Download

1 / 24
250 likes | 566 Views
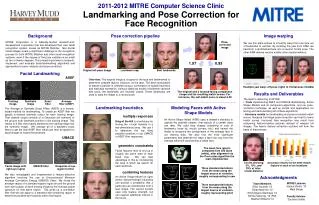
Active Shape Model Their Training and Application. 吕玉生 2007.12.27. Overview. TRAINING Shape training Gray level training APPLICATION Image Search. TRAINING. Shape training Aligning the training set Aligning two shapes Aligning all shapes Capturing the statistics.

E N D
Active Shape ModelTheir Training and Application 吕玉生 2007.12.27
Overview • TRAINING • Shape training • Gray level training • APPLICATION • Image Search
TRAINING • Shape training • Aligning the training set • Aligning two shapes • Aligning all shapes • Capturing the statistics
The Weighting Matrix The weighting matrix is a diagonal matrix of weights. The weights are chosen to give more significance to the landmark points which tend to be more stable. A stable point would move about less with respect to other points in the shape.
Let Riklbe the distance between the landmark points k and l in the ith shape. Then let denote the variance of the distance between the landmark points k and l be denoted VRkl, then the weight for the kth landmark will be , where 0 <= k <= n - 1 where n is the number of landmark points. The weighting matrix will then be the following diagonal matrix.
Aligning two shapes Given two shapes, x1 and x2 , represented by landmarks, i.e. we would like to find · the rotation angle: , · the scaling factor: s , · and the value of the translation in both dimensions: (tx,ty) that will align x2 to x1 , by mapping x2 to where
Substituting ,we have The weighted distance between the two points in the 2n-D space representing the two shapes x1 and x2 , is given by: For the rotation, scaling and translation of a single coordinate (x2k, y2k) we have
Now, we can rewrite as Denoting and we have:
which can be written as , where Rewriting as
we can now solve for z that minimizes , which is the least squares solution to WAz = Wx1 Once is known, s and q can be found, since
Aligning all shapes Align each shape to one of the shapes (ex. first shape) Calculate the mean of the aligned shapes Normalize the pose of the resulting mean shape. No Realign eachshape with the normalized mean. Convergence? Yes Done! Shapes aligned.
(eg. ) Capturing the statistics We can obtain where and the constraints on b:
TRAINING • Gray level training • Modeling the gray level Appearance We examine the gray level information around each landmark in all the training set of images. We then try to put such information in a compact form and use it while performing image search. This gray level information is used to cause the landmark points of the estimate to move to better locations when performing image search. We may concentrate on the gray levels along a line passing through the landmark in question and perpendicular to the boundary formed by the landmark and its neighbors.
Modeling the gray level Appearance For every landmark point j in the image i of the training set, we extract a gray level profile gij, of length nppixels, centered at the landmark point. The gray level profile of the landmark j in the image i is a vector of npvalues, and the derivative profile of length np- 1 becomes
The normalized derivative profile is given by Now, we calculate the mean of the normalized derivative profiles of each landmark throughout the training set, and we get for landmark j The covariance matrix of the normalized derivative is given by
APPLICATION • Image Search • The initial estimate • The suggested movements • Computing the shape and pose parameters • Updating the shape and pose parameters
xlcan also be expressed as , with dxl= Pbl , then we have The initial estimate We can express the initial estimate xi of the shape as a scaled, rotated and translated version of a shape xl : as our initial estimate.
The suggested movements Now examining the region surrounding each landmark point of xiwe find that xishould move to xi+ dxi. The search profile along the landmark j is denoted sjwhose length is ns(surely ns> np) The derivative search profile of landmark i will be of length ns- 1 as follows
The normalized derivative search profile landmark i will be Denoting the sub-interval of ysjcentered at the dth pixel of ysj , by h(d ) we find the value of d that makes the sub-profile h(d) most similar to yj. This can be done by defining the following square error function and minimizing it with respect to d : In this way the location of the point to which the landmark i should move is determined.
We first find the additional scaling 1+ ds , rotation d and translation (dtx, dty) , required to move xias close as possible to xi+ dxi: Knowing 1+ ds , d and dt , we need to solve the following equation for dx : Computing the shape and pose parameters
So, instead of xl moving to xl+ dx it will move Using we get: since We seek the vector that is most similar to dx (in 2n-D space) but lies in the t-D space:
Expressing as and multiplying by PTfrom the left, we get
Updating the shape and pose parameters With this information, we are ready to update the shape and pose parameters of our initial estimate. We obtain a new estimate xi(1) where We then start with xi(1) the same we started with xiand produce xi(2) , and so on, until no significance change in the shape is noticeable.