Download

1 / 32
320 likes | 557 Views
“ Tecniche softcomputing (reti neurali ed algoritmi genetici) per l’analisi dei sistemi complessi applicati alla finanza moderna”. I settori economici e la cluster analysis: dalla teoria dei cluster all’applicazione empirica. Cluster Analysis. Cosa sono i clustering e a cosa servono

E N D
“Tecniche softcomputing (reti neurali ed algoritmi genetici) per l’analisi dei sistemi complessi applicati alla finanza moderna” I settori economici e la cluster analysis: dalla teoria dei cluster all’applicazione empirica
Cluster Analysis • Cosa sono i clustering e a cosa servono • Metodi di classificazione analizzate • Obiettivo all’interno del progetto • Esempi d’applicazione al database Cagliari, 22-23/giugno/2005
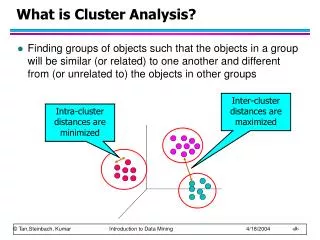
Definizioni • I metodi di cluster analysis o clustering sono finalizzati alla classificazione delle unità statistiche attraverso l’utilizzo di procedure che sono applicabili quando su ogni unità statistica sono state rilevate le modalità di M caratteri • Il processo di cluster consiste nel ripartire un insieme di unità elementari in modo che la suddivisione risultante goda di alcune proprietà considerate desiderabili. (Sokal). • Classificare delle unità statistiche significa formare dei gruppi in modo le unità che sono assegnate allo stesso gruppo siano simili tra loro e che i gruppi siano il più possibile distinti tra loro. (Gordon) Cagliari, 22-23/giugno/2005
Fattori caratterizzanti il clustering • Una misura del grado di diversità tra coppie di unità • Un algoritmo con cui procedere alla realizzazione dei cluster • Modificando la combinazione di questi fattori si creano diverse classificazioni alcune basate sul tipo di algoritmo altre sul tipo di risultato; quelle basate sul tipo di algoritmo si distinguono in metodi gerarchici e non gerarchici. Cagliari, 22-23/giugno/2005
Metodi gerarchici: • Sono caratterizzati da raggruppamenti successivi ordinabili secondo livelli crescenti o decrescenti della distanza e si suddividono in : • Metodi agglomerativi • Metodi scissori • Il primo è più semplice da programmare e ha la capacità di rispecchiare l’effettiva struttura dei dati. Cagliari, 22-23/giugno/2005
Metodi non gerarchici • Sono metodi che dipendono generalmente dalla presenza o meno di centri e sull’esistenza o meno di una funzione obiettivo • Distinzione tra algoritmi: • Esatti • Euristici • Il first best è assegnato ai primi in virtù della omogeneità dei gruppi che riesce a generare. Cagliari, 22-23/giugno/2005
Collocazione della Cluster Analysis Cagliari, 22-23/giugno/2005
Finalità all’interno del progetto • Conoscere i dati e le variabili trattate dal progetto per classificarle nel modo più adatto possibile • Applicazione di un metodo di classificazione gerarchico agglomerativo capace di fornire un analisi ex ante all’applicazione del modello MEU per la spiegazione dello stato di default. Cagliari, 22-23/giugno/2005
Analisi sul database • Il database analizzato: indici di bilancio di 46468 imprese italiane che operato in tutti i settori economici. • La serie dei dati è di quattro anni (1999, 2000, 2001, 2002) per un totale di 185873 osservazioni • Gli indicatori utilizzati sono :51 • Raggruppamento per macro aree e settori, creazione di 50 gruppi. Le imprese sono state classificate secondo le principali linee di business e l’obiettivo di tale classificazione è quello di assicurare che la valutazione ogni società sia appropriata considerando i principali rischi e trend di settore. Cagliari, 22-23/giugno/2005
Analisi sul database • Dopo una prima “processazione” dei dati si è proceduto ad una correzione degli indici: • Missing: sono i valori non disponibili sostituiti nel database con i valori mediani di settore per un dato indice • Outliers: al fine di rendere significativa l’analisi descrittiva sugli indicatori si procede a rapportare gli stessi ai valori percentili ( 5% e 95%) della distribuzione originale dei singoli indicatori Cagliari, 22-23/giugno/2005
Analisi sul database: un esempio • Settori selezionati: • 749 imprese del settore tessile (industriale) • 1089 imprese del settore trasporti terrestri (servizi) • Statistiche: • Media • Mediana • Deviazione standard • Distribuzione degli indici: per settore/ per anno Cagliari, 22-23/giugno/2005
I risultati dell’analisi statistica • Gli indici che sono risultati rilevanti nei due settori per gli anni 2000, 2001, 2002 sono: Cagliari, 22-23/giugno/2005
I risultati dell’analisi statistica • Gli indici che sono risultati rilevanti nei due settori per gli anni 2000, 2001, 2002 sono: Cagliari, 22-23/giugno/2005
Settore tessile Valore aggiunto/ Costo del lavoro Cagliari, 22-23/giugno/2005
Settore tessile Cagliari, 22-23/giugno/2005
Settore trasporti Valore aggiunto/ Costo del lavoro Cagliari, 22-23/giugno/2005
Settore trasporti Cagliari, 22-23/giugno/2005
Settore tessile Margine di struttura secondario Cagliari, 22-23/giugno/2005
Settore tessile Cagliari, 22-23/giugno/2005
Settore trasporti Margine di struttura secondario Cagliari, 22-23/giugno/2005
Settore trasporti Cagliari, 22-23/giugno/2005
Settore tessile Attività disponibili/ esigibilità Cagliari, 22-23/giugno/2005
Settore tessile Cagliari, 22-23/giugno/2005
Settore trasporti Attività disponibili/ esigibilità Cagliari, 22-23/giugno/2005
Settore trasporti Cagliari, 22-23/giugno/2005
Settore tessile Scorte attive/ Totale attività Cagliari, 22-23/giugno/2005
Settore tessile Cagliari, 22-23/giugno/2005
Settore trasporti Scorte attive/ Totale attività Cagliari, 22-23/giugno/2005
Settore trasporti Cagliari, 22-23/giugno/2005
Dendrogramma settore tessile Evoluzione dei cluster Cagliari, 22-23/giugno/2005
Dendrogramma settore trasporti Evoluzione dei cluster Cagliari, 22-23/giugno/2005
Conclusioni • Con la metodologia presentata è possibile analizzare le dinamiche di settore e verificare la coerenza dei codici ateco. • E’ meglio usare la linea di business piuttosto che i codici identificativi Cagliari, 22-23/giugno/2005