 30/40 22/30 12/25 22/17 12/7 22/12 32/20 G 20/32 12/27 2/1712/7 22/12 32/22 42/30 T 10/27 2/17 10/12 20/17 30/32 40/32 50/40 T 0/19 10/12 20/22 30/27 40/37 50/42 60/50 C T A G G A
An Idea/Problem: Non-trivial Suboptimal Solutions Alternative Splicing Motivated Problem: Find Non-trivial Suboptimal Solutions!!! A trivial sub-solution is an optimal solution slightly worsened.
Summary General Problem: Entities observed in Homologous Variants. Two Applications: RNA Structures. Gene Finding. Describe its evolutionary process Describe their evolutionary relationship Infer hidden structure or combine observations optimally. Two Problems: No Structure Evolution Alignment unproblematic Future: Alternative Splicing Viral genes
Recommended Literature Vineet Bafna and Daniel H. Huson (2000) The Conserved Exon Method for Gene Finding ISMB 2000 pp. 3-12 S.Batzoglou et al.(2000) Human and Mouse Gene Structure: Comparative Analysis and Application to Exon Prediction. Genome Research. 10.950-58. Blayo, Rouze & Sagot (2002) ”Orphan Gene Finding - An exon assembly approach” J.Comp.Biol. Delcher, AL et al.(1998) Alignment of Whole Genomes Nuc.Ac.Res. 27.11.2369-76. Gravely, BR (2001) Alternative Splicing: increasing diversity in the proteomic world. TIGS 17.2.100- Guigo, R.et al.(2000) An Assesment of Gene Prediction Accuracy in Large DNA Sequences. Genome Research 10.1631-42 Kan, Z. Et al. (2001) Gene Structure Prediction and Alternative Splicing Using Genomically Aligned ESTs Genome Research 11.889-900. Ian Korf et al.(2001) Integrating genomic homology into gene structure prediction. Bioinformatics vol17.Suppl.1 pages 140-148 Tejs Scharling (2001) Gene-identification using sequence comparison. Aarhus University JS Pedersen (2001) Progress Report: Comparative Gene Finding. Aarhus University Reese,MG et al.(2000) Genome Annotation Assessment in Drosophila melanogaster Genome Research 10.483-501. Stein,L.(2001) Genome Annotation: From Sequence to Biology. Nature Reviews Genetics 2.493-
Acknowledgements Comparative RNA Structure - Bjarne Knudsen http://www.daimi.au.dk/~compbio/pfold/ Comparative Gene Structure - Jakob Skou Pedersen





















