Download

1 / 56
560 likes | 670 Views
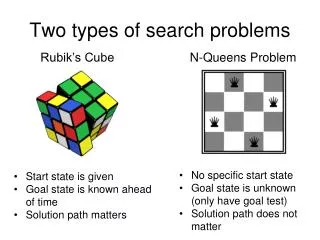
Two Solutions in Search of Killer Apps. Dimacs workshop on Algorithms in Human Population Genomics Dan Gusfield UC Davis. Two Algorithmic Topics. We have new algorithmic tools for a) computing the Minimum Mosaic of a set of recombinants, and for b) multi-state Perfect

E N D
Two Solutions in Search of Killer Apps. Dimacs workshop on Algorithms in Human Population Genomics Dan Gusfield UC Davis
Two Algorithmic Topics We have new algorithmic tools for a) computing the Minimum Mosaic of a set of recombinants, and for b) multi-state Perfect Phylogeny with missing data, that should be of use in Population Genomics and Phylogenetics. These tools were developed `on spec’: We have `hand-waiving’ arguments for their utility, but no actual (biological data-set) applications. Suggestions wanted.
Topic I: Improved Algorithms for Inferring the Minimum Mosaic of a Set of Recombinants Yufeng Wu and Dan Gusfield UC Davis From CPM 2007
Suffix Prefix 11000 0000001111 Breakpoint Recombination • Recombination: one of the principle genetic forces shaping sequence variations within species. • Two equal length sequences generate a new equal length sequence. 110001111111001 000110000001111
Sampled sequences in current population 000000 111111 001111 111100 000000 001111 111100 011100 000000 111111 001111 Breakpoint Mosaic Founders and Mosaic • Current sequences are descendents of a small number of founders. • A current sequence is composed of blocks from the founders, due to recombination. • No mutations since formation of founders. 000000 001111 111100 011100 000000 111111 Founders
Four breakpoints: minimum for all possible three founders 1101101 1010001 0111111 0110100 1100011 1101111 1010001 0110100 Three Founders The Minimum Mosaic Problem • Given a set of aligned binary sequences in the current population and assume the number of founders is known to be Kf, find set of founders and the mosaic with the minimum number of breakpoints. Assume Kf =3 1101101 1010001 0111111 0110100 1100011
Status of the Minimum Mosaic Problem • First studied by E. Ukkonen (WABI 2002). Later WABI 2007. • Dynamic programming method. Not practical when the number of rows is more than 20 and Kf >2. • No polynomial-time algorithm was known even when Kf is small. No NP-completeness result is known. • Our results: • A simple polynomial-time algorithm for Kf = 2 case. • Exact and practical method for data of medium range for Kf 3.
Founder Mapping 1101101 Breakpoint! Founder 1 Founder 2 Three or More Founders: Assuming Known Founders Input Sequences Three Founders With known founders, can minimize breakpoints for each sequence, and thus also minimize the total number of breakpoints. For each input sequence, starting from the left, insert a breakpoint at the end of longest segments matching one founder. Founder mapping: at each position c in any input sequence s, which founder s[c] takes its value from. 1101101 1010001 0111111 0110100 1100011 1101111 1010001 0110100 1101101
Enumerating Founders for Founder-Unknown Case In reality, founders are not known. A straightforward way is to simply enumerate all possible sets of founders, and then run the previous method to find the minimum mosaic. 1 0 0 0 1 0 0 1 1 1 0 1 0 0 1 1 1 0 At each column, there are 2kf–2 founder settings. Let m be the number of columns, fully enumerate all possible sets of founders takes (2m*kf) time. Infeasible when m or Kf is large. Need more ideas to develop a practical method. First, we do the enumeration in the form of search paths in a search tree.
c2 c3 Founder settings up to column 3 On-line computation: Compute partial solution up to the current column for speedup. Num of tot. breakpoints up to current column 0 0 1 0 0 1 2 0 0 1 0 1 0 0 1 0 5 0 0 1 0 1 0 1 The founder-known method can be run with partially-known founders! 0 0 1 1 0 0 0 0 0 1 0 1 1 1 0 0 1 1 0 1 0 0 0 1 1 1 0 2 Search Paths and Search Tree Assume three founders Founder setting at column one 0 0 1 0 It works but exponential blowup of the search paths! Obvious idea to reduce search space: branch and bound (compute a lower bound and …). But we found a different idea is more useful. 0 1 1 0 c1
<= 5 bkpts 40 >= 0 bkpts An optimal search path following P2 Dropping Search Paths that are Beaten by Another Search Path Founder Config. P1 P1 and P2 are two search paths up to column 2. Can we say P1 is better than P2? Not really, because maybe P2 can lead to fewer breakpoints later on. But, suppose the number of input sequences is 5. We can then say P1 beats P2 (and so drop P2). Why? <=39 0 1 1 0 0 1 0 P2 1 0 1 0 1 1 6 Assume three founders
A more powerful beating rule We use a more powerful, but more complex, rule to identify paths that will be beaten, and we use rules that avoid generating beaten paths and redundant, symmetric paths. These methods reduce the enumeration enormously, allowing practical computation of the optimal.
How Practical Is Our Method? Source of data and image: UNC Chapel Hill Five founders 20 rows, 36 columns UNC’s heuristic solution: 54 breakpoints Enumerating 2180 founder states is impossible! Our method takes 5 minutes to find the optimal solutions: 53 breakpoints. It is also practical for 50x50 matrix with four founders.
Another example The data from Ukkonen’s 2007 WABI paper (4 founders, 20 sequences, 40 sites was solved in 5 secs and used one fewer crossover than used in that paper.
Applications? • Founders on an island • Founders in microbial communities • ???
Topic II: Multi-State Perfect Phylogenywith Missing and Removable Data To appear in Recomb 2009, May 09 Dan Gusfield
The Perfect Phylogeny Modelfor binary sequences Only one mutation per site allowed (infinite sites) sites 12345 Ancestral sequence 00000 1 4 Site mutations on edges 3 00010 The tree derives the set M: 10100 10000 01011 01010 00010 2 10100 5 10000 01010 01011 Extant sequences at the leaves
What is a Perfect Phylogeny for k-state characters? • Input consists of n sequences M with m sites (characters) each, where each site can take one of k > 2 states. • In a Perfect Phylogeny T for M, each node of T is labeled with an m-length sequence where each site has a value from 1 to k. • T has n leaves, one for each sequence in M, labeled by that sequence. • Arbitrarily root T at some node, and direct all the edges away from the root. Then, for any character C with b states, there are at most b-1 edges where character C mutates, and for any state s of C, there is at most one edge where character C mutates to state s. This more reflects the infinite alleles model rather than infinite sites.
What is a Perfect Phylogeny for k-state characters? • Input consists of n sequences M with m sites (characters) each, where each site can take one of k > 2 states. • In a Perfect Phylogeny T for M, each node of T is labeled with an m-length sequence where each site has a value from 1 to k. • T has n leaves, one for each sequence in M, labeled by that sequence. • Arbitrarily root T at some node, and direct all the edges away from the root. Then, for any character-state pair (C,s), C can mutate into state s on at most one edge, but there are no edges where C mutates into its root state. This more reflects the infinite alleles model rather than infinite sites.
Example: A perfect phylogeny for input M (2,3,2) A B C (3,2,1) Root 1 (3,2,3) 2 (3,2,3) 3 4 (1,2,3) 5 M n = 5 m = 3 k = 3 (1,2,3) (1,1,3)
A more standard definition • For each character-state pair (C,s), the nodes of T that are labeled with state s for character C, form a connected subtree of T. • It follows that the subtrees for any C are node-disjoint. This condition is called the convexity requirement.
Example (2,3,2) A B C (3,2,1) 1 (3,2,3) 2 (3,2,3) 3 The tree for State 2 of Character B 4 (1,2,3) 5 M n = 5 number of taxa m = 3 number of sites k = 3 number of states (1,2,3) (1,1,3)
Perfect Phylogeny Problems Existence Problem: Given M, is there a Perfect Phylogeny for M? Missing Data Problem: For a given k, if there are cells in M without values, can values less than or equal to k be imputed so that the resulting matrix M’ has a perfect phylogeny? Handling missing data extends the utility of the perfect- phylogeny model.
Status of the Existence Problem Poly-time algorithm for 3 states, Dress-Steel 1993 Poly-time algorithm for 3 or 4 states, Kannan-Warnow 1994 Poly-time algorithm for any fixed number of states - polynomial in n and m, but exponential in k, Agarwalla and Fernandez-Baca 1994 Speed up of the method by Kannan-Warnow 1997 When k is not fixed, the existence problem is NP-hard
Status of missing data problem NP-complete even for k = 2; effective integer programming approaches for k = 2. Polynomial-time methods for a `directed’ variant of k = 2. No literature on the missing data problem for k > 2. New work here: specialized ILP methods for k = 3,4,5 and a general ILP solution for any fixed k. In this talk I will only discuss the general solution.
New approach to existence and missing data Based on an old theorem and newer techniques. Old theorem: Buneman’s theorem relating Perfect- Phylogeny to chordal graphs. Newer techniques and theorems: Minimal triangulations of a non-chordal graph to make it chordal.
Chordal Graphs A graph G is called Chordal if every cycle of length four or more contains a chord.
Another Classic (1970s) Characterization A graph G is chordal if and only if it is the intersection graph of a set S of subtrees of a tree T. Each node of G is a member of S. {b,c} {c,d,e,g} c {a,e,g} b g d a {a,e} {e,f,g} f e {b,c,d} G T
Relation to Perfect Phylogeny In a perfect phylogeny T for a table M, for any character C and any state s of character C, the sub-forest of T induced by the nodes labeled (C,s) form a single, connected subtree of T. So, there is a natural set of subtrees of T induced by M, and hints at the relationship of perfect-phylogeny to chordal Graphs. Buneman’s theorem makes this precise.
Buneman’s Approach to Perfect Phylogeny 1 23 Partition-Intersection Graph G(M) has one node for each character-state pair in M, and an edge between two nodes if and only if there is a row in M with both those character-state pairs. 1 23 1 1 1 2 2 2 3 3 3 G(M) Table M Each row of table M induces a clique in Partition-intersection graph G(M).
Note that if table M has m columns, then G(M) is a m-partite graph. Nodes in the same class of G(M) are said to have the same color. Two nodes with the Same color are called a mono-chromatic pair. An edge (u,v) not in G(M) is legal if u and v are in different classes of the partition, ie. are not a mono-chromatic pair.
Buneman’s Theorem Theorem (Buneman 1971?) There is a perfect phylogeny for M if and only if legal edges can be added to graph G(M) to make it chordal. If there is such a chordal graph, denote it G’(M). G’(M) is called a legal triangulation of G(M).
From Chordal Graph to Perfect Phylogeny Fact: Given a legal triangulation G’(M), a perfect phylogeny for M can be constructed in linear time. The algorithms are based on `perfect elimination orders’ And `clique trees’. Many citations.
Example 123 A: 0 0 2 B: 0 1 0 C: 1 1 1 D: 1 2 2 M 3,0 2,1 3,1 C B 1,1 1,0 A D 2,0 3,2 2,2 G’(M)
A legal triangulation 1 2 3 A: 0 0 2 B: 0 1 0 C: 1 1 1 D: 1 2 2 M 3,0 2,1 3,1 C B X Y 1,1 1,0 A D 2,0 3,2 2,2 G’(M)
Yields a Perfect Phylogeny 1 2 3 A: 0 0 2 B: 0 1 0 C: 1 1 1 D: 1 2 2 M 111 010 C B X 012 Y 112 A D 002 122 One node in T for each maximal clique in G’(M)
What about Missing Data? If M is missing data, build the partition intersection graph G(M) using the known data in M. Buneman’s theorem still holds: There is a perfect phylogeny for some imputation of missing data in M, if and only if there is a legal triangulation of G(M). The legal triangulation gives a perfect phylogeny T for M with some imputed data, and then the imputed M’ can be obtained from T.
Example 1 2 3 A: 0 0 2 B: 0 ? 0 C: 1 1 1 D: 1 2 2 M 3,0 2,1 3,1 C B 1,1 1,0 A D 2,0 3,2 2,2 G(M)
The Key Problem So the key problem in this approach to both the Existence and the Missing Data problems is how to find a legal triangulation, if there is one. Some triangulation problems are NP-hard (Tree-width, Minimum fill-in). But, there is a robust and still expanding literature on efficient algorithms to find a minimal triangulationof a non-chordal graph.
Minimal triangulation A triangulation of a non-chordal graph G is minimal if no subset of added edges is a triangulation of G. Clearly, if there is a legal triangulation G’(M) of G(M), Then there is one which is a minimal triangulation. So we can take advantage of the minimal triangulation technology. The minimal vertex separators are the key objects.
Minimal vertex separators A set of vertices S whose removal separates vertices u and v is called a u,v separator. S is a minimal u,v separator if no subset of S is a u,v separator. S is a minimal-separator if it is a minimal u,v separator for some u,v. Minimal separator S crosses minimal separator S’, if S separates some pair of nodes in S’. Crossing is a symmetric relation for minimal separators.
Example {(2,1), (3,2)} and {(1,0), (1,1)} are crossing minimal separators. 3,0 2,1 3,1 C B 1,1 1,0 {(2,1), (1,1)} and {(1,0), (3,2)} are non-crossing minimal separators. A D 2,0 3,2 2,2 G(M)
The structure of a minimal triangulation in G Completing a minimal separator K means adding all the missing edges to make K a clique. Capstone Theorem (P,S 1997): Every minimal triangulation of G is obtained by completing each minimal separator in a maximal set of pairwise non-crossing minimal separators of G. Conversely, completing every minimal separator in a maximal set of pairwise non-crossing minimal separators yields a triangulation of G.
A legal triangulation 1 2 3 A: 0 0 2 B: 0 1 0 C: 1 1 1 D: 1 2 2 M 3,0 2,1 3,1 C There are 6 minimal separators. B 1,1 X 1,0 Y 5 are pairwise non-crossing A D 2,0 3,2 2,2 G’(M)
Back to Perfect Phylogeny A minimal separator S in the partition intersection graph G(M) Is called legal if it does not contain two nodes of the same color and illegal if it does. P,S Theorem can be used to prove the Main New Results Theorem 1: There is a perfect phylogeny for M, even if M is missing data, If and only if there is a set of pairwise non-crossing legal minimal separators in G(M) that separate every mono-chromatic pair of nodes in G(M).
A legal triangulation 1 2 3 A: 0 0 2 B: 0 1 0 C: 1 1 1 D: 1 2 2 M 3,0 2,1 3,1 C B X Y 1,1 1,0 A D 2,0 3,2 2,2 G’(M)
Corollaries Cor 1: If there is a mono-chromatic pair of nodes in G(M) that is not separated by any legal minimal separator, then M has no perfect phylogeny. Cor 2: If G(M) has no illegal minimal separators, then M has a perfect phylogeny. Cor 3: If every mono-chromatic pair of nodes is separated by some legal minimal separator, and no legal minimal separators cross, the M has a perfect phylogeny.
How to solve the existence and missing data problems Given M, find all minimal separators in G(M); determine which are legal and which are illegal; for each legal minimal separator, determine which mono-chromatic pairs of nodes it crosses. Determine if any of the Corollaries hold. If not, set up and solve an integer linear program to find a set Q of pairwise non-crossing legal minimal separators that separate every mono-chromatic pair of nodes in G(M).
Conceptually nice, but Does it work in practice?
It works surprisingly (shockingly) well Simulations based on ms, with datasets of sizes that are charactoristic of many current applications in phylogenetics and population genetics - but not genomic scale or tree-of-life scale.