Download
1 / 1
10 likes | 162 Views
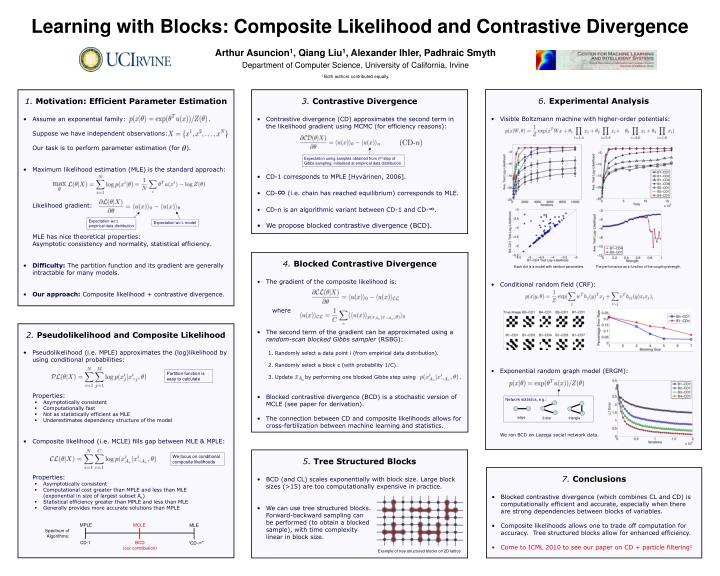
Learning with Blocks: Composite Likelihood and Contrastive Divergence. Arthur Asuncion 1 , Qiang Liu 1 , A lexander Ihler, Padhraic Smyth Department of Computer Science, University of California, Irvine 1 Both authors contributed equally. 6. Experimental Analysis

E N D
Learning with Blocks: Composite Likelihood and Contrastive Divergence Arthur Asuncion1, Qiang Liu1, Alexander Ihler, Padhraic Smyth Department of Computer Science, University of California, Irvine 1 Both authors contributed equally. • 6. Experimental Analysis • Visible Boltzmann machine with higher-order potentials: • Conditional random field (CRF): • Exponential random graph model (ERGM): • We ran BCD on Lazega social network data. • 3. Contrastive Divergence • Contrastive divergence (CD) approximates the second term in the likelihood gradient using MCMC (for efficiency reasons): • CD-1 corresponds to MPLE [Hyvärinen, 2006]. • CD-∞ (i.e. chain has reached equilibrium) corresponds to MLE. • CD-n is an algorithmic variant between CD-1 and CD-∞. • We propose blocked contrastive divergence (BCD). • 1. Motivation: Efficient Parameter Estimation • Assume an exponential family: . • Suppose we have independent observations: . • Our task is to perform parameter estimation (for ). • Maximum likelihood estimation (MLE) is the standard approach: • Likelihood gradient: • MLE has nice theoretical properties: • Asymptotic consistency and normality, statistical efficiency. • Difficulty: The partition function and its gradient are generally intractable for many models. • Our approach: Composite likelihood + contrastive divergence. Expectation using samples obtained from nthstep of Gibbs sampling, initialized at empirical data distribution Expectation w.r.t. empirical data distribution Expectation w.r.t. model • 4. Blocked Contrastive Divergence • The gradient of the composite likelihood is: • where • The second term of the gradient can be approximated using a random-scan blocked Gibbs sampler (RSBG): • 1. Randomly select a data point i (from empirical data distribution). • 2. Randomly select a block c (with probability 1/C). • 3. Update by performing one blocked Gibbs step using . • Blocked contrastive divergence (BCD) is a stochastic version of MCLE (see paper for derivation). • The connection between CD and composite likelihoods allows for cross-fertilization between machine learning and statistics. Each dot is a model with random parameters. The performance as a function of the coupling strength. • 2. Pseudolikelihood and Composite Likelihood • Pseudolikelihood (i.e. MPLE) approximates the (log)likelihood by using conditional probabilities: • Properties: • Asymptotically consistent • Computationally fast • Not as statistically efficient as MLE • Underestimates dependency structure of the model • Composite likelihood (i.e. MCLE) fills gap between MLE & MPLE: • Properties: • Asymptotically consistent • Computational cost greater than MPLE and less than MLE (exponential in size of largest subset Ac) • Statistical efficiency greater than MPLE and less than MLE • Generally provides more accurate solutions than MPLE Partition function is easy to calculate Network statistics, e.g.: edge 2-star triangle • 5. Tree Structured Blocks • BCD (and CL) scales exponentially with block size. Large block sizes (>15) are too computationally expensive in practice. • We can use tree structured blocks. • Forward-backward sampling can • be performed (to obtain a blocked • sample), with time complexity • linear in block size. We focus on conditional composite likelihoods • 7. Conclusions • Blocked contrastive divergence (which combines CL and CD) is computationally efficient and accurate, especially when there are strong dependencies between blocks of variables. • Composite likelihoods allows one to trade off computation for accuracy. Tree structured blocks allow for enhanced efficiency. • Come to ICML 2010 to see our paper on CD + particle filtering! MPLE MCLE MLE Spectrum of Algorithms: “CD-∞” CD-1 BCD (our contribution) Example of tree structured blocks on 2D lattice