Download
1 / 11
120 likes | 322 Views
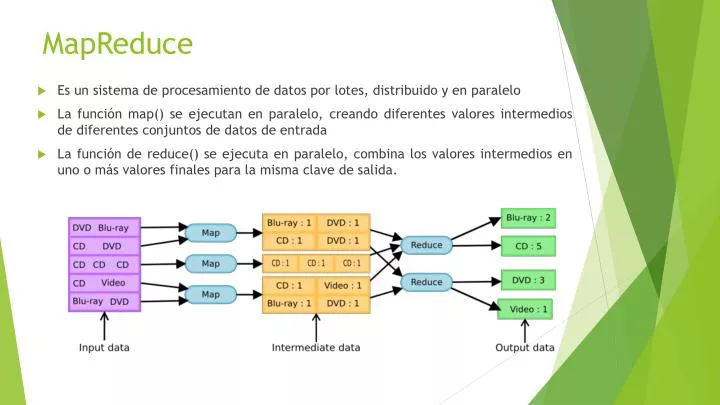
MapReduce. Es un sistema de procesamiento de datos por lotes, distribuido y en paralelo La función map () se ejecutan en paralelo, creando diferentes valores intermedios de diferentes conjuntos de datos de entrada

E N D
MapReduce • Es un sistema de procesamiento de datos por lotes, distribuido y en paralelo • La función map() se ejecutan en paralelo, creando diferentes valores intermedios de diferentes conjuntos de datos de entrada • La función de reduce() se ejecuta en paralelo, combina los valores intermedios en uno o más valores finales para la misma clave de salida.
MapReduce • Se deben implementar dos interfaces: map(key, value) -> (inter_key, inter_value) list reduce (inter_key, inter_value list) -> (out_key, out_value) list • Se tienen un JobTracker maestro y un TaskTrakeresclavo por nodo El maestro es responsable de la programación de tareas en los esclavos, su seguimiento y volver a ejecutar las tareas fallidas. Los esclavos ejecutan las tareas según las instrucciones del maestro. • La configuración del Job contiene mínimamente: • el directorio de los archivos de entrada • el directorio donde quedaran los archivos de salida, • el nombre del programa que ejecutara las tareas de mapeo y reducción, • los nombres de las funciones o de las clases de map y de reduce.
EJEMPLO CONTAR PALABRAS Una sencilla aplicación que cuenta el número de ocurrencias de cada palabra en un conjunto de entrada. http://www.cloudera.com/content/cloudera/en/resources/library/training/introduction-to-apache-mapreduce-and-hdfs.html
CÓDIGO CONTAR PALABRAS: MAP publicstatic class Mapextends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { String line = value.toString(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); output.collect(word, one); } } } El método de mapprocesa una línea a la vez. divide la línea en tokens separados por espacios en blanco, a través de la StringTokenizer, Emite un par clave-valor <<palabra>, 1>.
CÓDIGO CONTAR PALABRAS CON COMBINER. En la configuración del job se adiciona como parámetro la siguiente instrucción. conf.setCombinerClass(Reduce.class); El efecto en el proceso WordCount es entregar un consolidad local de ocurrencias de cada palabra. < Hello, 1> < World, 1> < Bye, 1> < World, 1> < Bye, 1> < Hello, 1> < World, 2>
CÓDIGO CONTAR PALABRAS: REDUCE public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> { public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { int sum = 0; while (values.hasNext()) { sum += values.next().get(); } output.collect(key, new IntWritable(sum)); } } La implementación reductor, a través del método de reduce suma los valores, que son las sumas locales entregadas por la fase anterior.
CÓDIGO CONTAR PALABRAS:JOBCONF public static void main(String[] args) throws Exception { JobConfconf = new JobConf(WordCount.class); conf.setJobName("wordcount"); conf.setOutputKeyClass(Text.class); conf.setOutputValueClass(IntWritable.class); conf.setMapperClass(Map.class); conf.setCombinerClass(Reduce.class); conf.setReducerClass(Reduce.class); conf.setInputFormat(TextInputFormat.class); conf.setOutputFormat(TextOutputFormat.class); FileInputFormat.setInputPaths(conf, new Path(args[0])); FileOutputFormat.setOutputPath(conf, new Path(args[1])); JobClient.runJob(conf); } JobConf: Es la interfaz principal para establecer los parámetros de configuración del trabajo de MapReduce, como paths de archivos de entrada y salida, la clase de mapeo y de reducción, etc. Algunos de estos parámetros se pasan por consola (línea de comandos) o por la GUI en propiedades del job.
CÓDIGO CONTAR PALABRAS: EJECUCIÓN POR CONSOLA • Ejecución del proceso: $ bin/hadoop jar /usr/joe/wordcount.jar org.myorg.WordCount /usr/joe/wordcount/input /usr/joe/wordcount/output • bin/hadoop Indica que es un proceso hadoop. • jar Indica el tipo de lenguaje del programa principal (java). • /usr/joe/wordcount.jar Nombre del programa a ejecutar • org.myorg.WordCountNombre clase donde está el main del programa. • $/usr/joe/wordcount/input Ruta del directorio de los archivos de entrada en HDFS • $/usr/joe/wordcount/output Ruta del directorio de los archivos de salida enHDFS
EJECUCIÓN DEL CÓDIGO CONTAR PALABRASPOR INTERFAZ GRAFICA (HUE)
EJECUCIÓN DEL CÓDIGO CONTAR PALABRASPOR INTERFAZ GRAFICA (HUE)
BIBLIOGRAFÍA http://vimeo.com/3584536 http://archive.cloudera.com/cdh/3/hadoop/mapred_tutorial.html#Source+Code http://archive.cloudera.com/cdh/3/hadoop/api/org/apache/hadoop/mapred/Mapper.html http://archive.cloudera.com/cdh/3/hadoop/api/org/apache/hadoop/mapred/Reducer.html http://archive.cloudera.com/cdh/3/hadoop/api/org/apache/hadoop/mapred/JobConf.html http://java.dzone.com/articles/running-hadoop-mapreduce






















