Download

1 / 33
330 likes | 456 Views
Web search basics. Web Challenges for IR. Distributed Data : Documents spread over millions of different web servers. Volatile Data : Many documents change or disappear rapidly (e.g. dead links). Large Volume : Billions of separate documents.

E N D
Web Challenges for IR • Distributed Data: Documents spread over millions of different web servers. • Volatile Data: Many documents change or disappear rapidly (e.g. dead links). • Large Volume: Billions of separate documents. • Unstructured and Redundant Data: No uniform structure, HTML errors, up to 30% (near) duplicate documents. • Quality of Data: No editorial control, false information, poor quality writing, typos, etc. • Heterogeneous Data: Multiple media types (images, video, VRML), languages, character sets, etc.
Sec. 19.2 The Web The Web document collection • No design/co-ordination • Distributed content creation, linking, democratization of publishing • Content includes truth, lies, obsolete information, contradictions … • Unstructured (text, html, …), semi-structured (XML, annotated photos), structured (Databases)… • Scale much larger than previous text collections • Growth – slowed down from initial “volume doubling every few months” but still expanding • Content can be dynamically generated
Web Spider Document corpus Query 1. Page1 2. Page2 3. Page3 . . Ranked Documents Web Search Using IR IR System
Brief history • Early keyword-based engines ca. 1995-1997 • Altavista, Excite, Infoseek, Inktomi, Lycos • Paid search ranking: • Your search ranking depended on how much you paid. • 1998+: Link-based ranking pioneered by Google • Google added paid search “ads” to the side, independent of search results
Paid Search Ads Algorithmic results.
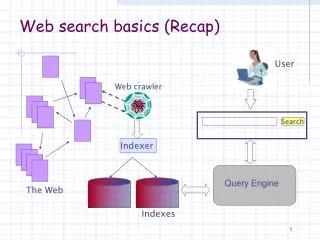
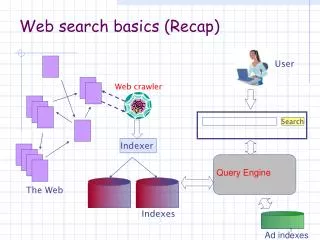
Sec. 19.4.1 User Web spider Search Indexer The Web Indexes Ad indexes Web search basics
Sec. 19.4.1 Seattle weather Mars surface images Canon S410 User Needs • Informational – want to learn about something • Navigational – want togo to that page • Transactional – want to do something (web-mediated) • Access a service • Downloads • Shop • Gray areas • Find a good hub • Exploratory search “see what’s there” Low hemoglobin United Airlines Car rental Brasil
How far do people look for results? (Source: iprospect.com WhitePaper_2006_SearchEngineUserBehavior.pdf)
Users’ empirical evaluation of results • Quality of pages • Relevance • Other desirable qualities (non IR) • Content: Trustworthy, diverse, non-duplicated, well maintained • Web readability: display correctly & fast • No annoyances: pop-ups, etc. • Precision vs. recall • On the web, recall seldom matters • Recall matters when the number of matches is very small • Comprehensiveness – must be able to deal with obscure queries • User perceptions may be unscientific, but are significant
Users’ empirical evaluation of engines • Relevance and validity of results • UI – Simple, no clutter, error tolerant • Trust – Results are objective • Pre/Post process tools provided • Mitigate user errors (auto spell check, search assist,…) • Explicit: Search within results, more like this, refine ... • Anticipative: related searches • Deal with idiosyncrasies • Web specific vocabulary • Impact on stemming, spell-check, etc. • Web addresses typed in the search box
Sec. 19.6 Spidering
Spiders (Robots/Bots/Crawlers) • Web crawling is the process by which we gather pages from the Web. • Start with a comprehensive set of root URL’s from which to start the search. • Follow all links on these pages recursively to find additional pages. • Must obey page-owner restrictions: robot exclusion.
Spidering Algorithm Initialize queue (Q) with initial set of known URL’s. Until Q empty or page or time limit exhausted: Pop URL, L, from front of Q. If L is not to an HTML page (.gif, .jpeg, .ps, .pdf, .ppt…) continue loop. If already visited L, continue loop. Download page, P, for L. If cannot download P (e.g. 404 error, robot excluded) continue loop. Index P (e.g. add to inverted index or store cached copy). Parse P to obtain list of new links N. Append N to the end of Q.
Queueing Strategy • How new links added to the queue determines search strategy. • FIFO (append to end of Q) gives breadth-first search. • LIFO (add to front of Q) gives depth-first search. • Heuristically ordering the Q gives a “focused crawler” that directs its search towards “interesting” pages.
Search Strategies Breadth-first Search
Search Strategies (cont) Depth-first Search
Avoiding Page Re-spidering • Must detect when revisiting a page that has already been spidered (web is a graph not a tree). • Must efficiently index visited pages to allow rapid recognition test. • Index page using URL as a key. • Must canonicalize URL’s (e.g. delete ending “/”) • Not detect duplicated or mirrored pages. • Index page using textual content as a key. • Requires first downloading page.
Robot Exclusion • Web sites and pages can specify that robots should not crawl/index certain areas. • Two components: • Robots Exclusion Protocol: Site wide specification of excluded directories. • Robots META Tag: Individual document tag to exclude indexing or following links.
Robots Exclusion Protocol • Site administrator puts a “robots.txt” file at the root of the host’s web directory. • http://www.ebay.com/robots.txt • http://www.cnn.com/robots.txt • File is a list of excluded directories for a given robot. • Exclude all robots from the entire site: User-agent: * Disallow: /
Robot Exclusion Protocol Examples • Exclude specific directories: User-agent: * Disallow: /tmp/ Disallow: /cgi-bin/ Disallow: /users/paranoid/ • Exclude a specific robot: User-agent: GoogleBot Disallow: / • Allow a specific robot: User-agent: GoogleBot Disallow: User-agent: * Disallow: /
Keeping Spidered Pages Up to Date • Web is very dynamic: many new pages, updated pages, deleted pages, etc. • Periodically check spidered pages for updates and deletions: • Just look at header info (e.g. META tags on last update) to determine if page has changed, only reload entire page if needed. • Track how often each page is updated and preferentially return to pages which are historically more dynamic. • Preferentially update pages that are accessed more often to optimize freshness of more popular pages.
Sec. 19.2.2 The trouble with paid search ads • It costs money. What’s the alternative? • Search Engine Optimization: • “Tuning” your web page to rank highly in the algorithmic search results for select keywords • Alternative to paying for placement • Thus, intrinsically a marketing function • Performed by companies, webmasters and consultants (“Search engine optimizers”) for their clients • Some perfectly legitimate, some very shady
Sec. 19.2.2 Simplest forms • First generation engines relied heavily on tf/idf • The top-ranked pages for the query Qom University were the ones containing the most Qom’s and University’s • SEOs responded with dense repetitions of chosen terms • e.g., Qom University Qom University Qom University • Often, the repetitions would be in the same color as the background of the web page • Repeated terms got indexed by crawlers • But not visible to humans on browsers Pure word density cannot be trusted as an IR signal
Sec. 19.2.2 Cloaking • Serve fake content to search engine spider
Sec. 19.2.2 More spam techniques • Doorway pages • Pages optimized for a single keyword that re-direct to the real target page • Link spamming • Fake links • Robots • Fake query stream – rank checking programs
Quality signals - Prefer authoritative pages based on: Votes from authors (linkage signals) Votes from users (usage signals) Policing of URL submissions Anti robot test Limits on meta-keywords Robust link analysis Ignore statistically implausible linkage (or text) Use link analysis to detect spammers (guilt by association) Spam recognition by machine learning Training set based on known spam Family friendly filters Linguistic analysis, general classification techniques, etc. For images: flesh tone detectors, source text analysis, etc. Editorial intervention Blacklists Top queries audited Complaints addressed Suspect pattern detection The war against spam
More on spam • Web search engines have policies on SEO practices they tolerate/block • http://help.yahoo.com/help/us/ysearch/index.html • http://www.google.com/intl/en/webmasters/ • Adversarial IR: the unending (technical) battle between SEO’s and web search engines • Research http://airweb.cse.lehigh.edu/
Sec. 19.6 DUPLICATE DETECTION
Sec. 19.6 Duplicate documents • The web is full of duplicated content • Strict duplicate detection = exact match • Not as common • But many, many cases of near duplicates • E.g., last-modified date the only difference between two copies of a page
Sec. 19.6 Duplicate/Near-Duplicate Detection • Duplication: Exact match can be detected with fingerprints • Near-Duplication: Approximate match • Compute syntactic similarity • Use similarity threshold to detect near-duplicates • E.g., Similarity > 80% => Documents are “near duplicates”
Sec. 19.6 Computing Similarity • Features: • Segments of a document • Shingles (Word N-Grams) • a rose is a rose is a rose → a_rose_is_a rose_is_a_rose is_a_rose_is a_rose_is_a • Similarity Measure between two docs (= sets of shingles) • Jaccard coefficient