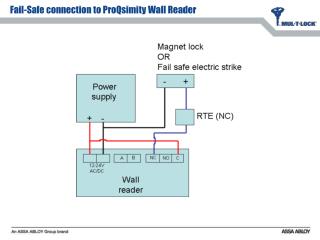
Download

1 / 27
270 likes | 364 Views
Fail-safe Communication Layer for DisplayWall. Yuqun Chen. DisplayWall Software Architecture. 2. 2. 2. 3. 3. render node. render node. render node. 1. 1. Logical Network. 1. 1. Command Broadcast. 1. master node. 3. Synchronization. Data Exchange. 3. Motivation.

E N D
Fail-safe Communication Layerfor DisplayWall Yuqun Chen
DisplayWall Software Architecture 2 2 2 3 3 render node render node render node 1 1 Logical Network 1 1 Command Broadcast 1 master node 3 Synchronization Data Exchange 3
Motivation • Complex communication patterns • programming the DisplayWall is difficult • BitBlt operation in Virtual Display Driver • Nodes and network links do fail • larger system is more likely to fail • OS may not be stable under high-load • applications have bugs
Design Goal [1] • Eases writing distributed applications on DisplayWall • supports some form of group concept • multicast or broadcast • no need to manage pair-wise connections
Design Goals[2] • An API for designing fail-safe DisplayWall apps • tolerate independent failures and recovery of render nodes • failures at the application master nodes are considered catastrophic • certain bugs cause all render nodes to fail • may or may not be able to deal with this
What’s different with others? • API-wise • mostly broadcast • some pair-wise exchange • Fault-tolerance wise • real-time characteristic • cannot wait for too long • OK to lose certain messages • dropping a few frames is OK
Some Requirements • Simple abstraction • users shouldn’t deal with pair-wise connections • Realizable on a variety of platforms • with and without programmable NI • Support storage and retrieval of application-dependent states (soft states) • Synchronized Clocks and Barriers
Communication Patterns • Command/Data Delivery • from master to some render nodes • broadcast in nature • Data exchange • among render nodes, e.g., bitblt and v-tiling • pair-wise in nature • Synchronization: clock and barriers • low-latency
Outline • Communication patterns • Soft States • API issues
Command Broadcast • Used by all applications • VDD, OpenGL, ImageViewer • Issues: • efficiency • dynamic membership: • live/dead nodes, overlapped windows • delivery semantics • best-effort, guaranteed, or sloppy
Guaranteed or Best-effort? • Guaranteed delivery implies • re-configurable (logical) topology for delivering data • loss-less delivery to all nodes • an intermediate node may fail right after delivery • the up-stream has to keep all the data for retransmission • Best-effort • as far as current topology allows • or limited flexibility
Transactions? • Each broadcast is treated as a transaction • keeps the data until the transaction commits • Transactions are asynchronous • one doesn’t wait till the previous commits • but, they are applied in order • Applied transactions mark the state at each node
Fail-safe Broadcast 1 2 3 4 1 2 3 4 1 2 3 4
Fail-safe Broadcast recv(msg) send msg to children c1, c2, …, cn if child c failed then recompute c’s subtree without c send to the new child cc
Questions • How to detect failure in a timely fashion? • global solution • the leaves send the acks to a master • the master forces a global reconfiguration after a timeout • a local solution • period positive ACK to the parent
Data Exchange • Pair-wise sends and recvs • High-level issues: • avoid the recv to get stuck by a failing sender • timeout or period “I am alive” ack • Implementation issues: • neighborhood communication? • probably sufficient for most apps except for load balancing
Synchronization • Barrier • a special form of broadcast • mostly used for global frame-buffer swap • Clock synchronization • can be used to reduce the frequency of barriers • e.g., MPEG playback according to local clock • what if it misses the deadline?
Unification • Transaction-based messages implement broadcast • implements some form of global ordering • Message passing for pair-wise data exchange • key is to detect the failures quickly
Example 1: VDD BitBlt BitBlt: calculate data to send calculate data to recv read frame buffer send data to some nodes if failure then take note recv data from some nodes if failure then use default image
Failure Recovery • What happens when a failed render node comes back up? • put itself into the broadcast tree • re-establish peer-to-peer message connection • hopefully all hidden • it has to bring its states up to date • highly application dependent
Soft States Example: OpenGL • Display List • each list consists a series of GL commands • must be re-executed to make the list meaningful • Textures • may be bound to a texture name
Soft States API • Tagged Safe Memory • a chunk of memory replicated on all nodes • tagged and ordered by an ID • associate a recovery handle/function to it • Operations: create, insert, and delete • Upon recovery: • retrieve all “live” chunks and apply the handles in order
Example 2: VDD recovery • Re-establish connections between nodes • Restore States: • cached bitmaps from other running nodes • fonts and brushes from other nodes • Or, force a re-draw from the master nodes
Messages? • Transactions can be implemented on top of messages • add a transaction ID for each message • People are familiar with message passing • as opposed to remote memory access • you have to manage memory, pretty message • What about copy avoidance?
Communication API • Message Passing Interface • send(node, type,data), recv(node, type, data) • only need to specify a remote node id • connection is hidden from the API • copy can be avoided by returning a buffer pointer instead of filling the user buffer • very close to sockets API but more flexible
Copy Avoiding Message Passing • Trivial • just return a pointer to the buffer • Remote memory semantics not necessary • very rare to update remote data structure • memory copy isn’t that bad ( > 200 MB/sec) • What about remote bitblt? • the only missing part is peer-to-peer • which we can’t do any way
Copy Avoiding Messages recv(msg) new msg CoreLogic Graphics hdr msg NIC global buffer