Download

1 / 26
270 likes | 615 Views
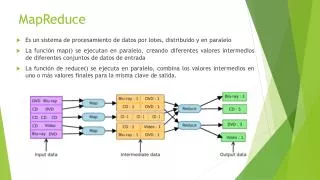
MapReduce. Hadoop MapReduce 過程淺 析 Reporter:Yu Shu Chiou. MapReduce. MapReduce. File 待處理的 文件 : 文件 儲存 在 HDFS 中, 每 個 文件 切分成 多 個 一定 大小 ( 預設值為 64M )的 Block ( 預設 3 個備份 ) 儲存 在多 個節點 ( DataNode )上。 文件 數據 内 容: This is a mapreduce ppt <br> This is a mapreduce ppt <br> ……. MapReduce.

E N D
MapReduce HadoopMapReduce 過程淺析 Reporter:YuShuChiou
MapReduce • File 待處理的文件: • 文件儲存在HDFS中,每個文件切分成多個一定大小(預設值為64M)的Block(預設3個備份)儲存在多個節點(DataNode)上。 • 文件數據内容: • This is a mapreduceppt\n • This is a mapreduceppt\n • ……
MapReduce • InputFormat: • 數據格式定義,如以“\n”分隔每一條紀錄,以” ”(空格) 區分一個目標單詞。 • “This is a mapreduceppt\n”為一條記錄 • “this”“is”等 為一個目標單詞
MapReduce • Split: • inputSplit是map函數的輸入 • 邏輯概念,一個inputSpilt和Block是默認1對1關係,可以是1對多(多對1呢?) • 實際上,每個split實際上包含後一個Block中開頭部分的數據(解決紀錄跨Block問題) • 比如記錄“This is a mapreduceppt\n”跨越儲存在兩個Block中,那麼這條記錄屬於前一個Block對應的split
MapReduce • RecordReader: • 每讀取一條記錄,調用一次map函數。 • 比如讀取一條記錄“This is a mapreduceppt”v,然後作為參數值v,調用map(v). • 然後繼續這個過程,讀取下一條記錄直到split尾。
MapReduce • Map函數: • function map(record v): • for word in v: • collect(word,1)//{“word”:1} • 調用執行一次 map(“This is a mapreduceppt” ) • 在内存中增加數據: • {“this”:1} • {“is ”:1} • {“a”:1} • {“mapreduce”:1} • {“ppt”:1}
MapReduce • Shuffle: • Partition,Sort,Spill,Merger,Combiner,Copy,Memory,Disk…… • 神奇發生的地方 • 也是性能優化大有可為的地方
MapReduce • Partitioner: • 決定數據由哪個Reducer處理,從而分區 • 比如採用hash法,有n個Reducer,那麼對數據{“This”:1}的key“This”對n取模,返回m,而該數據由第m個Reducer處理: • 生成 {partition,key,value} • {“This”:1} {“m”,“This”:1}
MapReduce • MemoryBuffer: • 内存緩衝區,每個map的結果和partition處理的Key Value結果都保存在緩存中。 • 緩衝區的大小:預設值為100M • 溢寫閾值:100M*0.8 = 80M • 緩衝中的數據:key-valueListpairs數據組 • {“this”:[1,1]} • {“is ”:1} • …… • {“otherword”:1} Step2: partition
MapReduce • Spill: • 内存緩衝區達到閾值時,溢寫spill線程鎖住這80M緩衝區,開始將數據寫出到本地磁碟中,然後釋放內存。 • 每次溢寫都生成一個數據文件。 • 溢出數據到磁碟前會對數據進行key排序Sort, 以及合併Combiner • 發送到相同Reduce的key數據,會併接在一起,減少partition的索引數量。 Step2: partition
MapReduce • Sort: • 緩衝區數據按照key進行排序 • {“1”,“this”:1} • {“2”,“is ”:1} • …… • {“1”,“this”:1} • {“1”,“otherword”:1} • {“1”,“this”:1} • {“1”,“this”:1} • {“1”,“otherword”:1} • …… • {“2”,“is”:1} Step2: partition
MapReduce • Combiner: • 數據合併,相同的key的數據,value值合併,可以減少數據量。 • Combine函數事實上就是reduce函數,在滿足combine處理不影響(sum,max等)最終reduce的結果時,可以極大的提供性能。 • {“1”,“this”:1} • {“1”,“this ”:1} • {“1”,“otherword”:1} • {“1”,“this”:2} • {“1”,“otherword”:1} Step2: partition
MapReduce • Spill to disk: 溢寫到硬碟 • 每次將内存緩衝區的數據溢寫到本地硬碟的時候都生成一個溢寫文件。 • 溢寫文件中,相同partition的數據順序儲存一塊,如圖中,則是三塊,說明對應有三個reducer。
MapReduce • Merge on disk: • Map結束後,需要合併多次溢寫生成的文件及内存中的數據(完成時未需溢寫的數據),生成一個map輸出文件。Partition相同的數據連續儲存。 • 數據合併為group: • 溢寫文件1{“this”:2} • 溢寫文件2{“this”:3} • 合併文件 {“this”:[2,3]} • group:{key:[value1……]}是 reduce函數的輸入數據格式 • 如果設置了combiner,則合併相同value • {“this”:[5]}
MapReduce Map task 结果: Map任務上的輸出就是按照partition和key排序的group數據儲存文件。 一個mapreduce作業中,一般都有多個map task,每個task都有一個輸出文件 {key1:[value1……]} {key2:[value1……]} ……
MapReduce Copy: Copy數據到reduce端 reduce端,讀取map端的輸出文件數據,從所有的map節點端中copy自己相對應的partition的那部分數據到内存中。比如key“this” 和“other” 都對應reducer1,那麼reducer1中的内存中將儲存數據如: {“this”,[2,2,3,1]} {“other”,[10,2,3,4]} …… {“this”,[3,2,4]} 這些數據來自於多個map端,key都屬於同一個partition。
MapReduce • Spill: 溢寫 • 和map端一樣,内存緩衝滿時,也通過sort和combiner,將數據溢寫到硬碟文件中。 • reduce端的緩存設置更靈活,此時reduce函數未運行,也可以占用較大的内存
MapReduce sort: 排序 {“this”,[2,2,3,1]} {“other”,[10,2,3,4]} …… {“this”,[3,2,4]} {“this”,[2,2,3,1]} {“this”,[3,2,4]} …… {“other”,[10,2,3,4]}
MapReduce combiner: 如果combiner不影響reduce結果,則設置combiner可以對數據進行合併,輸出到硬碟文件中。 {“this”,[2,2,3,1]} {“this”,[3,2,4]} …… {“other”,[10,2,3,4]} {“this”,[8]} {“this”,[9]} …… {“other”,[19]}
MapReduce merge: 讀取並將多個溢出的文件數據,合併成一個文件,作為reduce({key,[v……]})的輸入 {“this”,[8]} {“this”,[9]} …… {“other”,[19]} {“this”,[3]} {“this”,[10]} …… {“task”,[6]} {“this”,[8,9,3,10]} …… {“task”,[6]} {“other”,【19】}
MapReduce Reduce函數: function reduce({key,v[]}): for value in v: collectAdd(key,value) {“this”,[8,9,3,10]} …… {“task”,[6,2,5]} {“other”,【19,3】} {“this”,[30]} …… {“task”,[13]} {“other”,【22】}
MapReduce • Reduce結果: • 多個reduce任務輸出的數據都屬於不同的partition,因此結果數據的key不會重複。 • 合併reduce的輸出文件即可得到最终的wordcount結果。
MapReduce Langyu’s Blog:http://langyu.iteye.com/blog/992916
MapReduce Thanks ! @Original Author:Liou @Email: snakebbf@gmail.com @Blog: www.topdigger.tk