Download
1 / 27
270 likes | 279 Views
This text explores various selection algorithms such as finding the minimum, maximum, median, and ith largest element in an array. It also provides an analysis of the expected running time for these algorithms.

E N D
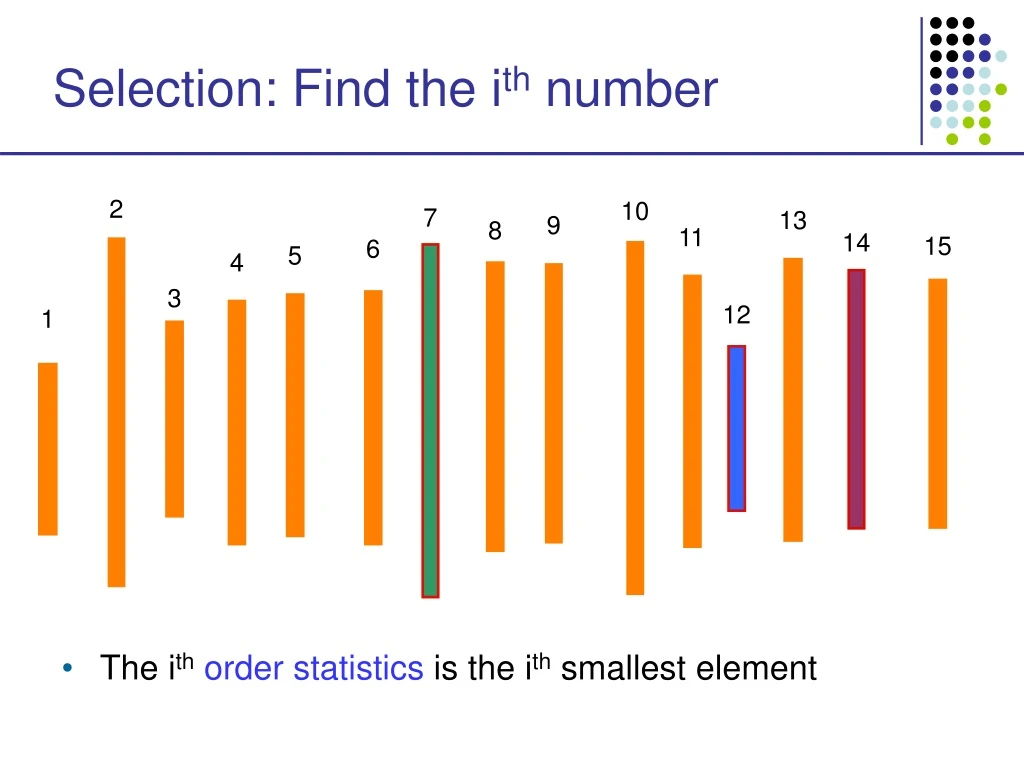
Selection: Find the ith number 2 10 • The ithorder statistics is the ith smallest element 7 13 9 8 11 14 15 6 5 4 3 12 1
Find the minimum • MINIMUM(A) • min = A[1] • for i = 2 to A.length() • if min > A[i] • then min = A[i] • return min • How many comparisons does this algorithm perform? • Can we do better?
Find both min, max • 3 comparisons for every 2 elements in A < > < > min max
How can we find the median? • More generally, how can we find the ith largest element? • SELECTION: Find ith largest element of A • Naïve Algorithm: • Sort A • Return A[i] • Running Time: O(n log n) Can we do better?
Selection in Expected Time O(n) • RANDOMIZED-SELECT(A, p, r, i) • if p = r then return A[p] • q = RANDOMIZED-PARTITION(A, p, r) • k = q - p + 1 • if i = k then return A[q] • if i < k • then return RANDOMIZED-SELECT(A, p, q-1, i) • else return RANDOMIZED-SELECT(A, q+1, r, i-k) kth element p q r
What is the Worst-Case Time? • Example: • RANDOMIZED-SELECT(A, 1, n, 1) • Unluckily always partition around the maximum remaining element • Running Time: (n - 1) +(n - 2) + (n - 3) + … + 1 = (n2)
Expected Running Time • PARTITION returns the kth largest element with probability 1/n • Therefore A[p…q] has k elements with probability 1/n • Let Xk = I { A[p…q] has k elements } • E(Xk) = 1/n • Let T(n) be the running time, to estimate E(T(n)) T(n) ≤ k=1…n Xk T( max( k-1, n-k ) ) + O(n)
Expected Running Time T(n) ≤ k=1…n Xk T( max( k – 1, n – k ) + O(n) • Taking expected values E(T(n)) ≤ E( k=1…n Xk T( max( k – 1, n – k ) + O(n) ) = k=1…n E( Xk T( max( k – 1, n – k ) ) + O(n) • (Xk and T(max(k – 1, n – k)) are independent) = k=1…n E(Xk) E(T( max( k – 1, n – k )) + O(n) = k=1…n 1/n E(T( max( k – 1, n – k )) + O(n)
Expected Running Time E(T(n)) = 1/n k=1…n E(T( max( k – 1, n – k )) + O(n) • Can now simplify max(k-1, n-k): E(T(n)) = 2/n k=n/2…n E(T(k)) + O(n) • We will solve this by substitution: Guess E(T(n)) ≤ cn E(T(n)) ≤ 2/n k=n/2…n ck + an
Expected Running Time To show that E(T(n)) ≤ 2/n k=n/2…n ck + an ≤?? cn E(T(n)) ≤ 2c/n (k=1…n k - k=1…(n/2-1) k) + an = 2c/n ((n-1)n/2 – (n/2 – 2)(n/2 – 1)/2) + an = c/n ( 3n2/4 + n/2 – 2 ) + an = c(3n/4 + ½ – 2) + an ≤ cn – (cn/4 – c/2 – an)
Expected Running Time • It remains to show that we can fix c, and for sufficiently large n ≥ some fixed n0, cn – (cn/4 – c/2 – an) ≤ cn, or equivalently cn/4 – c/2 – an ≥ 0 n(c/4 – a) ≥ c/2 • Let c > 4a, divide by (c/4 – a) n ≥ 2c/(c – 4a) • Assuming E(T(n)) = O(1) for any n < n0 = 2c/(c – 4a), we complete the proof that E(T(n)) = O(n)
An improved randomized algorithm • When calling • RANDOMIZED-SELECT(A, p, r, i) k-th element around which we partition may be far from i-th element • Improvement (Floyd-Rivest): Instead of partitioning around random k, • Select a small sample S from A • Find a member x of S well-placed with respect to i/(r-p) • Partition around x
Floyd-Rivest algorithm, outline • SAMPLESELECT(A, p, r, i) • if r - p < C then return RANDOMIZED-SELECT(A, p, r, i) • given p-r, i, choose parameters m, j “appropriately” • pick a random sample S having m elements of L • x = SAMPLESELECT(S, 1, m, j) • q = PARTITION-AROUND(A, p, r, x) // left as exercise • // now A[p…q-1] < A[q] = x < A[q+1…r] • k = q - p + 1 • if i = k then return A[q] • if i < k • then return SAMPLESELECT(A, p, q-1, i) • else return SAMPLESELECT(A, q+1, r, i-k)
Selecting Sample Size • How can we choose m = |S|, given A of size n = r-p? • Big sample gives better estimate of ith order • Small sample gives better running time of first call • How can we choose j, the jth order of S? • j should be “close” to (i/n)m • if i is small, want j-th elt of S > i-th elt of A (why?) • If i is large, want j-th elt of S < i-th elt of A j = i(m/n) + fudge If i is < n/2, fudge > 0; otherwise, fudge < 0
First recursive call • Let fudge = O(sqrt(m) log n) m elements elements of S, if they were sorted elements of A, if they were sorted ~ fudge*n/m ~ n/m i-th smallest element of A j-th smallest element of S
First recursive call • Let fudge = O(sqrt(m) log n) • Most elements to the right of i are eliminated (i < n/2) m elements elements of S, if they were sorted elements of A, if they were sorted ~ n/m ~ (n log n)/sqrt(m) i-th smallest element of A j-th smallest element of S
Second recursive call • Next, most elements to the left of i-th will be eliminated • Can show probabilistically, that most time is spent in first two recursive calls m’ elements elements of S’, if they were sorted elements of A, if they were sorted i-th smallest element of A j-th smallest element of S
How fast is this algorithm? • Let m = (n log n)2/3, fudge = sqrt(m) log n • One can show that the i-th order statistics can be found in a number of comparisons T(n), where E(T(n)) = n + min(i, n-i) + O((n log n)2/3) • This is much better than the simple randomized algorithm, when n is very large SAMPLESELECT IS OPTIONAL MATERIAL FOR THIS COURSE!
Selection in Worst Case Time O(n) • Idea: we want to guarantee a good split • Then, T(n) = T(an) + O(n), where 0 < a < 1 Therefore T(n) = O(n) at least (1-a)(r-p) elements search for ith element here p q r
Step 1: Find all 5-Medians SELECT(A, p, r, i) • Divide array in groups of 5 • Sort each group (constant time/group) • Find the n/5 medians
Step 2: Find median of medians • Recursively find the median x of the n/5 medians • Time until now: T(n) = O(n) + T( n/5 ) = O(n) x
Step 3: Partition Around x, Recurse kth element • Partition the array around x • Let k = order of x • If i = k, return k Else, if i < k, SELECT(A, p, q – 1, i) else SELECT(A, q+1, r, i-k) p r q: A[q] = x
Running Time • Claim: x is not too small • At least n/10 – 1 medians are ≥x • Therefore, at least 3n/10 – 6 elements are ≥x (Not counting group containing x, & any group with < 5 elements) x
Running Time • Claim: x is not too small • At least n/10 – 1 medians are ≥x • Therefore, at least 3n/10 – 6 elements are ≥x (Not counting group containing x, & any group with < 5 elements) • Claim: x is not too big • Similarly, at least 3n/10 – 6 elements are ≤x x
Derivation that T(n) = O(n) • Assume T(n) = O(1), for n small enough: say n < 140 • For n >= 140, T(n) <= T( n/5 ) +T(7n/10 + 6) + O(n) • Prove by substitution: • Assume T(n’) <= cn’ for all n’ < n • Prove T(n) <= cn
Derivation that T(n) = O(n) T(n) <= T( n/5 ) +T(7n/10 + 6) + O(n) • Substitute T(n) <= cn, put dn instead of O(n) T(n) ≤ c n/5 +7cn/10 + 6c + dn ≤ cn/5 + c + 7cn/10 + 6c + dn = 9cn/10 + 7c + an = cn – (cn/10 – 7c – dn) This is at most cn, if cn/10 – 7c + dn ≥ 0 c ≥ 10 d (n – 70) / n Since n > 140, c ≥ 20d suffices WOULD IT WORK WITH 3-MEDIANS???
Summary of Selection • Randomized selection works well in practice • Expected running time O(n) • SAMPLESELECT works even better, when n is large • Expected number of comparisons n + min(i, n-i) + O((n log n)2/3) • There are algorithms that find i-th element in worst case time O(n) • Large constants, worse than SAMPLESELECT in practice • Best deterministic algorithm to-date performs ~2.95n comparisons • Very complicated • 2.95n is larger than the expected n + min(i, n-i) + O((n log n)2/3)