Download

1 / 18
190 likes | 373 Views
Improved Propensity Matching for Heart Failure Using Neural Gas and Self-Organizing Maps. Leif E. Peterson, Sameer Ather , Vijay Divakaran , Anita Deswal , Biykem Bozkurt , Douglas L. Mann IJCNN, 2009 Presented by Hung-Yi Cai 2010/12/01. Outlines. Motivation Objectives Methodology

E N D
Improved Propensity Matching for Heart Failure Using Neural Gas and Self-Organizing Maps Leif E. Peterson, Sameer Ather, Vijay Divakaran, Anita Deswal, BiykemBozkurt, Douglas L. Mann IJCNN, 2009 Presented by Hung-Yi Cai 2010/12/01
Outlines • Motivation • Objectives • Methodology • Experiments • Conclusions • Comments
Motivation • Heart failure (HF) has a poor prognosis and is a major cause of morbidity and mortality. • Unfortunately, the body of information on risk information for HF among elderly patients is based to a large extent on older heart transplant patients with more severe conditions and more comorbidities. • Therefore, data obtained from older cases are less amenable for non-biased studies of HF.
Objectives The purpose of this paper is to study the effect of four methods of propensity matching on the relative hazard of mortality among NYHA class III-IV heart failure patients vs. patients in NYHA class I-II.
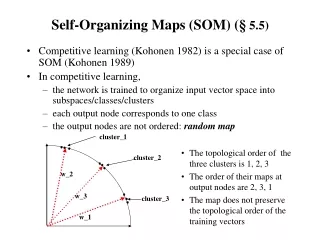
Methodology • Propensity matching with… • Logistic Regression • Neural Gas • Self-Organizing Map • Crisp K-means
Logistic Regression In statistics, logistic regression is used for prediction of the probability of occurrence of an event by fitting data to a logit function logistic curve.
Experiments Time-to-event survival analysis for propensity-matched subjects using Kaplan-Meier analysis and Cox proportional hazards regression.
Experiments Number of matched data based on logit-based propensity matching (N=3,332).
Experiments NG was based on M = 50 nodes. SOM was based on a 7 x 7 square map, and thus M = 49. CKM was based on k = 50.
Experiments Linear fit results for regressing Cox PH Martingaler Residuals on Logits and best-winning nodes for NG and SOM.
Experiments Kaplan-Meier plot of all-cause mortality as a function of having NYHA I-II vs. NYHA III-IV for N = 3,332 subjects propensity matched with logistic regression.
Experiments Kaplan-Meier plot of all-cause mortality as a function of having NYHA I-II vs. NYHA III-IV for N = 3,996 (normalized features) and N = 4,262 (standardized features) subjects propensity matched with neural gas.
Experiments Kaplan-Meier plot of all-cause mortality as a function of having NYHA I-II vs. NYHA III-IV for N = 4,004 (normalized features)subjects and N = 4 ,282 (standardized features) propensity matched with a 7 x 7 (M = 49) self-organizing map.
Experiments Kaplan-Meier plot of all-cause mortality as a function of having NYHA I-II vs. NYHA III-IV for N = 4,248 subjects propensity matched with crisp K-means cluster analysis using k = 50 clusters.
Conclusions • Overall, NG resulted in an increased HR for mortality and explained considerably more variation in Martingale residuals when compared with logit-based propensity matching.
Comments • Advantages • The NG algorithm presents result better than other match method. • Applications • The classification of medical treatment