Download
1 / 40
400 likes | 445 Views
Learn about CPU scheduling algorithms, states of processes, and performance evaluation criteria. Explore scheduling applications and optimization, including FIFO, SJF, and Round Robin. Understand preemptive and non-preemptive scheduling and prioritize task completion.

E N D
CPU Scheduling CS170 Fall 2015. T. Yang
What to Learn? • Algorithms of CPU scheduling, which maximizes CPU utilization obtained with multiprogramming • Select from ready processes and allocates the CPU to one of them • Performance evaluation criteria
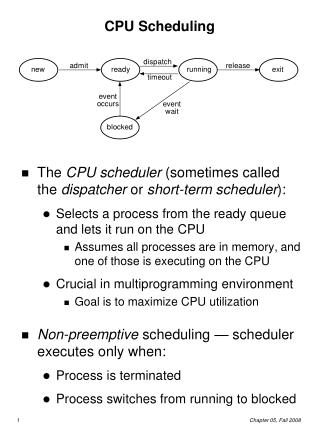
CPU Scheduling • Life-cycle (states) of a process or thread • Active processes/threads transit from Ready queue to Running to various waiting queues. • Question: How is the OS to select from each queue • Obvious queue to worry about is ready queue • Others can be scheduled as well, however • Scheduling: deciding which processes/threads are given access to resources blocked
Scheduling Applications • Job scheduling, resource scheduling, request scheduling. • For example, web server scheduling to handle high traffic
I/O and CPU Burst Cycle of a Process Process execution consists of a cycle of CPU execution and I/O wait Time
Histogram of CPU-burst Times Short CPU bursts are often dominating
Scheduling happens among CPU/IO bursts P2 P0 P1 Time
Process State Change vs CPU Scheduling • CPU scheduling decisions may take place when a process: 1. Switches from running to waiting (blocked) state 2. Switches from running to ready state 3. Switches from waiting/blocked to ready • Terminates • Preemptive Scheduling • Take the processor away from one process (job) and give it to another • State change from running to ready • Non-preemptive scheduling • A process runs continuously until it is blocked or terminates
Scheduling Terminology • Task/Job • Process, thread. User request: e.g., mouse click, web request, shell command, … • CPU utilization – keep the CPU as busy as possible • Throughput – # of processes that complete their execution per time unit • Waiting time – amount of time a process has been waiting in the ready queue • Turnaround time – amount of time to execute a particular process • Completion time – arrival time • = Waiting time + execution time • Response time – amount of time it takes from when a request was submitted until the first response is produced, not output (for time-sharing environment)
Scheduling Algorithm Optimization Criteria • Max CPU utilization • Max throughput • Min turnaround time • Min waiting time • Min response time
P1 P2 P3 0 24 27 30 First-In-First-Out (FIFO): also called FCFS First-Come, First-Served Scheduling ProcessBurst Time P1 24 P2 3 P3 3 • Suppose that the processes arrive in the order: P1 , P2 , P3 The Gantt Chart for the schedule is: • Waiting time for P1 = 0; P2 = 24; P3 = 27 • Average waiting time: (0 + 24 + 27)/3 = 17 • Turnaround time P1 = 24; P2 = 27; P3 = 30. • Average turnaround time= (24+27+30)/3=27
Shortest-Job-First (SJF) Scheduling • Always do the task that has the shortest remaining amount of work to do • Often called Shortest Remaining Time First (SRTF) • SJF is optimal – gives minimum average waiting time for a given set of processes • The difficulty is knowing the length of the next CPU request. • What is its weakness? • Starvation – low priority processes may never execute
P3 P2 P4 P1 3 9 16 24 0 Example of SJF Process Arrival TimeBurst Time P10.0 6 P2 2.0 8 P34.0 7 P45.0 3 • SJF scheduling chart • Average waiting time = (3 + 16 + 9 + 0) / 4 = 7
FIFO vs. SJF • Suppose we have five tasks arrive one right after each other, but the first one is much longer than the others • Which completes first in FIFO? Next? • Which completes first in SJF? Next?
Predicting Length of Next CPU Burst • Can be done by using the length of previous CPU bursts, using exponential averaging • New prediction is weighted average of previous prediction and actual time.
Prediction of the Length of the Next CPU Burst Guess Actual
Priority Scheduling • A priority number (integer) is associated with each process • The CPU is allocated to the process with the highest priority (smallest integer highest priority) • SJF is a priority scheduling where priority is the predicted next CPU burst time • Problem Starvation – low priority processes may never execute Solution • Aging – as time progresses, decrease the priority of the long-running process • Round robin
Round Robin (RR) • Each process gets a small unit of CPU time (time quantum), usually 10-100 milliseconds. • After this time has elapsed, the process is preempted and added to the end of the ready queue. • Performance • large quantum FIFO • small quantum context switch overhead is too high • No starvation.
P1 P2 P3 P1 P1 P1 P1 P1 0 10 14 18 22 26 30 4 7 Example of RR with Time Quantum = 4 ProcessBurst Time P1 24 P2 3 P3 3 • The Gantt chart is: • Typically, higher average turnaround than SJF, but better response
CPU Switch From Process to Process • This is also called a “context switch” • Code executed in kernel above is overhead • Overhead sets minimum practical switching time • Less overhead with SMT/Hyperthreading, but… contention for resources instead Anthony D. Joseph UCB CS162
The Numbers Context switch in Linux: 3-4 secs (Current Intel i7 & E5). Some surprises: • Thread switching only slightly faster than process switching (100 ns). • But switching across cores about 2x more expensive than within-core switching. • Context switch time increases sharply with the size of the working set*, and can increase 100x or more. * The working set is the subset of memory used by the process in a time window. Moral: Context switching depends mostly on cache limits and the process or thread’s hunger for memory. Anthony D. Joseph UCB CS162
Round Robin vs. FIFO • Assuming zero-cost context switch, is Round Robin always better than FIFO?
Round Robin vs. FIFO Everybody finishes very late. Longer turnaround
Round Robin vs. Fairness • Is Round Robin always fair?
Multi-level Feedback Queue (MFQ) • Goals: • Responsiveness, especially for interactive/high priority jobs • Less overhead • Fairness (among equal priority tasks). No startvation • Not perfect at any of them! • Used in Linux (Windows, and probably MacOS)
Multilevel Feedback Queue • Maintain multiple job queues. Each queue receives a fixed percentage of system resource. • A process can move between the various queues, representing priority aging so that high priority jobs will gradually lose their priority. FCFS = FIFO
Multilevel Queue Scheduling: Example • Ready queue is partitioned into separate queues: • foreground (interactive) • background (batch) • Each queue has its own scheduling algorithm: • foreground – RR • background – FIFO (FCFS) • Time slice – each queue gets a certain amount of CPU time which it can schedule amongst its processes; • i.e., 80% to foreground in RR • 20% to background in FIFO
Multilevel Feedback Queue: Example • Example with three queues: • Q0 – RR with time quantum 8 milliseconds • Q1 – RR time quantum 16 milliseconds • Q2 –FIFO(FCFS) • Scheduling • A new job enters queue Q0which is servedFCFS. When it gains CPU, job receives 8 milliseconds. If it does not finish in 8 milliseconds, job is moved to queue Q1. • At Q1 job is again served FCFS and receives 16 additional milliseconds. If it still does not complete, it is preempted and moved to queue Q2.
Windows Scheduling • Classes and priorities • Real time priority class: • Static priorities (priorities donot change) • Priority values: from 16 to 32 • Variable class: • variable priorities (e.g. 1-16) • If a process has used up its quantum, lower its priority • If a process waits for an I/O event, raise its priority • Priority-driven scheduler • For real-time class, do round robin within each priority • For variable class, do multiple queue
Linux Scheduling • Time-sharing scheduling • Each process has a priority and # of credits • I/O event will raise the priority -- fast response time when ready. • Process with the most credits will run next • A timer interrupt causes a process to lose a credit • Long running jobs lose credits • Real-time scheduling • Soft real-time • Kernel cannot be preempted by user code
Thread Scheduling • Scheduling user-level threads within a process • Known as process-contention scope (PCS) • Kernel thread scheduled onto available CPU is system-contention scope (SCS) – competition among all threads in system
One Many # of addr spaces: # threads per AS: One Many Classification • Real operating systems have either • One or many address spaces • One or many threads per address space MS/DOS, early Macintosh Traditional UNIX Embedded systems (Geoworks, VxWorks, JavaOS,etc) JavaOS, Pilot(PC) Mach, OS/2, Linux Win NT to 8, Solaris, HP-UX, OS X Anthony D. Joseph UCB CS162
Pthread Scheduling • API allows specifying either PCS or SCS during thread creation • PTHREAD_SCOPE_PROCESS schedules threads using PCS scheduling • PTHREAD_SCOPE_SYSTEM schedules threads using SCS scheduling.
Pthread Scheduling API #include <pthread.h> #include <stdio.h> #define NUM THREADS 5 int main(int argc, char *argv[]) { int i; pthread t tid[NUM THREADS]; pthread attr t attr; /* get the default attributes */ pthread attr init(&attr); /* set the scheduling algorithm to PROCESS or SYSTEM */ pthread attr setscope(&attr, PTHREAD_SCOPE_SYSTEM); /* set the scheduling policy - FIFO, RT, or OTHER */ pthread attr setschedpolicy(&attr, SCHED OTHER); /* create the threads */ for (i = 0; i < NUM THREADS; i++) pthread create(&tid[i],&attr,runner,NULL);
Pthread Scheduling API /* now join on each thread */ for (i = 0; i < NUM THREADS; i++) pthread join(tid[i], NULL); } /* Each thread will begin control in this function */ void *runner(void *param) { printf("I am a thread\n"); pthread exit(0); }
Multiple-Processor Scheduling • CPU scheduling more complex when multiple CPUs are available • each processor is self-scheduling. Each has its own private queue of ready processes • Or all processes in common ready queue • Processor affinity – process has affinity for processor on which it is currently running • soft affinity • hard affinity
Summary • Scheduling: selecting a process from the ready queue and allocating the CPU to it • FIFO (FCFS) Scheduling: • Pros: Simple • Cons: Short jobs get stuck behind long ones • Round-Robin Scheduling: • Pros: Better for short jobs (+) • Cons: weak when jobs are same length. No prioritization. Longer average turnaround. More context switch overhead.
Summary (cont’d) • Shortest Job First (SJF)/Shortest Remaining Time First (SRTF): • Pros: Optimal (average response time) • Cons: Hard to predict future, Unfair • Multi-Level Feedback Scheduling: • Fairness while having different priorities. Everybody makes progress. • Automatic promotion/demotion of process priority in order to approximate SJF/SRTF • Responsiveness, especially for interactive/high priority jobs • Less context switch overhead with different quantum. • Windows/Linux scheduling