Download

1 / 24
240 likes | 378 Views
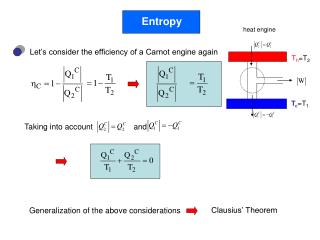
Entropiakoodaus, Entropy Coding. Tiedon tiivistäminen muodostaa laajan asiakokonaisuuden tietoliikennetekniikassa. Tiedon tiivistämisen malleihin liittyy käsite entropia (entropy). Tietoliikenteessä entropian tunnus on H, ja se antaa alarajan koodatun tiedon keskimääräiselle sanapituudelle.

E N D
Entropiakoodaus, Entropy Coding • Tiedon tiivistäminen muodostaa laajan asiakokonaisuuden tietoliikennetekniikassa. • Tiedon tiivistämisen malleihin liittyy käsite entropia (entropy). • Tietoliikenteessä entropian tunnus on H, ja se antaa alarajan koodatun tiedon keskimääräiselle sanapituudelle. • Jokaiselle mallille voidaan osoittaa, ettei entropiaa parempaan tiivistykseen keskimäärin voida päästä. tMyn
Tarve tiedon tiivistämiseen on suuri, koska siirrettävän tiedon määrä on kasvanut moninkertaisesti nopeammin kuin mitä siirtotekniikka sallii. • Valitun tiivistysmenetelmän (algoritmin) nopeus on tärkeä kriteeri, koska sekä tiedon tiivistäminen että sen purku pääsääntöisesti tapahtuvat siirron aikana. • Näin ollen algoritmin on selviydyttävä tehtävästään siten, ettei se vaikuta liikaa hidastavasti tiedon siirtoon. tMyn
Koodaustapaa mietittäessä tulee ottaa huomioon mahdollisuus yksiselitteiseen tulkintaan (unique decipherability). • Esim. olkoot lähetettävänä 4 sanomaa, sanomat M1-M4. Koodataan sanomat binaariseen muotoon seuraavasti: M1=1, M2=10, M3=01 ja M4=101. Jos nyt vastaanotetaan bittijono 101, niin ei voida yksiselitteisesti tulkita vastaanotettiinko sanoma M4, M2M1 vaiko M1M3. • Tilanne paranee, jos koodataan kukin sanoma siten, että niillä on yksiselitteinen etuliite. Siis esim. M1=1, M2=01, M3=001 ja M4=0001. tMyn
Otetaan vielä esimerkki koodaustavasta: M1=1, M2=10, M3=100 ja M4=1000. Kyseessä on kylläkin yksikäsitteisesti tulkittava koodaustapa, mutta tämä ei ole välittömästi (instantaneous) tulkittavissa. Esim. Kuvitellaan, että ollaan vastaanotettu bitit 10. Tässä vaiheessa ei voida olla varma siitä, tuliko vastaanotettua sanoma M2, M3 vaiko M4. tMyn
Informaatio ja entropia • Määritellään sanoman x informaatiosisältö kaavalla . • Kaavassa on sanoman x esiintymis-todennäköisyys. • Valitaan informaatiosisällön kaavassa logaritmin kantaluvuksi 2. Esim. Olkoot ravintolassa yksi ruokalista. Ruokalistassa on kaksi vaihtoehtoista valintaa, joita kumpaakin valitaan yhtä usein. Siispä todennäköisyys sille, että jompaa kumpaa ruokalajia tilataan, on 1/2. tMyn
Nyt kaavaan sijoitettuna sanoman informaatiosisällöksi saadaan . Tulkinta: tarvitaan yksi bitti kertomaan kumpaa ruokalajia tilataan. • Monipuolistetaan ruokalistaa: olkoot siellä nyt neljä vaihtoehtoa, ja ajatellaan, että kutakin lajia tilataan yhtä paljon. Todennäköisyys, että tilataan tiettyä lajia on siis 1/4. Sanoman informaatiosisällöksi saadaan Tulkinta: Jos sanoma lähetetään binaarisena, tarvitaan 2 bittiä/sanoma, esim. 00, 01, 10 ja 11. tMyn
Määritellään entropia sanoman keskimääräiseksi informaatiosisällöksi. Olkoot sanomia n kappaletta, • Määritellään entropia H seuraavasti: tMyn
Esim. Järjestelmä koostuu kuudesta sanomasta. Vastaavat todennäköisyydet ovat 1/4, 1/4, 1/8, 1/8, 1/8 ja 1/8. Laske entropia. Entropiaksi saadaan bittiä/sanoma. tMyn
Miten kehittää koodaustapa, jossa koodattavat sanat olisi koodattu keskimäärin pienimmällä mahdollisella bittimäärällä? Koodatut sanat tulisi olla yksiselitteisesti tulkittavissa. • Määritellään koodatun sanan keskimääräinen pituus • Kaavassa on i:nnen koodisanan pituus ja on i:nnen koodisanan esiintymistodennäköisyys. • Kaavasta nähdään, että mitä useammin sana esiintyy, sitä lyhyemmäksi se kannattaa koodata. tMyn
Koodauksen teorioista tiedetään, että binaarimuotoisessa koodauksessa keskimääräinen koodatun sanan pituus on yhtä suuri tai suurempi kuin entropia, siis • Jos lähetettävien symbolien lähetystodennäköisyys ei ole kaikilla sama, niin silloin lyhin keskimääräinen koodatun sanan pituus saavutetaan koodaamalla symbolit eri pituisiksi. tMyn
Esim. Oletetaan, että lähetettäviä symboleja on neljä eri laista, ja vastaavat lähetystodennäköisyydet ovat 1/8, 1/8, 1/4 ja 1/2. Mielikuvitukseton tapa koodata symbolit olisi antaa seuraavat binaarivastineet: 00, 01, 10 ja 11. Nyt siis koodatun sanan keskimääräinen pituus olisi 2 bittiä/sana. tMyn
Jos sitä vastoin koodattaisiin symbolit seuraavasti: 111, 110, 10 ja 0, saataisiin keskimääräiseksi koodatun sanan pituudeksi =1,75 bittiä/koodattu sana. • Miten keksitään kullekin mahdolliselle symbolille koodaus, joka tuottaa lähetyksessä keskimäärin minimipituuden siirrettävälle aineistolle? • Tiivistysmenetelmä voi keskittyä käytetyn koodiston optimointiin, tai se voi käyttää sanakirjaa. tMyn
Koodistoon keskittyvät menetelmät pyrkivät optimoimaan merkkien binaarimuotoista koodausta, ja sanakirjaa käyttävät menetelmät muistavat esiintyneitä sanoja ja niiden osia, eivätkä toista niitä uudelleen. • Tavallisessa tekstissä käytetty aakkosto muodostuu symboleista {0, 1, …a, b, …å, ä, ö} sekä joukosta erikoismerkkejä. • Tietoliikenteessä aakkosto esitetään jollakin sopivalla binaarikoodilla, jonka pituus on joko kiinteä tai vaihteleva. tMyn
Sellaiset menetelmät, joilla on olemassa jokin tiivistettävästä aineistosta riippumaton malli, kutsutaan staattisiksi. • Staattisessa menetelmässä sekä lähettäjä että vastaanottaja tuntevat etukäteen niin käytettävän mallin kuin mahdollisen hakemiston tai aakkoston rakenteen. • Menetelmä on yksinkertainen, mutta esim. englannin kielen merkkijakaumalle laadittu menetelmä ei kelpaa käytettäväksi muilla kielillä. • Malli voidaan määritellä myös siten, että käydään läpi siirrettävä aineisto, ja lasketaan aineiston merkkien todellinen esiintymisjakauma. tMyn
Kun jakauma on valmis, se siirretään vastaanottajalle, ja vasta sen jälkeen ryhdytään varsinaiseen tiedonsiirtoon. • Tällöin puhutaan puoliadaptiivisesta menetelmästä. • Heikkoutena on se, että siirrettävä aineisto on käsiteltävä kertaalleen ennen lähettämistä. Tämä voi olla joskus hankala toteuttaa! • Kolmantena vaihtoehtona on mukautuva eli adaptiivinen menetelmä, jossa mallia korjataan siirron aikana tiedon rakenteen mukaisesti. tMyn
Tietoliikenteessä esitetään yleisesti siirrettävä tieto kiinteämittaisilla binaarikoodeilla käyttäen esim. 8 bitin ASCII-koodia. • Kiinteämittainen koodaus yksinkertaistaa tiedon käsittelyä vastaanotossa, koska riittää, että tunnetaan merkin pituus ja synkronointimenetelmä. • Tiivistys perustuu kuitenkin usein myös merkkien vaihtuvamittaiseen koodaukseen. • Miten voidaan erottaa koodatut sanat toisistaan, jos käytettyjen symbolien koodatut muodot ovat erimittaisia? • Yhtenä ratkaisuna on etuliitekoodin käyttäminen. tMyn
Etuliitekoodauksen tarkoituksena on koodata aakkosto siten, että kunkin symbolin arvo voidaan määritellä heti, kun sen viimeinen bitti on luettu, ts. koodin alkuosa ei ole minkään toisen koodin alkuosa. tMyn
Aritmeettinen koodaus on merkkipohjaisista menetelmistä tehokkaimpia, mutta sen haittapuolena on tiivistämisen hitaus. • Koodaus perustuu tiivistettävien yksiköiden (merkkien tai sanojen) todennäköisyysjakaumaan, ja tässä kukin yksikkö varaa todennäköisyyttään vastaavan välin asteikolla 0,0 - 1,0. • Merkkikohtaisten todennäköisyyksien käyttäminen aritmeettisessa koodauksessa ei yleensä tuota riittävän hyvää tiivistystä. tMyn
Parempaan tulokseen päästään, jos otetaan huomioon merkkien keskinäiset riippuvuussuhteet. Esim. suomen kielessä kirjaimen k jälkeen ei tule koskaan kirjainta b, c, d, f, g, h, j, q, x tai z. Se minkälaisia seuraajia k:lla on, voidaan edelleen rajata tarkastelemalla k:n edeltäjiä… • Tunnettuja algoritmeja ovat DMC (Dynamic Marcov Coding) ja PPM (Prediction by Partial Matching). tMyn
Kaksi tunnettua etuliitekoodaukseen perustuvaa tiivistysmenetelmää ovat Shannon Fano -koodaus ja Huffman-koodaus. Menetelmät muistuttavat toisiaan, mutta Huffman-koodaus on tehokkaampi. • Molemmat perustuvat siihen, että käytetylle aakkostolle on olemassa todennäköisyysjakauma, jonka perusteella voidaan määritellä tuotettavan koodin pituus. • Useimmin esiintyvät merkit koodataan pienemmällä bittimäärällä kuin harvemmin esiintyvät merkit. • Käydään seuraavaksi Huffman-koodauksen perusidea läpi. tMyn
Olkoot lähetettävät symbolit ja . • Vastaavat lähetystodennäköisyydet ovat ja . 1. Listataan 1. sarakkeeseen symbolit laskevassa todennäköisyysjärjestyksessä. Lähteen symbolit muodostavat puun lehdet. tMyn
2. Yhdistellään symboleita: otetaan kaksi alinta todennäköisyyttä ja yhdistetään ne. Tämän seurauksena syntyi kaksi oksaa: merkitään ylempää ’0’ ja alempaa ’1’ (tai sitten päinvastoin, kunhan pysytään koko prosessi loogisesti samassa käytännössä!). 3. Toistetaan askel 2 niin kauan kunnes saadaan yhdistelmäsymbolin todennäköisyydeksi 1. 4. Koodisanat saadaan lukemalla oikealta vasemmalle oksia myöten, katso kuva 1. tMyn
Koodisana Tod.näk. Symboli 0 0 10 0 1 110 0 1 0 1110 1 1 1111 Kuva 1. Esimerkki Huffman-koodauksesta. tMyn
Lempel-Ziv -tiivistys • Lempel-Ziv -tiivistysmenetelmät käyttävät hyväkseen hakemistoja. • Hakemiston avulla vältetään toistamasta aiemmin esiintyneitä merkkiyhdistelmiä tai fraaseja. • Koodattu tieto muodostuu viitteestä sanakirjaan, jonka lähettäjä ja vastaanottaja ovat muodostaneet siirron aikana. tMyn