Download

1 / 27
270 likes | 393 Views
A Storage Manager for Telegraph. Joe Hellerstein, Eric Brewer, Steve Gribble, Mohan Lakhamraju, Rob von Behren, Matt Welsh (mis-)guided by advice from Stonebraker, Carey and Franklin. Telegraph Elevator Pitch. Global-Scale DB: Query all the info in the world

E N D
A Storage Manager for Telegraph Joe Hellerstein, Eric Brewer, Steve Gribble, Mohan Lakhamraju, Rob von Behren, Matt Welsh (mis-)guided by advice from Stonebraker, Carey and Franklin
Telegraph Elevator Pitch • Global-Scale DB: Query all the info in the world • It’s all connected, what are we waiting for? • Must operate well under unpredictable HW and data regimes. • Adaptive shared-nothing query engine (River) • Continuously reoptimizing query plans (Eddy) • Must handle “live” data feeds like sensors/actuators • E.g. “smart dust” (MEMS) capturing reality • Not unlike Wall Street apps, but scaled way, way up. • Must work across administrative domains • Federated query optimization/data placement • Must integrate browse/query/mine • Not a new data model/query language this time; a new mode of interaction. • CONTROL is key: early answers, progressive refinement, user control online
Storage Not in the Elevator Pitch! • We plan to federate “legacy” storage • That’s where 100% of the data is today! • But: • Eric Brewer et al. want to easily deploy scalable, reliable, available internet services: web search/proxy, chat, “universal inbox” • Need some stuff to be xactional, some not. • Can’t we do both in one place?!! • And: • It really is time for two more innocents to wander into the HPTS forest. Changes in: • Hardware realities • SW engineering tools • Relative importance of price/performance and maintainability • A Berkeley tradition! • Postgres elevator pitch was about types & rules
Outline: Storage This Time Around • Do it in Java • Yes, Java can be fast (Jaguar) • Tighten the OS’s I/O layer in a cluster • All I/O uniform. Asynch, 0-copy • Boost the concurrent connection capacity • Threads for hardware concurrency only • FSMs for connection concurrency • Clean Buffer Mgmt/Recovery API • Abstract/Postpone all the hard TP design decisions • Segments, Versions and indexing on the fly?? • Back to the Burroughs B-5000 (“Regres”) • No admin trumps auto-admin. • Extra slides on the rest of Telegraph • Lots of progress in other arenas, building on Mariposa/Cohera, NOW/River, CONTROL, etc.
Decision One: Java has Arrived • Java development time 3x shorter than C • Strict typing • Enforced exception handling • No pointers • Many of Java’s “problems” have disappeared in new prototypes • Straight user-level computations can be compiled to >90% of C’s speed • Garbage collection maturing, control becoming available • The last, best battle: efficient memory and device management • Remember:We’re building a system • not a 0-cost porting story, 100% Java not our problem • Linking in pure Java extension code no problem
Jaguar • Two Basic Features in a New JIT: • Rather than JNI, map certain bytecodes to inlined assembly code • Do this judiciously, maintaining type safety! • Pre-Serialized Objects (PSOs) • Can lay down a Java object “container” over an arbitrary VM range outside Java’s heap. • With these, you have everything you need • Inlining and PSOs allow direct user-level access to network buffers, disk device drivers, etc. • PSOs allow buffer pool to be pre-allocated, and tuples I the pool to be “pointed at” Matt Welsh
Some Jaguar Numbers • Datamation Disk-to-Disk sort on Jaguar • 450 MHz Pentium IIs w/Linux, • Myrinet running JaguarVIA • peak b/w 488 Mbit/sec • One disk/node • Nodes split evenly between readers and writers • No raw I/O in Linux yet, scale up appropriately
Decision Two: Redo I/O API in OS • Berkeley produced the best user-level networking • Active Messages. NOW-Sort built on this. VIA a standard, similar functionality. • Leverage for both nets and disks! • Cluster environment: I/O flows to peers and to disks • these two endpoints look similar - formalize in I/O API • reads/writes of large data segments to disk or network peer • drop message in “sink”, completion event later appears on application-specified completion queue • disk and network “sinks” have identical APIs • throw “shunts” in to compose sinks and filter data as it flows • reads also asynchronously flow into completion queues Steve Gribble and Rob von Behren
completion queue completion queue completion event sink to network peer 2 peer 1 peer 1 sink to segment C sink to segment D sink to segment A sink to segment B disk disk Decision Two: Redo I/O API in OS Two implementations of I/O layer: • files, sockets, VM buffers • portable, not efficient, FS and VM buffer caches get in way • raw disk I/O, user-level network (VIA), pinned memory • non-portable, efficient, eliminates double buffering/copies
Finite State Machines • We can always build synch interfaces over asynch • And we get to choose where in the SW stack to do so: apply your fave threads/synchronization wherever you see fit • Below that, use FSMs • Web servers/proxies, cache consistency HW use FSMs • Want order 100x-1000x more concurrent clients than threads allow • One thread per concurrent HW activity • FSMs for multiplexing threads on connections • Thesis: we can do all of query execution in FSMs • Optimization = composition of FSMs • We only hand-code FSMs for a handful of executor modules • PS: FSMs a theme in OS research at Berkeley • The road to manageable mini-OSes for tiny devices • Compiler support really needed
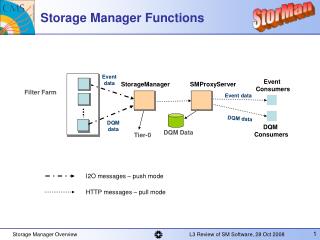
Application Lock Manager Segment Manager Trans Manager Recovery Manager Buffer Manager Decision 3: A Non-Decision “The New” Mohan (Lakhamraju), Rob von Behren Read Lock Update Unlock Scan Begin Commit Abort Deadlock Detect Pin Readaction Updateaction Unpin Recoveryaction Flush Commit/Abort-action
Tech Trends for I/O • “Bandwidth potential” of seek growing exponentially • Memory and CPU speed growing by Moore’s Law
Undecision 4: Segments? • Advantages of variable-length segments: • Dynamic auto-index: • Can stuff main-mem indexes in segment • Can delete those indexes on the fly • CPU fast enough to re-index, re-sort during read: Gribble’s “shunts” • Physical clustering specifiable logically • “I know these records belong together” • Akin to horizontal partitioning • Seeks deserve treatment once reserved for cross-canister decisions! • Plenty of messy details, though • Esp. memory allocation, segment split/coalesce • Stonebraker & the Burroughs B-5000: “Regres”
Undecision 5: Recovery Plan A • Tuple-shadows live in-segment • I.e. physical undo log records in-segment • Segments forced at commit • VIA force to remote memory is cheap, cheap, cheap • 20x sequential disk speed • group commits still available • can narrow the interface to the memory (RAM disk) • When will you start trusting battery-backed RAM? Do we need to do a MTTF study vs. disks? • Replication (Mirroring or Parity-style Coding) for media failure • Everybody does replication anyhow • SW Engineering win • ARIES Log->Sybase Rep Server->SQL? YUCK!! • Recovery = Copy. • A little flavor of Postgres to decide which version in-segment is live. “The New” Mohan, Rob von Behren
Undecision 5’: Recovery Plan B • Fixed-len segments (a/k/a blocks) • ARIES • to some degree of complexity • Performance study vs. Plan A • Is this worth our while?
More Cool Telegraph Stuff: River • Shared-Nothing Query Engine • “Performance Availability”: • Take fail-over ideas but convert from binary (master or mirror) to continuous (share the work at the appropriate fraction): • provides robust performance in the presence of performance variability • Key to a global-scale system: hetero hardware, changing workloads over time. • Remzi Arpaci-Dusseau and pals • Came out of NOW-Sort work • Remzi off to be abused by DeWitt & co.
Q River, Cont.
More Cool Telegraph Stuff: Eddy • How to order and reorder operators over time • key complement to River: adapt not only to the hardware, but to the processing rates • Two scheduling tricks: • Back-pressure on queues • Weighted lottery • Ron Avnur (now at Cohera)
Q More Cool Telegraph Stuff: Eddy • How to order and reorder operators over time • key complement to River: adapt not only to the hardware, but to the processing rates • Two scheduling tricks: • Back-pressure on queues • Weighted lottery • Ron Avnur (now at Cohera)
More Telegraph Stuff: Federation • We buy the Cohera pitch • Federation = negotiation + incentives • economics is a reasonable metaphor • Mariposa studied federated optimization inches deep • Way better than 1st-generation distributed DBs • And their “federation” follow-ons (Data Joiner, etc.) • But economic model assumes worst-case bid fluctuation • Two-phase optimization a tried-and-true heuristic from a radically different domain • We want to think hard about architecture, and tradeoff between cost guesses and a requests for bid Amol Deshpande
More Telegraph: CONTROL UIs • None of the paradigms for web search work • Formal queries (SQL) too hard to formulate • Keywords too fuzzy • Browsing doesn’t scale • Mining doesn’t work well on its own • Our belief: need a synergy of these with a person driving • Interaction key! • Interactive Browsing/Mining feed into query composition process • And loop with it
Step 1: Scalable Spreadsheet • Working today: • Query building while seeing records • Transformation (cleaning) ops built in • Split/merge/fold/re-format columns • Note that records could be from a DB, a web page (unstructured or semi), or could be the result of a search engine query • Merging browse/query • Interactively build up complex queries even over weird data • This is detail data. Apply mining for roll up • clustering/classification/associations Shankar Raman
Now Imagine Many of These • Enter a free-text query, get schemas and web page listings back • Fire off a thread to start digging into DB behind a relevant schema • Fire off a thread to drill down into relevant web pages • Cluster results in various ways to minimize info overload, highlight the wild stuff • User can in principle control all pieces of this • Degree of rollup/drill • Thread weighting (a la online agg group scheduling) • Which leads to pursue • Relevance feedback • All data flow, natural to run on River/Eddy! • How to do CONTROL in economic federation • Pay as you go actually nicer than “bid curves”
More? • http://db.cs.berkeley.edu/telegraph • {jmh,joey}@cs.berkeley.edu