Download

1 / 20
200 likes | 211 Views
This paper presents LiFR, a linear regression model incorporating feature ranking, for assessing the readability of Chinese documents. The method selects the most valuable features specific to Chinese and builds a linear function to calculate the readability score.

E N D
Linear Model Incorporating Feature Ranking for Chinese Documents Readability Gang Sun, Zhiwei Jiang, Qing Guand Daoxu Chen State Key Laboratory for Novel Software Technology, Nanjing University, Nanjing 210000 2014 9th International Symposium on Chinese Spoken Language Processing (ISCSLP) 報告者:劉憶年 2015/4/7
Outline • Introduction • Related Work • Linear Model Incorporating Feature Ranking • Empirical Study • Conclusions
Introduction (1/2) • Given a document, its readability normally refers to the difficulty of reading and understanding by its readers. • Research has been done on readability assessment for nearly a century, and fruitful achievements made to automatically predict a document's reading level (score). • Recent research has used machine learning methods, and developed new and complex text features, taken from achievements in other research areas, such as Information Theory and Natural Language Processing. These newly developed methods have shown superiority over the classical readability formulae.
Introduction (2/2) • In this paper, we apply linear regression models for readability assessment of Chinese documents, and incorporate feature ranking to select the most appropriate features to build the linear function. Our method, named LiFR, resembles the process of building a traditional readability formula.
Related Work (1/2) • Generally, readability (or reading difficulty) of a document can be measured by predefined reading levels or readability score. Text features are typically used to determine a document's readability. Based on the features, readability formulae can be built to directly calculate the readability of a document. • Recently, based on achievements in NLP(natural language processing) and machine learning, many complex features are incorporated and new methods developed in readability research. • Researchers have approved that the machine learning methods are superior to traditional readability formulae in readability assessment. • Progress has also been made for Chinese readability assessment.
Related Work (2/2) • Our work differs from previous research in two ways. Firstly, we put forward LiFR (Linear model incorporating Feature Ranking), which is proved useful for readability assessment of Chinese documents. Secondly, we develop text features specific for Chinese, and use feature ranking to select the most valuable features.
Linear Model Incorporating Feature Ranking • We put forward a method which uses linear model incorporating feature ranking (LiFR) to assess the readability of Chinese documents.
Linear Model Incorporating Feature Ranking-- Feature Extraction • Surface features count the statistics of grammatical units in a document, such as average sentence length in words or characters, and number of syllables or characters per word. • Part of speech (POS) features also count the statistics of the grammatical units, the difference is that each type of words (e.g., noun, verb, adjective, adverb or onomatopoeia) are treated separately. • Parse tree features count the statistics of the parse trees extracted from a document. • Entropy features are borrowed from information theory, and can measure the transfer of information in a document.
Linear Model Incorporating Feature Ranking -- Feature Ranking (1/2) • Feature ranking is used to rank features according to their informativenessor importance to discriminate reading levels of documents. An evaluation function is required to compute the informative score of each feature, and features are assumed to be independent of each other. By feature ranking, the performances of the regression models may be improved since irrelevant features are eliminated.
Linear Model Incorporating Feature Ranking -- Feature Ranking (2/2) • Information gain (IG), also called Kullback-Leiblerdivergence, is a measure of difference (or distance) between two distributions: one is the class label (i.e. reading levels); the other is the selected feature. • Chi-square (Chi) is a non-parametric statistical measureof correlation (or dependence) between two distributions: one is the class label; the other is the selected feature.
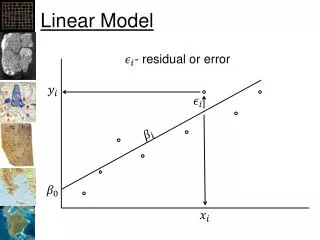
Linear Model Incorporating Feature Ranking -- Linear Regression Models • Linear regression is used to model the relationship between a scalar variable and multiple dependent (or explanatory) factors. • In LiFR, we use both linear regression and log-linear regression to grasp the relationship between reading levels and selected high rank features. • A linear regression model (LR) computes the reading level (or readability score) of a document by a linear function of the selected feature values collected from the document, while a logarithmic linear regression model (LogLR) computes the readability score by a log-linear function.
Empirical Study • RQ1. Based on the designed text features, whether the linear regression models can have comparable performance to other commonly used machine learning methods (e.g. SVR) for readability assessment of Chinese documents. • RQ2. For LiFR, whether feature ranking can further improve the performance of the linear models, and what is the effect of selected feature set size on readability assessment.
Empirical Study-- Readability Corpus • For readability assessment of Chinese, we collect the commonly used textbooks in mainland China, from grade 1 to grade 6 of primary schools. • Totally we get 637 documents, which are nearly balanced among the six reading (grade) levels.
Empirical Study -- Experimental Design • We use the ICTCLAS tool to perform both word segmentation and POS tagging of the sentences in a document. Besides, we use the Stanford Parser Kit to build one parse tree for each sentence. • The training set consists 90% of documents in each level, and the rest 10% goes to the test set. • The process is repeated 100 times to get statistically confident results. • RMSE measures the deviation between predicted levels and real ones. • Acc measures the ratio of documents which have been correctly predicted. As regression models usually give decimal predictions, ±Acc measures the ratio of predictions which fall in one level around the real ones.
Empirical Study -- Performance of Linear models (1/2) • For RQ1, firstly, we investigate the performance of both linear regression (LR) and log-linear regression (LogLR) with text features already used in available Chinese readability formulae. • Instead, we build both LR models and LogLR models with the three feature sets respectively, and measure the performance of each model based on our dataset. • This suggests that using more features do not always lead to better results.
Empirical Study -- Performance of Linear models (2/2) • As the LogLR model shows its superiority over the LR model for readability assessment, secondly, we build both models using all the designed features (Section 3.1), and compare them with SVR (Support Vector Machine for Regression). • This suggests that SVR cannot supersede the linear models for readability assessment. • On the other hand, it is not always true that the more the features used, the better the model performs. Some form of feature selection is essential in building good regression models.
Empirical Study -- Performance of LiFR(1/2) • For RQ2, We implement LiFRto explore whether feature ranking can further improve the performance of the linear models. • This suggests that feature selection maybe specific by the dataset used. • This suggests that either IG or Chi may not be a good choice for LogLR. • This confirms the above suggestion that both IG and Chi are not enough to get the best performance of LiFR.
Empirical Study -- Performance of LiFR(2/2) • As for the text features developed for Chinese, some of them are highly evaluated by the feature ranking techniques. • On the other hand, the top ranked features are not consistently selected, which suggests that the value of a feature may be dependent on both the ranking techniques and the dataset. • Above all, we can see that feature ranking is essential to improve the performance of linear regression models. • Decision has to be made to select the most appropriate metric for real-world cases.
Conclusions (1/2) • In this paper, we present a method which uses linear model incorporating feature ranking (LiFR), and develop four categories of text features to assess the readability of Chinese documents. • We build both LR and LogLRmodels on the designed text features, and compare them with the commonly used machine learning method SVM. • For LiFR, feature ranking can further improve the performance of linear models. The experimental results indicate that some form of feature selection is essential to build useful linear functions.
Conclusions (2/2) • Based on above, parts of our future work include designing new features for readability assessment, applying LiFR for different data sets and of different languages, and developing suitable methods for feature selection other than feature ranking.