Download

1 / 35
350 likes | 382 Views
Learn about generating data cubes from relational databases, overcome memory constraints, review parallel results, sequential algorithms, and our top-down parallel approach. Explore optimizations and a variety of data cube generation algorithms. Find out how to efficiently solve this intensive computational problem.

E N D
Generating the Data Cube(Shared Disk) Andrew Rau-ChaplinFaculty of Computer ScienceDalhousie University Joint Work withF. DehneT. EavisS. Hambrusch
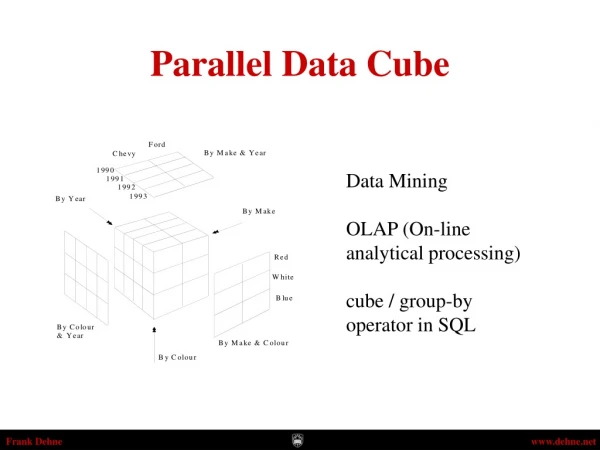
A B C Data Cube Generation ABC • Proposed by Gray et al in 1995 • Can be generated from a relational DB but… AC BC AB 34 12 21 18 21 B A C 83 38 50 The cuboid ABC (or CAB) ALL
Model Year Colour Sales Chevy 1990 Red 5 Chevy 1990 Blue 87 Ford 1990 Green 64 Ford 1990 Blue 99 Ford 1991 Red 8 Ford 1991 Blue 7 Model Year Colour Sales Chevy 1990 Blue 87 Chevy 1990 Red 5 Chevy 1990 ALL 92 Chevy ALL Blue 87 Chevy ALL Red 5 Chevy ALL ALL 92 Ford 1990 Blue 99 Ford 1990 Green 64 Ford 1990 ALL 163 Ford 1991 Blue 7 Ford 1991 Red 8 Ford 1991 ALL 15 Ford ALL Blue 106 Ford ALL Green 64 Ford ALL Red 8 ALL 1990 Blue 186 ALL 1990 Green 64 ALL 1991 Blue 7 ALL 1991 Red 8 Ford ALL ALL 178 ALL 1990 ALL 255 ALL 1991 ALL 15 ALL ALL Blue 193 ALL ALL Green 64 ALL ALL Red 13 ALL ALL ALL 270 As a table
The Challenge • Input data set, R • |R| typically in the millions, usually will not fit into memory. • Number of dimensions, d, 10-30 • 2d cuboids in Data Cube How to solve this highly data and computational intensive problem in parallel?
Existing Parallel Results • Goil & Choudhary • MOLAP • Approach • Parallelize the generation of each cuboid • Challenge • > 2d comm. rounds
Overview • Data cubes • Review sequential cubing algorithms • Our Top-down parallel algorithm • Conclusions and open problems
ABCD ABC ABD ACD BCD AC AB AD BC BD CD A A B B C C D D All Optimizations based on computing multiple cuboids • Smallest-parent - computing a cuboid from the smallest previously computed cuboid. • Cache-results - cache in memory the results of a cuboid from which other cuboid are computed to reduce disk I/O. • Amortize-scans - amortizing disk read by computing as many cuboid as possible. • Share-sorts - sharing sorting cost.
Many Algorithms • Pipesort – [AADGNRS’96] • PipeHash – [SAG’96] • Overlap – [DANR’96] • ArrayCube – [ZDN’97] • Bottom-up-cube – [BR’99] • Partition Cube – [RS’97] • Memory Cube - [RS’97]
Approaches • Top Down • Pipesort – [AADGNRS’96] • PipeHash – [SAG’96] • Overlap – [DANR’96] • Bottom up • Bottom-up-cube – [BR’99] • Partition Cube – [RS’97] • Memory Cube - [RS’97] • Array Based • ArrayCube – [ZDN’97]
Our results • A framework for parallelization of existing sequential data cube algorithms • Top-down • Bottom-up • Array based • Architecture independent • Communication efficient • Avoids irregular communication patterns • Few large messages • Overlap computation and communication • Today’s Focus • Top down approach
ABCD ABC ABD ACD BCD AC AB AD BC BD CD A A B B C C D D All Top Down Algorithms • Find a “least cost” spanning tree • Use estimators of cuboid size • Exploit • Data shrinking • Pipelining • Cuts vs. Sorts
Cut vs. Sort • Ordering ABCD • Cutting • ABCD -> ABC • Linear time • Sorting • ABCD ->ABD • Sort time • Size • ABC may be much smaller than ABCD
Pipesort [AADGNRS’96] • Minimize sorting while seeking to compute cuboid from smallest parent • Pipeline sorts with common prefixes
Level-by-level Optimization • Minimum cost matching in a bipartite graph • Scan edges solid, Sort edges dashed • Establish dimension ordering working up the lattice
Overview • Data cubes • Review sequential cubing algorithms • Our Top-down parallel algorithm • Conclusions and open problems
Top-down parallel: The Idea • Cut the process tree into p “equal weight” subtrees • Each Proc. generates cuboids from a subtree independently • Load balance/stripe the output CBAD CBA BAD ACD BCD AC BA AD CB DB CD A A B B C C D D All
The Basic Algorithm (1) Construct a lattice housing all 2d views. (2) Estimate the size of each of the views in the lattice. (3) To determine the cost of using a given view to directly compute its children, use its estimated size to calculate (a) the cost of scanning the view and (b) the cost of sorting it. (4) Using the bipartite matching technique presented in the original IBM paper, reduce the lattice to a spanning tree that identifies the appropriate set of prefix-ordered sort paths. (5) Add the I/O estimates to the spanning tree. (6) Partition the tree into p sub-trees. (7) Distribute the sub-tree lists to each of the p compute nodes. (8) On each node, use the sequential Pipesort algorithm to build the set of local views.
Tree Partitioning • What does “Equal Weight” mean? • Want to minimize the max weight partition! • O(Rk(k + log d)+n) time - Becker, Perl and Schach ‘82 • O(n) time, Frederickson 1990 time
Tree Partitioning • Min-max tree k-partitioning. • Given a tree T with n vertices and a positive weight assigned to each vertex, delete k edges in the tree to obtain k connected components T1, T2, … Tk+1 such that the largest total weight of a resulting sub-tree is minimized. • O(Rk(k + log d)+n) time - Becker, Perl and Schach ‘82 • O(n) time, Frederickson 1990
Dynamic min-max Raw data 125 125 ABC 15 47 15 AB BC 125 8 A
p subtrees s * p subtrees p subsets Over-sampling
Implementation Issues • 1) Sort Optimization • 2) Minimizing Data Movement • 3) Efficient Aggregation Operations • 4) Disk Optimizations
1) Sort Optimization • qSort is SLOW • May be O(n2) when there are duplicates • When cardinality is small range of keys is small Radix sort • Dynamically select between well optimized Radix and Quick Sorts
2) Minimizing Data Movement Never reorder the columns Sort pointers to the records!
3) Efficient Aggregation Operations • One pass for each pipeline • Do lazy aggregation ABCD ABC AB A all
4) Disk Optimizations • Avoid OS buffering • Implemented I/O Manager • Manages buffers to avoid thrashing • Does I/O in separate process to overlap with computation
Conclusions • New communication efficient parallel cubing framework for • Top-down • Bottom up • Array based • Easy to implement (sort of), architecture independent
Thank you! • Questions?