Download

1 / 11
120 likes | 316 Views
Avoiding Communication in Sparse Iterative Solvers. Erin Carson Nick Knight CS294, Fall 2011. Motivation: Sparse Matrices. Many algorithms for scientific applications require solving linear systems of equations: Ax = b. In many cases, the matrix A is sparse

E N D
Avoiding Communication in Sparse Iterative Solvers Erin Carson Nick Knight CS294, Fall 2011
Motivation: Sparse Matrices • Many algorithms for scientific applications require solving linear systems of equations: Ax = b • In many cases, the matrix A is sparse • Sparse matrix: a matrix with enough zero entries to be worth taking advantage of • This means that information is “local” instead of “global”. A given variable only depends on some of the other variables. • Example: Simulating Pressure around Airfoil Figure: Simulating Pressure over Airfoil. Source: http://www.nada.kth.se
Sparse vs. Dense Linear Algebra • Different performance considerations for sparse matrices • Low computational intensity (small # non-zeros per row) – sparse matrix operations communication bound • Sparse data structures (CSR, diagonal, etc.) • Matrix structure encodes dependencies: sparsity pattern gives additional opportunities for avoiding communication • Changes the way we must think about partitioning • Finding an optimal partition is an NP-complete problem, heuristics must be used • Order of execution matters: must consider fill-in • Run-time auto-tuning important • pOSKI (Parallel Optimized Sparse Kernel Interface)
Sparse Solvers in Applications • Image Processing Applications • Ex: Image segmentation, Contour detection • Physical simulations • Solving PDEs • Often used in combination with Multigrid as bottom-solve • Ex: Simulating blood flow (Parlab’s Health App) • Mobile/Cloud applications • Communication more important where bandwidth is very limited, latency is long (or if this parameters are variable between machines!) • Auto-tuning becomes more important if we don’t know our hardware Figure: Contour Detection [CSNYMK10] Figure: ParLab Health App: Modeling Blood Blow in the Brain
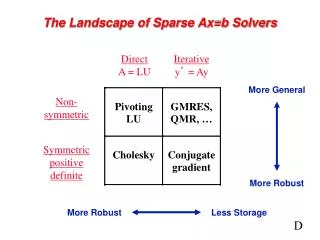
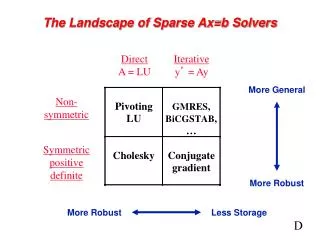
Solving a Sparse Linear System • Direct methods solve a linear system in a finite sequence of operations • Often used to solve dense problems • Ex: Gaussian Elimination = x • Iterative methods iteratively refine an approximate solution to the system • Used when • System is large and sparse – direct method too expensive • We only need an approximation – don’t need to solve exactly, so less operations needed • A is not explicitly stored • Ex: Krylov Subspace Methods (KSMs) A L U Direct Method for Solving Ax = b Initial guess Yes Return solution Convergence? No Refine Solution Iterative Method for Solving Ax = b
How do Krylov Subspace Methods Work? • A Krylov Subspace is defined as: • In each iteration, • Sparse matrix-vector multiplication (SpMV) with A to create new basis vector • Adds a dimension to the Krylov Subspace • Use vector operations to choose the “best” approximation of the solution in the expanding Krylov Subspace (projection of a vector onto a subspace) • How “best” is defined distinguishes different methods r 0 K projK(r) • Examples: Conjugate Gradient (CG), Generalized Minimum Residual Methods (GMRES), Biconjugate Gradient (BiCG)
Communication in SpMV • Consider the dependencies in the SpMV operation : • The value of depends on if • Graph formulation: • vertices , one for each element of the source/destination vector • Edge between and if v1 v2 v3 v4 • Graph partitioning commonly used as a method for finding a good partition • Since edges represent dependencies on matrix vector entries, cutting an edge represents an entry that must be communicated between partitions. • Therefore, minimizing the graph cut should correspond to minimizing communication between partitions in an SpMV operation with
Hypergraph Model for Communication in SpMV v1 v2 v1 v2 v3 v4 v4 v3 • Hypergraph: a generalization of a graph, where an edge (a hyperedge or net) can connect more than two vertices • Hypergraph model for row-wise partition (similar for column-wise) • Hyperedge for each column, vertex for each row. Vertex is connected to hyperedge if • Benefits over graph model: • Natural representation of nonsymmetric matrices • Cost of hyperedge cut for a given partition is exactly equal to the number of words moved in SpMV operation with the same partition of Pattern Matrix Graph Representation Hypergraph Representation (Column-Net Model)
Graph vs. Hypergraph Partitioning Consider a 2-way partition of a 2D mesh: Edge cut = 10 Hyperedge cut = 7 The cost of communicating vertex A is 1 – we can send the value in one message to the other processor According to the graph model, however the vertex A contributes 2 to the total communication volume, since 2 edges are cut. The hypergraph model accurately represents the cost of communicating A (one hyperedge cut, so communication volume of 1. Unlike graph partitioning model, the hypergraph partitioning model gives exact communication volume (minimizing cut = minimizing communication)
Example: Hypergraph vs. Graph Partitioning 2D Mesh, 5-pt stencil, n = 64, p = 16 Hypergraph Partitioning (PaToH) Total Comm. Vol = 719 Max Vol per Proc = 59 Graph Partitioning (Metis) Total Comm. Vol = 777 Max Vol per Proc = 69
Summary • Sparse matrices arise naturally from a variety of different applications • Different considerations for designing sparse vs. dense algorithms (matrix structure matters!) • SpMV is the core kernel in sparse iterative solvers • We can model dependencies in SpMV using (hyper)graph models • Minimizing communication in is NP-Complete (equivalent to hypergraph partitioning problem) • Many heuristics/software programs exist • Next: Can we avoid communication in computing matrix powers (repeated SpMVs)?