Download

1 / 49
490 likes | 731 Views
Lecture7. Introduction to signaling pathways Reverse Engineering of biological networks Metabolomics approach for determining growth-specific metabolites based on FT-ICR-MS Self organizing mapping(SOM). Introduction to signaling pathways.

E N D
Lecture7 • Introduction to signaling pathways • Reverse Engineering of biological networks • Metabolomics approach for determining growth-specific metabolites based on FT-ICR-MS • Self organizing mapping(SOM)
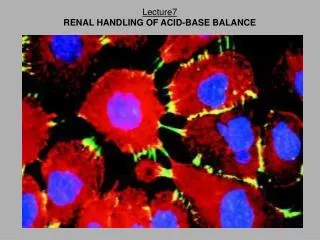
Introduction to signaling pathways Signaling networks involves the transduction of “signal” usually from outside to the inside of the cell On molecular level signaling involves the same type of processes as metabolism such as production and degradation of substances, molecular modifications (mainly phosphorylation but also methylation and acetylation) and activation or inhibition of reactions. But signaling pathways serve for information processing or transfer of information while metabolism provide mainly mass transfer
Introduction to signaling pathways • Signal transduction often involves: • The binding of a ligand to an extracellular receptor • The subsequent phosphorylation of an intra cellular enzyme • Amplification and transfer of the signal • The resultant change in the cellular function e.g. increase /decrease in the expression of a gene
Signaling paradiam Usually a signaling network has three principal parts: Events around the membrane Reactions that link sub-membrane events to the nucleus Events that leads to transcription Source: Systems biology in practice by E. klipp et. al.
Schematic representation of receptor activation Source: Systems biology in practice by E. klipp et. al.
Steroids Not always a receptor exists at the membrane for example the steroid receptors. Sterol lipids include hormones such as cortisol, estrogen, testosteron and calcitriol. These steroids simply cross the membrane of the target cell and then bound the intracellular receptor which results in the release of the inhibitory molecule from the receptor. The receptor then traverses the nuclear membrane and binds to its site on the DNA to trigger the transcription of the target gene. Source: Systems biology by Bernhard O. Palsson
G-protein coupled receptor (GPCR) represents important components of signal transduction network This class of receptor comprises 5% of the genes in C. elegans The G-protein complex consists of three subunits (α, β and λ) and in its inactive state bound to guanosinediphosphate(GDP) When a ligand binds to the GPCR, the G-protein exchanges its GDP for a guanosinetrihosphate(GTP) This exchange leads to the dissociation of the G-protein from the receptor and its split into a βλ complex and a GTP-bound α subunit which is its active state initiating other downstream processes G-protein signaling Source: Systems biology by Bernhard O. Palsson
G-protein signaling model Source: Systems biology in practice by E. klipp et. al.
G-protein signaling model Time course of G protein activation. The total number of molecules is 10000. The concentration of GDP-bound Gα is low for the whole period due to its fast complex formation with the heterodimerGβλ Source: Systems biology in practice by E. klipp et. al.
The JAK-STAT network The JAK-STAT signaling system is an important two-step process that is involved in multiple cellular functions including cell growth and inflammatory response A cell surface receptor often dimerizes upon binding to a cytokine The monomeric form of the receptor is associated with a kinase called JAK When the receptor dimerizes the JAKs induce phosphorylation of themselves and the receptor which is the active state of the receptor. The active complex phosphorylates the STAT(signal transducer and activator of transcription) molecules STAT molecules then dimerizes, go to nucleus and trigger transcription Source: Systems biology in practice by E. klipp et. al.
Schematic representation of the MAP kinase cascade. An upstream signal causes phosphorylation of the MAPKKK. The phosphorylation of the MAPKKK in turn phosphorylates the protein at the next level. Dephosphorylation is assumed to occur continuously by phosphatases or autodephosphorylation Source: Systems biology in practice by E. klipp et. al.
Signaling pathways in Baker’s yeast HOG pathway activated by osmotic shock, pheromone pathway activated by pheromones from cells of opposite mating type and pseudohyphal growth pathway stimulated by starvation condition A MAP kinase cascade is a particular part of many signalling pathways . In this figure its components are indicated by bold border Source: Systems biology in practice by E. klipp et. al.
Reverse Engineering of biological networks The task of reverse engineering of a genetic network is the reconstruction of the interactions among biological entities ( genes, proteins, metabolites etc.) in a qualitative way from experimental data using algorithm that weight the nature of the possible interactions with numerical values. In forward modeling network is constructed with known interactions and subsequently its topological and other properties are analyzed In reverse engineering the network is estimated from experimental data and then it is used for other predictions
Reverse Engineering of gene regulatory network By clustering the gene expression data, we can determine co-expressed genes. Co-expressed genes might have similar regulatory characteristics but it is not possible to get the information about the nature of the regulation. Here we discuss a reverse engineering method of estimating regulatory relation between genes based on gene expression data from the following paper: Reverse engineering gene networks using singular value decomposition and robust regression M. K. Stephen Yeung, JesperTegne´ r†, and James J. Collins‡ Proc. Natl. Acad. Sci. USA 99:6163-6168
Reverse Engineering of gene regulatory network It is assumed that the dynamics i.e. the rate of change of a gene-product’s abundance is a function of the abundance of all other genes in the network. For all N genes the system of equations are as follows: In Vector notation Where f(X) is a vector valued function
Reverse Engineering of gene regulatory network Under linear assumption i.e. has linear relation with Xi s we can write Here Aij is the coupling parameter that represents the influence of Xj on the expression rate of Xi . In other words Aij represents a network showing the regulatory relation among the genes. Target of reverse engineering is to determine A. Solving A requires a large number of measurements of and X
Reverse Engineering of gene regulatory network Measurement of is difficult and hence can be estimated in several ways. First, if time series data can be obtained then can be approximated by using the profiles of the expression values for fixed time intervals Alternatively a cellular system at steady state can be perturbed by external stimulation and then can be determined by comparing the gene expression in the perturbed cellular population and the unperturbed reference population.
Reverse Engineering of gene regulatory network Now using any method if we can produce matrices and then we can write Or, (if external perturbation is used) Here BNxMis the matrix representing the effect of perturbation The goal of reverse engineering is to use the measured data B, X, and to deduce A i.e. the connectivity matrix of the regulatory relation among the genes.
Reverse Engineering of gene regulatory network By taking transpose the system can be rewritten as A is the unknown. If M =N and X is full-ranked, we can simply invert the matrix X to find A. However, typically M<<N mainly because of the high cost of perturbations and measurements. We therefore have an underdetermined problem. Underdetermined problem means the number of linearly independent equations is less than the number of unknown variables. Therefore there is no unique solution One way to get around this is to use SVD to decompose XTinto
Reverse Engineering of gene regulatory network where U and V are each orthogonal which means: with I being the identity matrix, and W is diagonal: Without loss of generality, we may assume that all nonzero elements of wkare listed at the end, i.e., w1, w2, . . . , wL=0 and wL+1, wL+2,. . . , wN≠0, where L :=dim(ker(XT)). Then one particular solution for A is:
Reverse Engineering of gene regulatory network the general solution is given by the affine space with C = (cij)N×N, where cijis zero if j >L and is otherwise an arbitrary scalar coefficient. This family of solutions in Eq. 3 represents all the possible networks that are consistent with the microarray data. Among these solutions, the particular solution A0 is the one with the smallest L2 norm. Now, the question is which one of the solutions of equation 3 is the best.
Reverse Engineering of gene regulatory network In such cases, we may rely on insights provided by earlier works on gene regulatory networks and bioinformatics databases, which suggest that naturally occurring gene networks are sparse, i.e., generally each gene interacts with only a small percentage of all the genes in the entire genome. Imposing sparseness on the family of solutions given by Eq. 3 means that we need to choose the coefficients cijto maximize the number of zero entries in A. This is a nontrivial problem.
Reverse Engineering of gene regulatory network The task is equivalent to the problem of finding the exact-fit plane in robust statistics, where we try to fit a hyperplane to a set of points containing a few outliers. Here they have chosen L1 regression where the figure of merit is the minimization of the sum of the absolute values of the errors, for its efficiency. In short, this method of reverse engineering can produce multiple solutions (gene networks) that are consistent with a given microarray data. This paper says among them the sparsest one is the best solution and used L1 regression to detect the best solution.
Metabolomics approach for determining growth-specific metabolites based on FT-ICR-MS
[1] Metabolomics Tissue Samples MS Species Metabolite information Molecular weight and formula Fragmentation Pattern Experimental Information Species Species-Metabolite relation DB Metabolites B C I L Metabolite 1 Metabolite 2 Metabolite 3 Metabolite 5 D E F H K Metabolite 4 Metabolite 6 Interpretation of Metabolome
10 T8 T6 T7 T5 T4 T3 T2 1 OD600 T1 0.1 0 200 400 600 800 Time (min) M M+1 M/2 Data Processing from FT-MS data acquisition of a time series experiment to assessment of cellular conditions • Metabolite quantities • for time series experiments E. coli (b) Data preprocessing and constructing data matrix (c) Classification of ions into metabolite-derivative group Time point (d) Annotation of ions as metabolites m/z Metabolites (e) Assessment of cellular condition by metabolite composition
(b) Data matrix metab.1 metab.200 time 1 time 2 719.4869 747.5112 time 8 722.505 time Software are provided by T. Nishioka (Kyoto Univ./Keio Univ.)
M-12 (c) Classification of ions into metabolite-derivative group (DPClus) Correlation network for individual ions. Intensity ratio between Monoisotope (M) and Isotope (M+1) # of Carbons in molecular formula: M-8 5 M-11 4 3 M-9 M-5 M-10 6 M-14 M-4 9 M-7 M-6 2-3 M-13 8 M-15 7 10 2-2 M-16 11 PG10 M-17 1-3 PG9 PG3 M-3 M-2 PG4 1-4,5 1-1 M-1 PG7 PG6 PG1 PG2 2-1 PG8 PG5 1-6 1-2
10 T8 T6 T7 T5 T4 T3 OD600 T2 1 T1 0.1 0 200 400 600 800 Time (min) M=220 X N=8 (e) Estimation of cell condition based on a function of the composition of metabolites. PLS (Partial Least Square regression model) -- extract important combinations of metabolites. N (biol.condition) << M (metabolites) Metabolites Responses K=1 measurement points PLS Y N=8 cell condition cell condition Y(Cell density)= a1 x1 +…+ aj xj +….+ aM xM xj, the quantity for jth metabolites
(e) Assessment of cellular condition by metabolite compositionDetection of stage-specific metabolites(PLS model of OD600 to metabolite intensities) y(OD600 Cell Density)= a1 x1 +…+ aj xj +….+ aM xM xj , the quantity for jth aj> 0, stationary phase-dominant metabolites aj < 0, exponential phase-dominant metabolites MS/MS analyses PG2,4,6,8,10 0.1 omega-Cycloheptylnonanoate dTDP-6-deoxy-L-mannose Parasperone A omega-Cycloheptylundecanoate, cis-11-Octadecanoic acid UDP-glucose, UDP-galactose UDP aj Octanoic acid UDP-N-acetyl-D-glucosamine UDP-N-acetyl-D-mannosamine dTMP, dGMP, 3'-AMP NADH Lenthionine 80 metabolites 0.0 120 metabolites Argyrin G omega-Cycloheptyl-alpha-hydroxyundecanoate ATP, dGTP omega-Cycloheptyl-alpha-hydroxyundecanoate dTDP Glyoxylate PG1,3,5,7,9 MS/MS analyses ADP, Adenosine 3',5'-bisphosphate, dGDP ADP-(D,L)-glycero-D-manno-heptose Red: E.coli metabolites;Black: Other bacterial metabolites NAD -0.15 Exponential-phase dominant Stationary-phase dominant
10 Phosphatidylglycerols detected by MS/MS spectra unsaturated PGs cyclopropanated PGs (b) Relation of mass differences among PG1 to 10marker molecules (Cluster 1) Exponential phase PG5 30:1(14:0,16:1) PG1 32:1(16:0,16:1) PG3 34:1(16:0,18:1) ∆(CH2)2 ∆(CH2)2 28.0281 28.0315 2.0138 US Cyclopropane Formaiton of PGs CFA 14.0170 CFA 14.0187 CFA 14.0110 PG7 34:2(16:1,18:1) PG9 36:2(18:1,18:1) ∆(CH2)2 28.0330 Stationary phase PG6 31:0(14:0,c17:0) PG2 33:0(16:0,c17:0) PG4 34:5(16:0,c19:0) ∆(CH2)2 ∆(CH2)2 CFA 14.0181 CFA 14.0197 28.0298 28.0237 2.0051 US PG8 35:1(16:1,c19:1) PG10 37:1(18:1,c19:0) ∆(CH2)2 (Cluster 2) 28.0314 • Cyclopropane Formation of PGs occurs in the transition from exponential to stationary phase.
Time-series Data Growth curve 10 j … T … 1 2 1 0.1 0.01 Time Expression profiles Stage 1 2 …. j … T T, # of time-series microarray experiments D, # of genes in a microarray When we measure time-series microarray, gene expression profile is represented by a matrix SOM makes it possible to examine gene similarity and stage similarity simultaneously.
Time-series Data Growth curve 10 j … T … 1 2 1 0.1 0.01 Time Expression profiles Expression similarity Stage 1 2 …. j … T T, # of time-series microarray experiments D, # of genes in a microarray … … Stage similarity Multivariate Analysis SOM : expression similarity of genes andstage similaritysimultaneously. STATES State-Transition BL-SOM is available at http://kanaya.aist-nara.ac.jp/SOM/ When we measure time-series microarray, gene expression profile is represented by a matrix SOM makes it possible to examine gene similarity and stage similarity simultaneously.
SOM was developed by Prof. Teuvo Kohonen in the early 1980s Multi-dimensional data/input vectors are mapped onto a two dimensional array of nodes In original SOM, output depends on input order of the vectors. To remove this problem Prof. Kanaya developed BL-SOM. [1] Initial model vectors are determined based on PCA of the data. [2] The learning process of BL-SOM makes the output independent of the order of the input vectors.
SOM Algorithm Source: “Clustering Challenges in Biological Networks” edited by S. Butenko et. al.
SOM Algorithm Source: “Clustering Challenges in Biological Networks” edited by S. Butenko et. al.
SOM Algorithm Source: “Clustering Challenges in Biological Networks” edited by S. Butenko et. al.
SOM Algorithm in Fig. before Source: “Clustering Challenges in Biological Networks” edited by S. Butenko et. al.
[1] Detection method for transition points in gene expression and metabolite quantity based on batch-learning Self-organinzing map (BL-SOM) [2] Diversity of metabolites in species Species-metabolite relation Database Self-organizing Mapping (Summary) X1 XT Gene i (xi1,xi2,..,xiT) X2 T, different time-series microarray experiments
Self-organizing Mapping (Summary) Arrangement of lattice points in multi-dimensional expression space Lattice points are optimized for reflecting data distribution X1 Gene Classification Genes are classified into the nearest lattice points XT Gene i (xi1,xi2,..,xiT) X2
Self-organizing Mapping (Summary) Arrangement of lattice points in multi-dimensional expression space Lattice points are optimized for reflecting data distribution X1 Gene Classification Genes with similar expression profiles are clusterized to identical or near lattice points X1 (Time 1) Feature Mapping In the i-th condition, lattice points containing only highly (low) expressed genes are colored by red (blue). XT X2 (Time 2) X2 (ex.) Xk> Th.(k) Xk< -Th.(k) X3 (Time 3) k=1,2,…,T Visually comparing among each stage of time-series data ….. ….. ….. XT (Time T) Non-linear projection of multi-dimensional expression profiles of genes. Original dimension is conserved in individual lattice points. Several types of information is stored in SOM
Estimation of transition points; Bacillus subtilis (LB medium) (Data: Kazuo Kobayashi, Naotake Ogasawara (NAIST)) Stage 1 2 3 4 5 6 7 8 High prob. 10 0 Cell Density (OD600 ) 6 7 5 8 4 1 log(Prob. Density) 3 2 0.1 -1000 1 0.01 LB 0.001 -2000 0 200 400 600 800 1000 Low prob. (min) SOM for time-series expression profile State transition point is observed between stages 3 and 4
Integerated analysis of gene expression profile and metabolite quantity data of Arabidopsis thaliana (sulfur def./cont.; Data are provided by K.Saito, M. Hirai group (PSC) ) ppm(error rate) Nakamura et al (2004)
State transition Feature Maps Leaf Leaf Gene Metabolites (m/z) Lattice points with highly difference between 12 and 24 h. Blue: Decreased Red: increased Root Root Accurate molecular weights Candidate metabolites corresponding to accurate molecular weights 3. Species-metabolite relation Database
Download sites of BL-SOMRiken: http://prime.psc.riken.jp/NAIST: http://kanaya.naist.jp/SOM/ Application of BL-SOM to “-omics” Genome Kanaya et al., Gene, 276, 89-99 (2001) Abe et al., Genome Res., 13, 693-702, (2003) Abe et al., J.Earth Simulator, 6, 17-23, (2003) Abe et al., DNA Res., 12, 281-290. (2005) Transcriptome Haesgawa et al., Plant Methods, 2:5:1-18 (2006) Metabolome Kim et al., J. Exp.Botany, 58, 415-424, (2007) Fukusaki et al., J.Biosci.Bioeng., 100, 347-354, (2005) Transcriptome and Metabolome Hirai, M. Y., M. Klein, et al. J.Biol. Chem., 280, 25590-5 (2005) Hirai, M. Y., M. Yano, et al. Proc Natl Acad Sci U S A 101, 10205-10 (2004) Morioka, R, et al., BMC Bioinformatics, 8, 343, (2007) Yano et al., J.Comput. Aided Chem.,7,125-136 (2007) … …
Summary of Bioinformatics Tool developed in our laboratoryhttp://kanaya.naist.jp/~skanaya/Web/JTop.html All softwares and DB are freely accessable via Web. Metabolomics -- MS data processing Transcriptome and Metabolomics Profiling -- estimation of transition points Species-metabolite DB Network analysis: PPI Transcriptomics -- Statistics, Profiling, …
Introduction to self organizing mapping software & Introduction to software package Expander http://acgt.cs.tau.ac.il/expander/