Download

1 / 42
520 likes | 1.16k Views
UNIT - II Grammar Formalism: Chomsky hierarchy of languages Context free grammar Derivation trees and sentential forms Right most and leftmost derivation of strings Ambiguity in context free grammars Minimization of Context Free Grammars Chomsky normal form

E N D
UNIT - II Grammar Formalism: Chomsky hierarchy of languages Context free grammar Derivation trees and sentential forms Right most and leftmost derivation of strings Ambiguity in context free grammars Minimization of Context Free Grammars Chomsky normal form Greiback normal form Push down Automata: Push down automata, Definition Model Acceptance of CFL Acceptance by final state Acceptance by empty stack and its equivalence. Equivalence of CFL and PDA
Grammar: A Grammar is a 4 tuple : G= ( T , N , P,S ) T->Set of terminals N-> set of non terminals S->starting symbol P-> production rules in the form of → where , NT Depending on production rules the grammars are classified into 4 types: i) Unrestricted or Type 0 Grammar: In this the production rules are of the form → where , NT ii) Context Sensitive or Type1 Grammar: In this the production rules are of the form → where , NT and || || iii) Context Free or Type2 Grammar: In this the production rules are of the form A→ where NT, A N iv) Regular or Type3 Grammar: In this only one Non terminal is used at both left and right sides of the production Ex: A →a, A → Ba , A → aB
Context-Free Grammar The syntax of a programming language is specified by using Context Free Grammar (CFG). A CFG can be defined as G = { T,N,P,S} where T->Set of terminals N-> set of non terminals S->starting symbol P-> production rules in the form of A→ where A N , NT Notational Conventions: 1.Terminals: i) Lowercase letters early in the alphabets such as a, b ,c ii) Digits and special characters such as +,-,{,( 2. Non Terminals: i) Uppercase letters early in the alphabets like A,B,C ii) Lowercase italic names such as exp ,stmt … 3.Uppercase letters late in the alphabet X, Y, Z are use to represent grammar symbol i.e either terminal or non terminal 4. Lowercase Greek letters ,, are used to represent set of grammar symbols(strings).
Given a context-free grammar G = { T,N,P,S}, the language generated or derived from G is the set: L(G) = {w T*: S * w } Context-Free Languages • A language L is context-free if there is a context-free grammar G = { T,N,P,S}, such that L is generated from G. • Context-free grammars are more expressive than finite automata: if a language L is accepted by a finite automata then L can be generated by a context-free grammar • The converse is NOT true • Derivation • Based on the grammar, derivations can be made • The purpose of a grammar is to derive strings in the language defined by the grammar • , can be derived from in one step • + derived in one or more steps • * derived in any number of steps • lm leftmost derivation • Always substitute the leftmost non-terminal • rm rightmost derivation • Always substitute the rightmost non-terminal
Example CFG: G = ({S}, {0, 1}, P, S) P: (1) S –> 0S1 or just simply S –> 0S1 | ε (2) S –> ε • Example Derivations: S => 0S1 (1) S => ε (2) => 01 (2) S => 0S1 (1) => 00S11 (1) => 000S111 (1) => 000111 (2) • Note that G “generates” the language {0k1k | k>=0}
Example CFG: G = ({A, B, C, S}, {a, b, c}, P, S) P: (1) S –> ABC (2) A –> aA A –> aA | ε (3) A –> ε (4) B –> bB B –> bB | ε (5) B –> ε (6) C –> cC C –> cC | ε (7) C –> ε • Example Derivations: S => ABC (1) S => ABC (1) => BC (3) => aABC (2) => C (5) => aaABC (2) => ε (7) => aaBC (3) => aabBC (4) => aabC (5) => aabcC (6) => aabc (7) • Note that G generates the language a*b*c*
Sentential Form • may contain terminals and non-terminals • may be empty • sentence of G is a sentential form with no non-terminals • the language generated by a grammar is a set of sentences • L(G) – the language generated by G • a string of terminals w is in L(G) iff w is a sentence of G (S=>w)* The following CFG is for simple arithmetic expressions: E → E op E | ( E )| id op → + | - | * | | % | ( | ) From above production rules T={ ( , ) , id , + , - , * , % } N = { E, op } S = { E }
Derivation (Parse) Tree of A Context-free Grammar • Represents the language using an ordered rooted tree. • Root represents the starting symbol. • Internal vertices represent the nonterminal symbol that arise in the production. • Leaves represent the terminal symbols. • If the production A→w arise in the derivation, where w is a word, the vertex that represents A has as children vertices that represent each symbol in w, in order from left to right. S • Example: Let G = ({S,A,a,b},{a,b}, S,{S → aA, S → b, A → aa}). What is L(G)? • Draw a tree of all possible derivations. • We have: S aA aaa. • and S b. • Answer: L = {aaa, b}. b aA Example of aderivation treeor parse treeor sentence diagram. aaa
S A B A A b B a a b Leftmost, Rightmost Derivations - A left-most derivation of a sentential form is one in which rules transforming the left-most non terminal are always applied - A right-most derivation of a sentential form is one in which rules transforming the right-most nonterminal are always applied S A | A B A e | a | A b | A A B b | bc | B c | b B • Sample derivations: • S AB AAB aAB aaB aabB aabb • S AB AbB Abb AAbb Aabbaabb • These two derivations are special. • 1st derivation is leftmost. • Always picks leftmost variable. • 2nd derivation is rightmost. • Always picks rightmost variable.
Ambiguity in context free grammars The grammar A context-free grammar G is ambiguous, if some string wεL(G) has two or more derivation trees is ambiguous: string has two leftmost derivations take a = 2
Rewrite Ambiguous Grammar • Try to use a single recursive non terminal in each rule • When the left symbol appears more than once on the right side • Use additional symbols to substitute them and allow only one • Force to only allow one expansion • Example grammar • E E + E | E –E | E * E | E / E | (E) | id • It is ambiguous • Change to • E T + E | T –E | T * E | T / E | (E) | T • T id • Parse: id * id – id • E T * E T * T – E T * T – T … id * id – id E T E * id – T E T id id
Build desired precedence in the grammar • Example • E E + E | E * E | (E) | id • Ambiguous • Desired precedence: * executes before + • Change to E E + T | T T T * F | F F (E) | id • Parse id + id * id E + T E T * T F id F F id id
Minimization of Context Free Grammars Three ways to simplify/clean a CFG Eliminate useless symbols (clean) Eliminate -productions (simplify) Eliminate unit productions (simplify) Eliminating useless symbols A symbol X is reachableif there exists: • S * X A symbol X is generatingif there exists: • X * w, • for some w T* For a symbol X to be “useful”, it has to be both reachable and generating • S * X * w’, for some w’ T*
First, eliminate all symbols that are not generating Next, eliminate all symbols that are not reachable • SAB | a • A b • A, S are generating • B is not generating (and therefore B is useless) • ==> Eliminating B… (i.e., remove all productions that involve B) • S a • A b • Now, A is not reachable and therefore is useless • Simplified G: • S a
Eliminating -productions Theorem: If G=(V,T,P,S) is a CFG for a language L, then L-{} has a CFG without -productions Definition: A is “nullable” if A* If A is nullable, then any production of the form “B CAD” can be simulated by: B CD | CAD • Let L be the language represented by the following CFG G: • SAB • AaAA | • BbBB | Goal: To construct G1, which is the grammar for L-{} • Nullable symbols: {A, B} • G1 can be constructed from G as follows: • B b | bB | bB | bBB • ==> B b | bB | bBB • Similarly, A a | aA | aAA • Similarly, S A | B | AB • Note: L(G) = L(G1) U {} • G1: • S A | B | AB • A a | aA | aAA • B b | bB | bBB + • S
Eliminating Unit Productions • A unit production is one whose right side consists of exactly one variable. • These productions can be eliminated. • Key idea: If A =>* B by a series of unit productions, and B -> is a non-unit-production, then add production A -> . • Then, drop all unit productions.
Chomsky normal form • Method of simplifying a CFG Definition: A context-free grammar is in Chomsky normal form if every rule is of one of the following forms A BC A a where a is any terminal and A is any variable, and B, and C are any variables or terminals other than the start variable the rule S ε is permitted, where S is the start variable Any context-free language is generated by a context-free grammar in Chomsky normal form • Convert any CFG to one in Chomsky normal form by removing or replacing all rules in the wrong form • Add a new start symbol • Eliminate ε rules of the form A ε • Eliminate unit rules of the form A B • Convert remaining rules into proper form
Convert a CFG to Chomsky normal form • Add a new start symbol • Create the following new rule S0 S where S is the start symbol and S0 is not used in the CFG • Eliminate all ε rules A ε, where A is not the start variable • For each rule with an occurrence of A on the right-hand side, add a new rule with the A deleted • R uAv becomes R uAv | uv R uAvAw becomes R uAvAw | uvAw | uAvw | uvw • If we have R A, replace it with R ε unless we had already removed R ε • Eliminate all unit rules of the form A B • For each rule B u, add a new rule A u, where u is a string of terminals and variables, unless this rule had already been removed • Repeat until all unit rules have been replaced • Convert remaining rules into proper form • Replace each rule A u1u2…uk, where k 3 and ui is a variable or a terminal with k-1 rules A u1A1 A1 u2A2 … Ak-2 uk-1uk
Example Step 3: Eliminate all unit rules S0 S1b | Ab | b | S2a | Ba | a S S1b | Ab | b | S2a | Ba | a S1 S1b | Ab | b A aAb | ab S2 S2a | Ba | a B bBa | ba Step 4: Convert remaining rules to proper form S0 S1b | Ab | b | S2a | Ba | a S S1b | Ab | b | S2a | Ba | a S1 S1b | Ab | b A aA1 | ab A1 Ab S2 S2a | Ba | a B bB1| ba B1 Ba Convert the following grammar into Chomsky Normal Form. S S1 | S2 S1 S1b | Ab | ε A aAb | ab S2 S2a | Ba | ε B bBa | ba Step 1: Add a new start symbol S0 S S S1 | S2 S1 S1b | Ab A aAb | ab | ε S2 S2a | Ba B bBa | ba | ε Step 2: Eliminate ε rules S0 S S S1 | S2 S1 S1b | Ab| b A aAb | ab S2 S2a | Ba| a B bBa | ba
new Stack top(s) new state(s) Pushdown Automaton (PDA) Stack top old state input symb. δ : Q x x ∑ =>Q x • A Pushdown Automaton is a nondeterministic finite state automaton (NFA) that permits ε-transitions and a stack. • A PDA P is a seven tuple ( Q,∑,, δ,q0,Z0,F ): • Q: states of the PDA with ε • ∑: input alphabet • : stack symbols • δ: transition function • q0: start state • Z0: Initial stack top symbol • F: Final/accepting states
A Graphical Notation for PDA’s • The nodes correspond to the states of the PDA. • An arrow labeled Start indicates the unique start state. • Doubly circled states are accepting states. • Edges correspond to transitions in the PDA as follows: An edge labeled (ai, X)/Y from state q to state p means that d(q, ai, X) contains the pair (p, Y), perhaps among other pairs. δ(qi,a, X)={(qj,Y)} Next input symbol Current stacktop Stack Top Replacement (w/ string Y) Currentstate Nextstate a, X / Y qi qj
Example Let Lwwr = {wwR | w is in (0+1)*} • CFG for Lwwr : S==> 0S0 | 1S1 | • PDA for Lwwr : • P := ( Q,∑, , δ,q0,Z0,F ) = ( {q0, q1, q2},{0,1},{0,1,Z0},δ,q0,Z0,{q2}) First symbol push on stack δ(q0,0, Z0)={(q0,0Z0)} δ(q0,1, Z0)={(q0,1Z0)} δ(q0,0, 0)={(q0,00)} δ(q0,0, 1)={(q0,01)} δ(q0,1, 0)={(q0,10)} δ(q0,1, 1)={(q0,11)} δ(q0, , 0)={(q1, 0)} δ(q0, , 1)={(q1, 1)} δ(q0, , Z0)={(q1, Z0)} δ(q1,0, 0)={(q1, )} δ(q1,1, 1)={(q1, )} δ(q1, , Z0)={(q2, Z0)} Grow the stack by pushing new symbols on top of old(w-part) Switch to popping mode (boundary between w and wR) Shrink the stack by popping matching symbols (wR-part) Enter acceptance state
PDA for Lwwr: Transition Diagram ∑ = {0, 1} • = {Z0, 0, 1} Q = {q0,q1,q2} Grow stack 0, Z0/0Z0 1, Z0/1Z0 0, 0/00 0, 1/01 1, 0/10 1, 1/11 Pop stack for matching symbols 0, 0/ 1, 1/ q0 q1 q2 , Z0/Z0 , Z0/Z0 , 0/0 , 1/1 , Z0/Z0 Go to acceptance Switch to popping mode This would be a non-deterministic PDA
language of balanced paranthesis Pop stack for matching symbols ∑ = { (, ) } • = {Z0, ( } Q = {q0,q1,q2} Grow stack (, Z0 / ( Z0 ), (/ (, (/ ( ( q0 q1 q2 , Z0 / Z0 ), ( / , Z0 / Z0 , Z0 / Z0 Go to acceptance (by final state)when you see the stack bottom symbol Switch to popping mode (, ( / ( ( (, Z0 / ( Z0 To allow adjacentblocks of nested paranthesis
There are two types of PDAs that one can design: those that accept by final state or by empty stack Checklist: - input exhausted? - in a final state? • PDAs that accept by final state: • For a PDA P, the language accepted by P, denoted by L(P) by final state, is: • {w | (q0,w,Z0) |---* (q,, A) }, s.t., q F • PDAs that accept by empty stack: • For a PDA P, the language accepted by P, denoted by N(P) by empty stack, is: • {w | (q0,w,Z0) |---* (q, , ) }, for any q Q. PN: Checklist: - input exhausted? - is the stack empty? PF: (,Z0 / ( Z0 (, (/ ( ( ), (/ ,Z0 / (,Z0 / ( Z0 (,( / ( ( ), ( / Q) Does a PDA that accepts by empty stack need any final state specified in the design? ,Z0/ Z0 start start q0 q1 q0 ,Z0/ Z0 ,Z0/ Z0
Equivalence of Acceptance by Final State and Empty Stack Final State Empty Stack • A language is L(P1) for some PDA P1 if and only if it is N(P2) for some PDA P2. • Given P1 = (Q, , , , q0, Z0, F), construct P2: • Introduce new start statep0 and new bottom-of-stack markerX0. • First move of P2 : replace X0 by Z0X0 and go to state q0. The presence of X0 prevents P2 from "accidentally" emptying its stack and accepting when P1 did not accept. • Then, P2 simulates P1, i.e., give P2 all the transitions of P1. • Introduce a new state r that keeps popping the stack of P2 until it is empty. • If (the simulated) P1 is in an accepting state, give P2 the additional choice of going to state r on input, and thus emptying its stack without reading any more input.
, any/ , any/ , X0/Z0X0 New start , any/ q0 p0 pe … , any/ PF PF==> PN construction • Main idea: • Whenever PF reaches a final state, just make an -transition into a new end state, clear out the stack and accept • What if PF design is such that it clears the stack midway without entering a final state? to address this, add a new start symbol X0 (not in of PF) PN = (Q U {p0,pe}, ∑, U {X0}, δN, p0, X0) PN:
, X0/ X0 , X0/ X0 , X0/Z0X0 New start , X0/ X0 q0 p0 pf … , X0/ X0 Empty Stack Final State Given P2 = (Q, , , , q0, Z0, F), construct P1: • Introduce new start state p0 and new bottom-of-stack markerX0 • First move of P1 : replace X0 by Z0X0 and go to state q0. Then, P2 simulates P1, i.e., give P2 all the transitions of P1 • Introduce a new state r for P1, it is the only accepting state • P1 simulates P2 • If (the simulated) P1 ever sees X0 it knows P2 accepts so P1 goes to state r on input PF: PN: , X0 / X0 • PF = (QN U {p0,pf}, ∑, U {X0}, δF, p0, X0, {pf})
(,Z0 /Z1Z0 (,Z1 /Z1Z1 ),Z1 / ,Z0 / (,Z0/Z1Z0 (,Z1/Z1Z1 ),Z1/ ,Z0/ start ,X0/ X0 start ,X0/Z0X0 q0 q0 p0 pf Example: Matching parenthesis “(” “)” Pf:( {p0,q0 ,pf}, {(,)}, {X0,Z0,Z1}, δf, p0, X0 , pf) δf:δf(p0, ,X0) = { (q0,Z0) } δf(q0,(,Z0) = { (q0,Z1 Z0) } δf(q0,(,Z1) = { (q0, Z1Z1) } δf(q0,),Z1) = { (q0, ) } δf(q0, ,Z0) = { (q0, ) } δf(p0, ,X0) = { (pf, X0) } PN: ( {q0}, {(,)}, {Z0,Z1}, δN, q0, Z0 ) δN: δN(q0,(,Z0) = { (q0,Z1Z0) } δN(q0,(,Z1) = { (q0, Z1Z1) } δN(q0,),Z1) = { (q0, ) } δN(q0, ,Z0) = { (q0, ) } Accept by empty stack Accept by final state
Equivalence between CFGs and PDAs • Converting CFGs to PDAs • Easier to use PDA version that accepts by empty stack • Given a context free grammar G = (V,T,P,S), construct a pushdown automaton M • Need to specify states, input and stack symbols and the transition function • M = (Q, , , , q0, Z0), where • Q contains a single state, q0 • = T • = {V T} • Z0 = S • Note: no need for F (final states) since we are accepting by empty stack • Transition function is based on the variables, productions and terminals of the grammar: • (q0 ,є , A) = (q0, w) whenever A w • (q0 ,a , a) = (q0, є) for each a in T • Easier and more intuitive if the grammar is of GNF • (q0 ,a , A) = (q0, B1B2…Bn) for each productionA aB1B2…Bn
Every left-most derivation can be simulated in the PDA as follows: • Put S on the stack • Change variable on top of stack in accordance with next production • Read input to get to next variable on stack • If stack empty accept. Else, go to no. 2 On the other hand, every accepting computation must have gone through the steps above and so corresponds to a left-most derivation in G. This shows that the PDA constructed accepts the same language as the original grammar.
Example Design the PDA for the following grammar S a | aS | bSS | SSb | SbS PDA A = ({q},{a,b},{S,a,b},,q,,S) • is defined as (q,,S) = { (q,a),(q,aS),(q,bSS),(q,SSb),(q,SbS) } (q,a,a) = (q,) (q,b,b) = (q,) GeneratebSS Match b Generatea Match a Processing of baa S Generatea Match a b S S a a match match match b a a
From PDA’s to Grammars Let P = (Q, S, G, d, q0, Z0) be a PDA. Then there is a context-free grammar G such that L(G) = N(P). Construct G = (V, T, P, S) where the set of nonterminals consists of: • the special symbol S as the start symbol; • all symbols of the form [pXq] where p and q are states in Q and X is a stack symbol in G. The productions of G are as follows. (a) For all states p, G has the production S [q0Z0p]. (b) Let d(q, a, X) contain the pair (r, Y1Y2 … Yk), where • a is either a symbol in S or a = e; • k can be any number, including 0, in which case the pair is (r, e). Then for all lists of states r1, r2, …, rk, G has the production [qXrk] a[rY1r1][r1Y2r2]…[rk1Ykrk].
start e, Z/e i, Z/ZZ q Fig. 6.5 Convert the following PDA to a Context Free Grammar. Nonterminals include only two symbols, S and [qZq]. Productions: 1. S [qZq] (for the start symbol S); 2. [qZq] i[qZq][qZq] (from (q, ZZ)dN(q, i, Z)) 3. [qZq] e (from (q, e)dN(q, e, Z)) • If we replace [qZq] by a simple symbol A, then the productions become • 1. SA • 2. AiAA • 3. Ae • Obviously, these productions can be simplified to be • 1. SiSS • 2. Se • And the grammar may be written simply as • G = ({S}, {i, e}, {SiSS | e}, S)
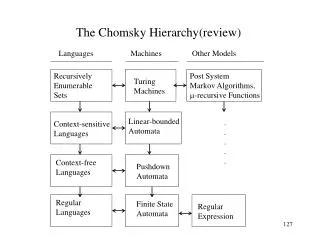
Assignment - 2 • Explain in detail about Chomsky’s Hierarchy with neat diagram. • Define the language for the following Context Free Grammars. • (a) S → 0 S 1 | 01 • (b) S → a S a | b S b | ε • 3. Construct Leftmost parse tree and Rightmost parse tree for the following • grammar and the given string ,if the grammar is ambiguous write equivalent unambiguous grammar. • R → R + R | RR|(R) |R* |a | b • String : (ab+ba)* • 4. Minimize the following Context Free Grammar. • S → ABC| BaB • A → Aa | BaC|aaa • B → bBb | a |D • C → CA | AC • D → ε • Convert the following Context Free Grammar to Chomsky Normal Form. • S → bA | aB • A → bAA | aS | a • B → aBB | bS | b
6. Convert the following Context Free Grammar to Greibach Normal Form. S → XA | BB B → b | SB X → b A → A 7. Compare Finite automata and Push Down Automata in detail with examples and diagrams. 8. Design a PDA whose language is { w | w contains balanced parenthesis} 9. Consider the grammar S → abScB | λ B → bB | b What language does it generate? 10. Design PDA for Binary strings that start and end with the same symbol and have the same number of 0s as 1s. 11. Convert the PDA for the language { wwR| w ∈ {0, 1}∗} into CFG. 12. Construct the PDA for the following CFG. G = ({S, T}, {a, b}, {S → aT b | b, T → T a | ∈ }, S).