Download

1 / 34
350 likes | 416 Views
Understand the historical significance and statistical basis of SVD for solving least squares problems in linear models. Discover how SVD optimizes approximations and reduces errors in overdetermined and underdetermined systems. Learn about the Gauss—Markoff theorem in linear statistical models.

E N D
Singular Value Decomposition SVD Prof. Mariolino De Cecco, Ing. Luca Baglivo Department of Structural Mechanical Engineering, University of Trento Email: mariolino.dececco@ing.unitn.it http://www.mariolinodececco.altervista.org
Applications of SVD: • fitting of a linear model by the least squares method • matrix decomposition and approximation • matrix fundamental subspaces determination SVD - Applications
The linear least squares problem is a computational problem of primary importance, which originally arose from the need to fit a linear mathematical model to given observations. In order to reduce the influence of errors in the observations one would then like to use a greater number of measurements than the number of unknown parameters in the model. The resulting problem is to "solve" an overdetermined linear system of equations. In matrix terms, given a vector b Rm and a matrix A Rmxn, m > n, we want to find a vector x Rn such that Ax is the "best" approximation to b. SVD - Least Squares problem
There are many possible ways of defining the "best" solution. A choice which can often be motivated for statistical reasons and which also leads to a simple computational problem is to let x be a solution to the minimization problem We refer to r = b - Ax as the residual vector A least squares solution minimizes the residual vector norm (the sum of the squared components) It is to note that, if rank (A) < n, then the solution x is not unique. In this case the problem is underdetermined. SVD - Least Squares problem
Laplace in 1799 used the principle of minimizing the sum of the absolute errors with the added condition that the sum of the errors be equal to zero He showed that the solution x must then satisfy exactly n out of the m equations. Gauss argued that since, by the principles of probability, greater or smaller errors are equally possible in all equations, it is evident that a solution which satisfies precisely n equations must be regarded as less consistent with the laws of probability. He was then led to the principle of least squares! SVD - Historical remarks
Let y be a random variable having the distribution function F(y) which is the integral function of the statistical density function F(y) satisfies: The expected value and the variance of y is then defined as: To note that dF(y) is the density function SVD - Statistical preliminaries
Let y = [y1,..., yn]T be a vector of random variables and let = (1 , . . . , n), where i = E{yi}. Then we write = E{y}. If yi and yj have the joint distribution F ( y i , y j ) the covariance IJbetween yi and yj is defined by The variance-covariance matrix V Rnxn of y is defined by SVD - Least Squares problem
Linear models and the Gauss—Markoff theorem. In linear statistical models one assumes that the vector b Rm of observations is related to the unknown parameter vector x Rn by a linear relation: where A G Rmxn is a known matrix and is a vector of random errors In the standard linear model we have i.e., the random variables iare uncorrelated and all have zero means and the same variance. We also assume that rank(A) = n SVD - Least Squares problem
A function g(y) of the random vector y is an unbiased estimate of a parameter if E(g(y)) = When such a function exists, then is called an estimable parameter The best linear unbiased estimator of any linear function is obtained by minimizing the sum of squares ||Ax-b||2 In the general univariate linear model the covariance matrix is V() = 2W, where W Rmxm is a positive semidefinite symmetric matrix. If A has rank n and W is positive definite then the best unbiased linear estimate for x was shown by Aiken [1934] to be the solution of: SVD - Least Squares problem
if Than we have: That means that the residuals are weighted by the experimental errors inverse covariance SVD - Least Squares problem: an example
1.1.4. Characterization of least squares solutions. We begin by characterizing the set of all solutions to the least squares problem (1.1.1). THEOREM 1.1.2. Denote the set of all solutions by Then x S if and only if the following orthogonality condition holds: SVD - Least Squares problem: orthogonality condition
Proof: Assume that x’satisfies ATr’ = 0 Where r’ = b - A x’ Than for any x we have r = b - A x = b - A x’ + A x’ - A x = r’ + A (x’ - x) We can define: r = r’ + A e Squaring: Which is minimized when e = 0, i.e. when x = x’ SVD - Least Squares problem: orthogonality condition
Proof: On the countrary suppose that ATr’ = z (different from 0) Take x = x’ + z ( sufficiently small) Than r = b - A x = b - A x’ - A z = r’ - A z Squaring: Hence x’ is not a least square solution SVD - Least Squares problem: orthogonality condition
It follows that a least squares solution satisfies the normal equations The normal equations are always consistent since: Space definition: SVD - Least Squares problem
Theorem 1,1,3. The matrix ATA is positive definite if and only if the columns of A are linearly independent, i.e. rank(A) = n Proof: if the columns are linearly independent: That means ATA is positive definite On the other end, if the columns are linearly dependent, Therefore is not positive definite SVD - Least Squares problem
From Theorem 1.1.3 it follows that if rank (A) = n, then the unique least squares solution x and the corresponding residual r = b - Ax are given by: SVD - Least Squares solution
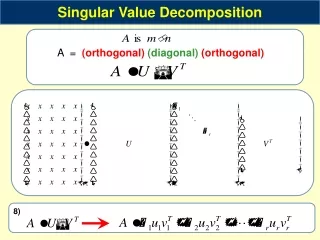
1.2.1. The singular value decomposition. The singular value decomposition (SVD) of a matrix A Rmxn is a matrix decomposition of great theoretical and practical importance. It provides a diagonal form of A under an orthogonal equivalence transformation. The history of this matrix decomposition goes back more than a century However, only recently has the SVD been as much used as it should. Now it is a main tool in numerous application areas such as signal and image processing, control theory, pattern recognition, time-series analysis, etc. SVD - The Singular Value Decomposition
Let A Rmxnbe a matrix of rank r. Then there exist unitary matrices U, V such that: • Where: • Rmxn • = diag (), and • U Rmxm • V Rnxn SVD - The Singular Value Decomposition
The i are called the singular values of A, and if we write: the ui and vi are, respectively, the left and right singular vectors associated with i, i = l,...,r. SVD - The Singular Value Decomposition
A rectangular matrix A Rmxn represents a linear mapping from Rn to Rm. The significance is that it shows that there is an orthogonal basis in each of these spaces, with respect to which this mapping is represented by a generalized diagonal matrix SVD - The Singular Value Decomposition
The SVD of A can be written: The subscript E indicates the so called ‘economy size’ decomposition: only the first r columns of U are computed and S is n-by-n A method for matrix decomposition leads to different practical applications like filtering of noise components that in matrix terms means to extract lower rank matrix approximations! SVD - Matrix decomposition
The SVD gives complete information about the four fundamental subspaces associated with A: SVD - Matrix decomposition
The singular value decomposition plays an important role in a number of matrix approximation problems. In the theorem below we consider the approximation of one matrix by another of lower rank Let A Rmxn have rank r The matrix B Rmxn , among the rank k matrices is the nearest matrix to A, its distance is: SVD - Matrix approximations
Closely related to the singular value decomposition is the polar decomposition. Let A Rmxn m>n There exist a matrix Q and a unique Hermitian (real and symmetric) positive semidefinite matrix H Rnxn such that If rank (A) = n then H is positive definite and Q is uniquely determined SVD - Polar decomposition
Proof: SVD - Polar decomposition
The polar decomposition can be regarded as a generalization to matrices of the complex number representation z = M e iq (module and phase) Represents the module Represents the phase that in matrix form is a rotation matrix (if n=m) The two matrices are unitary (each one can be seen as a rotation matrix) Furthermore, the nearest unitary matrix to A is the unitary factor of the polar decomposition, i.e. Q SVD - Polar decomposition
This problem always has a unique solution, which can be written in terms of the SVD of A as: is called the pseudoinverse of A, and the solution is called the pseudoinverse solution. SVD - solving linear Least Squares problems
1.2.6. Orthogonal projectors and angles between subspaces. An important property of the pseudoinverse is that it gives simple expressions for the orthogonal projections onto the four fundamental subspaces of A: Definition: if S Rm is a subspace, then PS Rmxm is the orthogonal projector onto S if R(Ps) = S SVD - Properties of the pseudoinverse
In error analysis it is useful to have a measure of the size of a vector or a matrix. Such measures are provided by vector and matrix norms, which can be regarded as generalizations of the absolute value A vector norm is a function || • || : Rn R that satisfies the following three conditions: SVD - vector and matrix norm
The most common vector norms are the Holder p-norms: The three most important particular cases are p = 1,2 and the limit when p —> : SVD - vector and matrix norm
The vector 2-norm is the Euclidean length of the vector, and is invariant under unitary transformations, i.e., if Q is unitary: Another important property is the Holder inequality: The special case with p = q = 2 is called the Cauchy-Schwarz inequality SVD - vector and matrix norm
A matrix norm is a function || • || : Rnxm R that satisfies analogues of the three vector norm conditions A matrix norm can be constructed from any vector norm by defining: It is also valid that: SVD - vector and matrix norm
The 2-norm, also called the spectral norm, is given by the first (i.e. the maximum singular value): Since the nonzero singular values of A and ATare the same it follows that: SVD - vector and matrix norm
…. SVD - vector and matrix norm