Download

1 / 0
80 likes | 384 Views
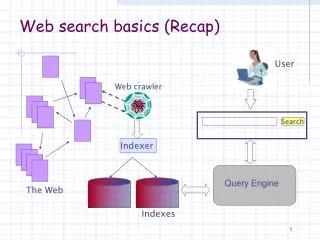
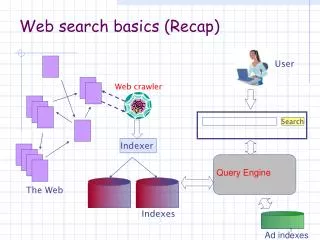
Ch19. Web search basics. 2010. 3. 22. 유 보 림. contents. 19.1 Background and history 19.2 Web characteristics 19.2.1 The web graph 19.2.2 Spam 19.3 Advertising as the economic model 19.4 User query needs 19.5 Index size and estimation 19.6 Near-duplicates and shingling.

E N D