Download

1 / 24
240 likes | 374 Views
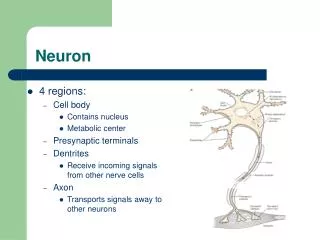
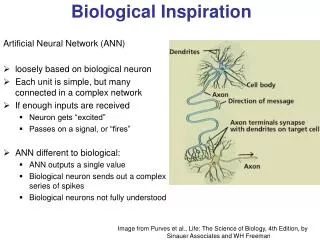
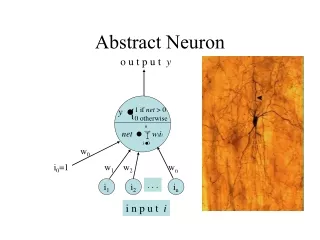
Neural Networks. Learning Processes. Biological and Artificial Neuron. Weights, need to be determined. Biological neuron. Bias, need to be determined. Artificial neuron. Neural Networks. Learning Processes. Application of Neural Networks. Function approximation and prediction

E N D
Neural Networks Learning Processes Biological and Artificial Neuron Weights, need to be determined Biological neuron Bias, need to be determined Artificial neuron
Neural Networks Learning Processes Application of Neural Networks • Function approximation and prediction • Pattern recognition • Signal processing • Modeling and control • Machine learning
Neural Networks Learning Processes Building a Neural Network • Select Structure: design the way that the neurons are interconnected. • Select weights: decide the strengths with which the neurons are interconnected. • Weights are selected to get a “good match” of network output to the output of a training set. • Training set is a set of inputs and desired outputs. • The weight selection is conducted by the use of a learning algorithm.
Neural Networks Learning Processes Learning Process Stage 1: Network Training Artificial neural network Learning Process Training Data Knowledge Input and output sets, adequate coverage In the form of a set of optimized synaptic weights and biases Stage 2: Network Validation Artificial neural network Output Prediction ImplementationPhase Unseen Data From the same range as the training data
Neural Networks Learning Processes Learning Process ANN • Learning is a process by which the free parameters of a neural network are adapted through a process of stimulation by the environment in which the network is embedded. • In most cases, due to complex optimization plane, the optimized weights and biases are obtained as a result of a number of learning iterations. [w,b] x y Initialize: Iteration (0) [w,b]0 x y(0) Iteration (1) [w,b]1 x y(1) … Iteration (n) [w,b]n x y(n) ≈d d: desired output
Neural Networks Learning Processes Learning Rules • Error Correction Learning • Delta Rule or Widrow-Hoff Rule • Memory Based Learning • Nearest Neighbor Rule • Hebbian Learning • Synchronous activation increases the synaptic strength • Asynchronous activation decreases the synaptic strength • Competitive Learning • Boltzmann Learning
Neural Networks Learning Processes Error-Correction Learning Activation function wk1(n) x1 Desired output dk(n) wk2(n) + x2 Output yk(n) S f(.) S Inputs - Synaptic weights wkm(n) Error signal xm bk(n) ek(n) Bias 1 Learning Rule
Neural Networks Learning Processes Delta Rule (Widrow-Hoff Rule) Minimization of a cost function (or performance index)
Neural Networks Learning Processes Delta Rule (Widrow-Hoff Rule) wkj(0) = 0 n = 0 Least Means Squares Rule yk(n) = S [wkj(n) xj(n)] wkj(n+1) = wkj(n) + h [dk(n) – yk(n)] xj(n) h: learning rate, [0…1] n = n+1
Neural Networks Learning Processes Delay Desired Environment (Data) Teacher (Expert) Cost Function Environment (Data) ANN + - ANN S Actual Delayed Reinforcement Learning Error Learning Paradigm Unsupervised Supervised
Neural Networks Single Layer Perceptrons Single Layer Perceptrons • Single-layer perceptron network is a network with all the inputs connected directly to the output(s). • Output unit is independent of the others. • Analysis can be limited to single output perceptron.
Neural Networks Single Layer Perceptrons Derivation of a Learning Rule for Perceptrons • Key idea: Learning is performed by adjusting the weights in order to minimize the sum of squared errors on a training. • Weights are updated repeatedly (in each epoch/iteration). • Sum of squared errors is a classical error measure (e.g. commonly used in linear regression). E(w) • Learning can be viewed as an optimization search problem in weight space. w1 w2
Neural Networks Single Layer Perceptrons Derivation of a Learning Rule for Perceptrons • The learning rule performs a search within the solution's vector space towards a global minimum. • The error surface itself is a hyper-paraboloid but is seldom as smooth as is depicted below. • In most problems, the solution space is quite irregular with numerous pits and hills which may cause the network to settle down in a local minimum (not the best overall solution). • Epochs are repeated until stopping criterion is reached (error magnitude, number of iterations, change of weights, etc).
Neural Networks Single Layer Perceptrons x1 wk1 x2 wk2 . . . wkm xm Derivation of a Learning Rule for Perceptrons Adaline (Adaptive Linear Element) Widrow [1962] Goal:
Neural Networks Single Layer Perceptrons Least Mean Squares (LMS) • The following cost function (error function) should be minimized:
Neural Networks Single Layer Perceptrons Least Mean Squares (LMS) • Letting f(wk) = f (wk1, wk2,…, wkm) be a function overRm, then • Defining
Neural Networks Single Layer Perceptrons f f f w w w Gradient Operator To minimize f , we choose df: zero df: negative df : positive go downhill go uphill plain
Neural Networks Single Layer Perceptrons Adaline Learning Rule • With then • As already obtained before, Weight Modification Rule • Defining we can write
Neural Networks Single Layer Perceptrons Adaline Learning Modes • Batch Learning Mode • Incremental Learning Mode
Neural Networks Single Layer Perceptrons Adaline Learning Rule • -Learning Rule • LMS Algorithm • Widrow-Hoff Learning Rule
Neural Networks Single Layer Perceptrons Generalization and Early Stopping • By proper training, a neural network may produce reasonable output for inputs not seen during training Generalization • Generalization is particularly useful for the analysis of a “noisy” data (e.g. time–series) • “Overtraining” will not improve the ability of a neural network to produce good output. • On the contrary, it will try to take noise as the real data and lost its generality.
Neural Networks Single Layer Perceptrons Generalization and Early Stopping Overfitting vs Generalization
Neural Networks Single Layer Perceptrons Homework 1 • Given a function y = 4x2, you are required to find the value of x that will result y = 2 by using the Least Mean Squares method. • Use initial estimate x0 = 1 and learning rate η= 0.01. • Write down the results of the first 10 epochs/iterations. • Give conclusion about your result. • Note: Calculation can be done manually or using Matlab.