Download

1 / 55
550 likes | 577 Views
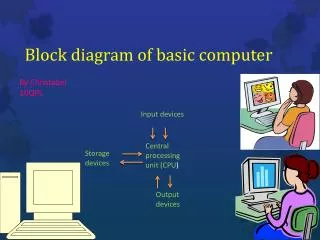
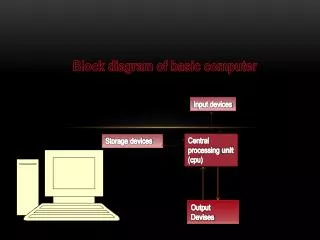
Basic Block Scheduling. Utilize parallelism at the instruction level (ILP) Time spent in loop execution dominates total execution time It is a technique that reforms the loop, so as to achieve an overlapped iteration execution. Process Overview.

E N D
Basic Block Scheduling • Utilize parallelism at the instruction level (ILP) • Time spent in loop execution dominates total execution time • It is a technique that reforms the loop, so as to achieve an overlapped iteration execution
Process Overview • Parallelize a single operation or the whole loop? • More parallelism achievable if we consider the entire loop • Construct Instructions that contain operations from different iterations of the initial loop • Construct a flat schedule, and repeat it over the time taking into account resource and dependence constraints.
Techniques • Software pipelining restructures loops in order to achieve overlapping of various iterations in time • Although this optimization does not create massive amounts of parallelism, it is desirable • There exist two main methods for software pipelining: kernel recognition and modulo scheduling
Modulo Scheduling • We will focus on modulo scheduling technique (it is incorporated in commercial compilers) • We try to select a schedule for one loop iteration and then repeat the schedule • No unrolling applied
Terminology (Dependences) • To make a legal schedule, it is important to know which operations must follow other operations • A conflict exists if two operations cannot execute, at the same time, but it does not matter which one executes first (resource/hardware constraints) • A dependence exists between two operations if interchanging their order changes the result (data/control dependences)
Terminology (Data Dependence Graph) • Represent operations as nodes and dependences between operations as directed arcs • Loop carried arcs show relationships between operations of different iterations (may turn DDG into cyclic graph) • Loop independent arcs represent a must follow relationship among operations of the same iteration • Assign arc weights with the form of a (dif, min) dependence pair. • dif value indicates the number of iterations the dependence spans • mintime which is the time to elapse between consecutive execution of the dependent operations • Value (min/dif) is called the slope of the schedule
Terminology (Resource Reservation Table) • Construct Resource Reservation Table
Terminology (Loop Types) • Doall loop in which iterations can proceed in parallel. Those type of loops lead to massive parallelism and are easy to schedule • Doacross loop in which synchronization is needed between operations of various iterations
Doall Loop Example • dif=0, no loop-carried dependences • min=1, loop-independent dependences • Construct a valid flat schedule. Then, repeat it
Doacross Loop Example (dif=1) • dif=1 for Operation1 (loop-carried dependences exist) • min=1, loop-independent dependences • Construct a valid flat schedule. Then, repeat it • However, repetition is not easy • We should take into account that dif=1 for O1. • Each Iteration should start with one slot delay • A legal scheduled has been achieved
Doacross Loop Example (dif=2) • dif=2 for Operation1 (loop-carried dependences exist) • min=1, loop-independent dependences • Each second Iteration should now start with one slot delay from the previous • This is because dif=2, dependence is deeper (that is less restrictive)
Comparison • In our first example where dif=1 and min=1, the kernel is found in the 4th time slot and is equal to 4 3 2 1. Instructions before and after the kernel are defined as the prelude and postlude of the schedule, respectively • In the second example the loop carried dependence is between iterations that are two apart. This is a less restrictive constraint, so iterations are overlapped more. Indeed, the kernel now is 4 4 3 3 2 2 1 1
Main Idea • Let’s combine all these concepts (data dependence graph, resource reservation tables, schedule, loop types, arcs, flat schedule) in some simple examples • Don’t forget that the main idea behind software pipelining (incl. modulo scheduling) is that the body of a loop can be reformed so as to start one loop iteration before previous iterations have finished
Another Loop Example • O1 is always scheduled inthe first time step. • Thus the distancebetween O1 and the rest of the operations increases in successive iterations. • cyclic pattern (such as those achievable in other examples) never forms.
Initiation Interval • So far we have described the first step of modulo scheduling procedure, that is analysis of DDG for a loop to identify all kinds of dependences • Second step is to try identify the minimum number of instructions required between initiating execution of successive loop iterations • Specifically, the delay between iterations of the new loop is called the Initiation Interval (II) a) Resource Constrained II b) Dependence Constrained II
Resource Constrained IIres • The resource usage imposes a lower bound on the initiation interval (IIres). For each resource, compute the schedule length necessary to accommodate uses of that resource. • If we have a DDG and 4 available resources, we try to calculate the maximum usage for every resource
Example • Resource 2 is required 4 times. • e.g. 2 can only be executed 4 cycles after its previous execution • Suppose that the Flat schedule is as shown. • We repeat it with 4 time slots delay
Methods for computing IIdep • Modulo scheduling is all about calculating the lower bound for the initiation interval • We will present two techniques to compute the dependence constrained II (the calculation of IIres is straightforward) 1) Shortest Path Algorithm 2) Iterative Shortest Path
1) Shortest Path Algorithm • This method uses transitive closure of a graph which is a reachability relationship • Let θ be a cyclic path from a node to itself, minθ be the sum of the min times on the arcs that constitute the cycle and difθ be the sum of dif times on the arcs • So the time between execution of a node and itself depends on II, e.g. time elapsed between execution of α node and another copy difθ iterations away is II * difθ • The maximum min/dif for all cycles is the IIdep
Repeating Flat schedule • Let’s see the effect of II on cyclic times in this figure • II must be large enough so that II * difθ >= minθ
Calculate IIdep • Therefore, we select II: II = max(IIdep, IIres)? • II * difθ >= minθ 0 >= minθ- II * difθ 0 >= minθ- IIdep * difθ
Shortest Path Algorithm Example Transitive closure of the graph
2) Iterative Shortest Path • Simplify the previous method by recomputing the transitive closure of the graph for each possible II • Use the term of distance (Mab)between two nodes
Distance Ma,b • In the flat schedule (relative scheduling of each operation of the original iteration, something like list scheduling), the distance between two nodes a, b joint by an arc whose weight is (dif, min) is given by: Ma,b = min – II * dif • We want to compute the minimum distance two nodes must be separated, but this information is dependent on the initiation interval
Procedure to find II • Construct a matrix M where each entry Mi,j represents the min time between two subsequent nodes i and j • This computation gives the earliest time node j can be placed with respect to node i in the flat schedule Estimate that II=2
Procedure to find II • The next step is to compute matrix M2 which represents the minimum time difference between nodes of length two • Continue by calculating matrix M3 and so on. • Finally, we compute Γ(Μ) as following
Final Result • Γ(Μ) represents the maximum distance between each pair of nodes considering paths of all lengths • A legal II will produce a closure matrixin which entries on the main diagonal are non-positive • Positive values on the diagonal is an indication of a small initiation interval • Negative values across the diagonal indicate an adequate estimate of II
Plus or minus • Drawback of this method is that before we are able to construct the matrix M, we should estimate II • However, this technique allows us to tell if the estimate for II is large enough or need to iteratively try larger II
Why use “modulo” term in the first place? • Initially, we have the flat schedule F, consisting of location F1, F2…. • Kernel K is formed by overlapping copies of F offset by II • Modulo scheduling results when all operations from locations in the flat schedule that have the same value modulo II are executed simultaneously
Operations from (Fi: i mod II = 1) execute togetherOperations from (Fi: i mod II = 0) execute together
Example 1 Graph of example 1 DO I=1, 100 a[I] = b[I-1] + 5; b[I] = a[I] • I; // mul->2clocks c[I] = a[I-1] • b[I]; d[I] = c[I]; ENDDO
Example 1 PRODUCE THE FLAT SCHEDULE • S1 and S2 are strongly connected • Which one should be placed earlier in the Flat schedule? • S3 and S4 should be placed after S1 and S2 (S3 should precede S4) • Eliminate all loop-carried dependences • Loop-Independent arcs determine the sequence of nodes in the flat schedule • Flat schedule is therefore:
Example 1 • COMPUTE II • Using the method of “Shortest Path Algorithm” • Find Strongly connected components • Calculate the transitive closure of the graph II = max (3/1, 3/1) = 3.
Example 1 • Execution schedule • Each blue box represents the kernel of the pipeline Worst case scenario: E=0 when II=length of the flat schedule => no overlapping between adjacent operations
EXAMPLE 2 DO I=1, 100 S1: a[I] = b[I-1] + 5; S2: b[I] = a[I] • I; S3: c[I] = a[I-1] • b[I]; S4: d[I] = c[I] + e[I-2]; S5: e[I] = d[I] • f[I-1]; S6: f[I] = d[I] • 4; ENDDO
EXAMPLE 2 • PRODUCE THE FLAT SCHEDULE • Eliminate all loop-carried dependences • Loop-Independent arcs determine the sequence of nodes in the flat schedule • Flat schedule is therefore:
EXAMPLE 2 • COMPUTE II using the method of “Shortest Path Algorithm” • Find Strongly connected components • Initiation Interval for the first graph is II=3 • Calculate the transitive closure of the second graph II = max (3/2, 5/2) = 2.5 IItotal = max (2.5, 3) = 3
EXAMPLE 2 • Execution code of example 2 • Kernel in blue box
EXAMPLE 3 Nodes S1, S2 comprise a strongly connected component. II is therefore:
EXAMPLE 3 • Produce the Flat schedule. • Eliminate all loop-carried dependences • There is not a loop-independent arc across all nodes • In this case, flat schedule cannot be produced just by following the loop-independent arc • We need a global method to generate the flat schedule. • The pre-mentioned method does not always work • Introduce “Modulo scheduling via hierarchical reduction”
Modulo Scheduling Via Hierarchical Reduction • modify the DDG so as to schedule the strongly connected components of the graph first • strongly connected components of a graph can be found using Tarjan’s algorithm • afterwards, schedule the acyclic DDG
Modulo Scheduling Via Hierarchical Reduction • compute the upper and low bounds where each node can be placed in the flat schedule using Equations below • Its in an iterative method • We begin with II=1 trying to find a legal schedule • If it is not possible, II is incremented until all nodes are placed in the flat schedule in legal positions Equations to initialize low and upper bounds Equations to update low and upper bounds CostII(v, u) stands for the cost (measured by dif, min values) in order node v to reach node u. We need thus the cost matrix for the strongly connected nodes (i.e. the transitive closure).
EXAMPLE 4 DO I=1,100 S1: a(i) = c(i-1) + d(i-3); S2: b(i) = a(i) • 5; S3: c(i) = b(i-2) • d(i-1); S4: d(i) = c(i) + i; S5: e(i) = d(i); S6: f(i) = d(i-1) • i; S7: g(i) = f(i-1); ENDDO • Find strongly connected components • Compute the transitive closure
EXAMPLE 4 • Compute the Simplified Transitive Closure by keeping the values that give the maximum distance • Initialize the upper and low bounds for the nodes in the strongly connected component where costII(u,v) = MIIab(min, dif u→v) where σ(v) is the time slot in Fwhere thescheduled node has been placed Simplified Transitive Closure
EXAMPLE 4 (Initialize nodes) • Initialize the upper and low bounds for the nodes in the strongly connected component Simplified Transitive Closure
EXAMPLE 4 (Schedule the first node) S1:[ -1,∞ ] S2:[ 1 ,∞ ] S3:[ -2,∞ ] S4:[ 2 ,∞ ] • Node S3 has the lowest low bound so it is scheduled first. It is placed in time slot 0 (t0). • Afterwards, we need to update low and upper bounds for the rest nodes