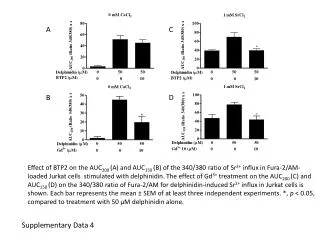
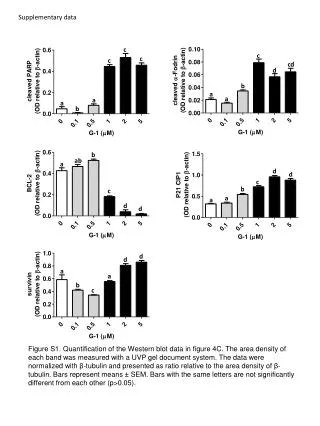
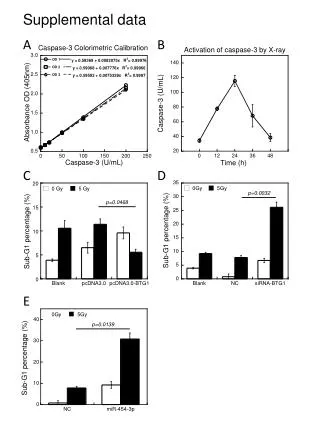
Download
1 / 6
60 likes | 161 Views
Big Data and HP(D)C. Gagan Agrawal Ohio State . Answering the Questions. Definition: I like the volume, velocity, variety (and verocity ) My collaborations and associated challenges Genomic data - scale, parallelization of analysis

E N D
Big Data and HP(D)C GaganAgrawal Ohio State
Answering the Questions • Definition: I like the volume, velocity, variety (and verocity) • My collaborations and associated challenges • Genomic data - scale, parallelization of analysis • Scientific simulation data – scale, data management solutions • Geosensing data - noise, data management and processing • Broader Observations from Application Collaborations • Everything is a challenge! • No training in parallelization • Or even writing efficient code!
Answers (Contd.) • Big Data and HP(D)C • Hype exists because there is a real (commercial) market • Database community has always addressed these problems • Big Data commercial efforts look at their work • HP(D)C community is not really in focus • e.g. our HPDC 2004 almost rediscovered as the NoDBSIGMOD 2012 paper! • What do we bring? • More experience with scientific applications • Real need, but little incentive for commercial or DB efforts • More insights into performance, parallelization, general programming models, and fault-tolerance than database community
Other Thoughts • Onus on HPC Community • Database, Cloud, and Viz communities active for a while now • Abstractions like MapReduce are neat! • So are Parallel and Streaming Visualization Solutions • Many existing solutions very low on performance • Do people realize how slow Hadoop really is? • And, yet, one of the most successful open source software? • We need to make our presence felt • Programming model design and implementation community hasn’t even looked at `big-data’ applications • We must engage application scientists • Who are often struck in `I don’t want to deal with the mess’
Open Questions • How do we develop parallel data analysis solutions? • Hadoop? • MPI + file I/O calls? • SciDB – array analytics? • Parallel R? • Desiderata • No reloading of data (rules out SciDBand Hadoop) • Performance while implementing new algorithms (rules out parallel R) • Transparency with respect to data layouts and parallel architectures
Data Management/Reduction Solutions • Must provide Server-side data sub-setting, aggregation and sampling • Without reloading data into a `system’ • Our Approach: Light-weight data management solutions • Automatic Data Virtualization • Support virtual (e.g. relational) view over NetCDF, HDF5 etc. • Support sub-setting and aggregation using a high-level language • A new sampling approach based on bit-vector • Create lower-resolutions representative datasets • Measure loss of information with respect to key statistical measures