Download

1 / 11
130 likes | 519 Views
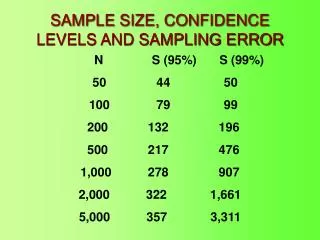
Calculating sampling error. Actually, we’ll calculate what is known (technically) as the confidence interval. This is the “+ or =” number that you hear when sample results are reported. The formula is: 1.96 √(1-f)(p)(1-p)/(n-1), where f = n/N n = sample size N = pop. size

E N D
Calculating sampling error • Actually, we’ll calculate what is known (technically) as the confidence interval. This is the “+ or =” number that you hear when sample results are reported. • The formula is: 1.96 √(1-f)(p)(1-p)/(n-1), where f = n/N n = sample size N = pop. size p = proportion (a sample “response”)
The questions were asked over a period from…. The methodology was used to select and question a representative sample of randomly selected adults. The margin of error is +/- 3 points. • This ABC News/Washington Post poll was conducted by telephone Jan. 26-31, 2005, among a random national sample of 1,204 adults. The results have a three-point error margin.
But 1-f has little effect unless n is large in comparison to N. This is unlikely when the population is large. Examples: If N = 100,000,000 and n equals 1,500, 1-f = .999985. If N = 250,000 and n = 1,500, 1-f = .994 So, unless n is (impossibly) large, or N is small, 1-f can be ignored. (When n/N is about .15 or above, then one needs to think about it.)
So, now we’re left with 1.96 √(p)(1-p)/(n-1) • This is a profound result. Why?
So, to repeat, we’re left with 1.96 √(p)(1-p)/(n-1) This expression is largest if p = .50. So, let’s be conservative and estimate the largest error (confidence interval) for a given sample size. I.e., let p = .50. • Doing this gives us: 1.96 √(.5)(1-.5)/(n-1) = 1.96 √.25/(n-1)
But in this expression, 1.96 √.25/(n-1) we can use n instead of n-1. This gives us 1.96 √.25/(n) • Finally, since we’re approximating, we can use 2 instead of 1.96. And, to make it a percentage rather than a proportion, we can use 200 instead of 2.
So, from 1.96 √.25/(n) we get 200 √.25/(n) • This is a simple, useful approximation of the confidence interval (the + or - number) for a sample of size n. • Example: • n = 500, c.i. = 4.47 (for comp., 196 √(.25)/(n-1) = 4.39)
In short, to answer the question “approximately how accurate is a sample of 1000 respondents,” we simply calculate 200 √.25/(n). The answer is:3.16, or about 3.2%. • If you wish, you can do a little algebra and answer this question: If I want a c.i. of, say, ± 4%, what sample size do I need? (the answer is 625)
Cautionary note: samples of, say, 1000 can represent a large population. But subgroups within that sample may be much smaller. • It’s the subgroup size that matters. • This is one reason why non-simple random samples are taken (to obtain larger subgroup sizes).
Point left out • What I talked about—the ± number you hear reported—is the so-called 95% confidence interval. Suppose it’s three percent. • What this means is that you can be 95% certain that the population proportion will be within 3% of the proportion you find in the sample.
Example: In a survey, you find that 45% of the sample says that they are Republican. The point is made that the sample is accurate to within ± 2.5%. • You can be confident that in the popula-tion, between 42.5% and 47.5% are Rep. (Strictly speaking, this would be correct 19 times out of 20—i.e., 95% of the time.)