Download

1 / 11
110 likes | 223 Views
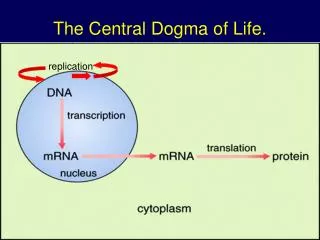
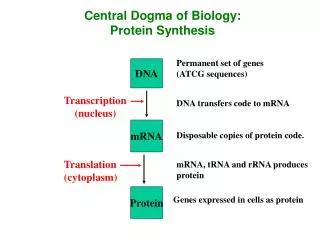
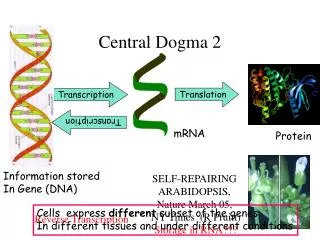
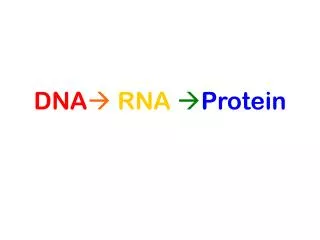
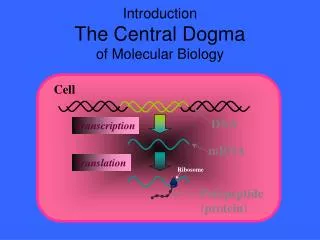
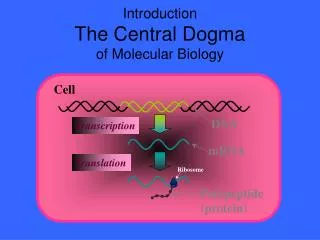
Central Dogma: DNA-RNA-Protein. Transcription of DNA to RNA to protein: This dogma forms the backbone of molecular biology and is represented by three major stages: Replication, transcription and translation. Draw a picture of these stages. How does DNA replication work?.

E N D
Central Dogma: DNA-RNA-Protein Transcription of DNA to RNA to protein: This dogma forms the backbone of molecular biology and is represented by three major stages: Replication, transcription and translation. Draw a picture of these stages.
How does DNA replication work? • DNA helicases unwind the DNA. The unwound DNA strands are stabilised by single strand-DNA binding protein. The new DNA is synthesised by DNA polymerase in the 5'-3’ direction. All DNA polymerases synthesise in 5'-3’ direction. However, the two single strands have different directions. They are antiparallel. The polymerase can synthesise the leading strand normally, but at the lagging strand the polymerase and helicase will move away from one other. The solution to this problem: • DNA polymerase synthesises a series of short DNA fragments (called Okazaki-Fragments), the polymerase “jumps” back again on the lagging strand. DNA ligase connects these fragments. • Draw a picture of this process.
How does RNA synthesis and processing work? Besides the coding information (exons), DNA contains a lot of non-coding information (introns). During RNA processing these non-coding parts are removed. Before the synthesis of a protein starts, the corresponding RNA molecule is formed by RNA transcription. One strand of the DNA double helix is used as a template by the RNA polymerase to synthesise a messenger RNA (mRNA). This mRNA migrates from the nucleus to the cytoplasm. During this step, mRNA goes through different types of maturation including one called splicing where the non-coding sequences are eliminated. The coding mRNA sequence can be described in units of three nucleotides called codons. In most mammalian cells, only 1% of the DNA sequence is copied into a functional RNA (mRNA). Only one part of the DNA is transcribed to produce nuclear RNA, and only a minor portion of the nuclear RNA survives the RNA processing steps. One of the most important stages in RNA processing is RNA splicing. In many genes, the DNA sequence coding for proteins, or "exons", may be interrupted by stretches of non-coding DNA, called "introns". In the cell nucleus, the DNA that includes all the exons and introns of the gene is first transcribed into a complementary RNA copy called "nuclear RNA," or nRNA. In a second step, introns are removed from nRNA by a process called RNA splicing. The edited sequence is called "messenger RNA" or mRNA. The mRNA leaves the nucleus and travels to the cytoplasm, where it encounters cellular bodies called ribosomes. The mRNA, which carries the gene's instructions, controls the production of proteins by the ribosomes. In eukaryotic cells, the mRNA is processed (essentially by splicing) and migrates from the nucleus to the cytoplasm. Draw a picture of this process.
How does protein synthesis work? Messenger RNA carries coded information to the ribosomes. The ribosomes "read" this information and use it for protein synthesis. This process is called translation. The ribosome binds to the mRNA at the start codon (AUG) that is recognised only by an initiator tRNA. The ribosome proceeds to the elongation phase of protein synthesis. During this stage, complexes, composed of an amino acid linked to tRNA, sequentially bind to the appropriate codon in mRNA by forming complementary base pairs with the tRNA anticodon. The ribosome moves from codon to codon along the mRNA. Amino acids are added one by one and translated into the polypeptidic sequences encoded by DNA and represented by mRNA. Finally, a release factor binds to the stop codon, terminating translation and releasing the complete polypeptide from the ribosome. One specific amino acid can correspond to more than one codon. The genetic code is thus said to be degenerate. (optional: find a table on the internet with the genetic code and try to translate a genetic sequence into an amino acid sequence or translate an amino acid sequence in a DNA chain) Draw a picture of this process.
Structure of ribosomes Ribosomes consist of two large subunits of different sizes and structures, which are conglomerates of about 80 proteins and ribosomal RNA (rRNA). Usually, naming of the components is by their sedimentation coefficients instead of their mass. The whole ribosome has a sedimentation coefficient of 80 Svedberg (80 S), the subunits 40 S and 60 S, respectively. S-values are not additive. The smaller 40 S-subunits consist of a molecule of 18S-rRNA and 32 protein molecules. The larger 60 S-subunit contains three kinds of rRNA, with sedimentation coefficients of 5 S, 5.8 S and 28 S, as well as 46 proteins. In the presence of mRNA, the subunits combine to form the complete ribosome, whose molecular mass is about 650 times larger than a haemoglobin molecule. Prokaryotic ribosomes are similarly constructed, but are slightly smaller than those of eukaryotes; 70 S for the complete ribosome with values of 30 S and 50 S for the respective subunits.
Lac operon Figure 1:E. coli encodes a -galactosidase that hydrolyses lactose into glucose and galactose. Normally, E. coli prefer glucose as carbon source. Under these conditions lactose metabolising enzymes are not required and the coding genes are only weakly expressed (Figure 2, A). The lacZ gene (the coding gene for -galactosidase) is part of the lac operon. With lactose as the only carbon source, the synthesis of the enzymes involved in metabolism of this nutrient increases more than 1000 fold (Fig 2, B). -galactosidase also hydrolyses chromogenic substrates as X-gal (5-bromo-4-chloro-3-indolyl--D-galactoside) to a non toxic, insoluble, dense blue-coloured product ( Fig.3). Figure 2:(A): The lac operon of E. coli with glucose as a carbon source. The repressor binds to the promotor of the lac operon and expression of the upstream coding genes is inhibited. (B): Lactose in the culture medium forms an inducer that binds to and inactivates the repressor. As the result, the coding genes located upstream, ie. those for lactose metabolism, are expressed and lactose is metabolised. Figure 3:-galactosidase also converts the invisible, artificial-substrate X-gal into a deep blue-coloured oxidation product within cells.
What are the essential stepsto isolate DNA from an organism? Cells are separated from their environment by a membrane. Bacteria have an additional a cell wall of murein, plant cells one of cellulose. To extract the DNA, the first step is to dissolve these barriers. Cell walls are usually broken with enzymes that specifically attack the cell wall. The membrane can be dissolved very effectively with detergents. The next step is to separate the DNA from the remaining cell components. Proteins can be denatured and precipitated either by phenol extraction or by the effect of chaotrophic salts. Either centrifugation or filtration separates the insoluble components from the dissolved DNA, which can then be precipitated by addition of ethanol. The precipitated DNA can be washed with ethanol and then dissolved in a suitable buffer solution. Another way to purify the DNA is to bind it to an ion-exchange matrix and remove all other components by washing. Then the pure DNA is eluted with a suitable buffer solution from the matrix.
Classical Plasmid DNA preparation The classical DNA preparation method was introduced by Birnboim and Doly 1979. This method utilises an alkaline lysis in combination with the detergent SDS. The strongly anionic detergent opens the cell wall of bacteria at high pH, denatures chromosomal DNA and proteins, and releases plasmid DNA into the supernatant liquid. Due to the highly alkaline conditions, the DNA base pairs are denatured, but the circular plasmid DNA is intertwined so that the two strands are not separated. This way the two strands of plasmid DNA will realign, if the alkaline stress is not too high. After the lysis of the bacterial proteins, the broken cell walls and denatured chromosomal DNA are precipitated by SDS in the presence of potassium ions (Ish-Horowicz and Burke, 1981). After centrifugation, the plasmid DNA can be isolated from the supernatent liquid. For purer DNA, an additional phenol/chloroform purification step may be performed to remove residual protein contaminants. After adding phenol/chloroform, mixing, and centrifugation, the upper aqueous phase contains the DNA, whereas the interface contains denatured proteins. Remaining phenol can be removed by chloroform extraction. After addition of two volumes of ethanol and gentle shaking, the plasmid DNA is precipitated by centrifugation. The DNA pellet should be washed with 70% ethanol and dried for 10-15 minutes at room temperature to evaporate the remaining ethanol. Finally, the DNA may be dissolved in a suitable buffer solution.
Commercial DNA isolating-kits In the laboratory, DNA isolation is usually performed with commercial isolation kits. This is a summary of some DNA kits from Quiagen:
Classical chromosomal DNA preparation To obtain chromosomal DNA from organisms the following procedure is used. The method was originally presented by Darly Stafford and colleagues in 1976. First pellet and wash the cells by centrifugation in TE-buffer. The cells are lysed by SDS and, in the same step, RNA is digested by RNAse (at 37°C). Proteinase K then digests remaining protein at 50 °C, followed by phenol/chloroform extraction to remove all traces of both proteins and lipids. The aqueous phase is separated by centrifugation and the extraction is repeated several times. Lastly, the DNA in the aqueous phase is precipitated by addition of ethanol and ammonium acetate. The DNA is pelleted by centrifugation, washed with 70% ethanol, dried to remove the ethanol and finally dissolved in TE buffer.
How can I quantify DNA? In order to work with isolated DNA, you have to determine its concentration. DNA absorbs light at a wavelength of 260 nm, as a result of the conjugated structure of the purine and pyrimidine DNA bases. If the absorbance of a DNA solution is measured at 260 nm, then 1 OD (optical density) unit corresponds to a dsDNA concentration of 50 µg/ml with a layer thickness of 1 cm. However, as proteins and RNA also absorb at this wavelength, they interfere with the result. The quotient (A260/A280) of pure DNA is between 1.8 and 1.9.