Download

1 / 1
10 likes | 169 Views
UK. Kenya. Kenya. UK. US. US. Italy. Italy. Ron Howard. Ron Howard. Norman Jewison. Norman Jewison. Carl Weathers. Carl Weathers. Talia Shire. Talia Shire. Botswana. Botswana. China. Thailand. Thailand. Japan. Japan. China. acted-in. acted-in. directed. directed.

E N D
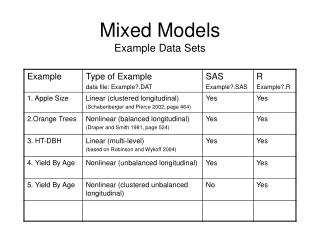
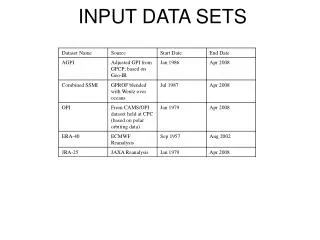
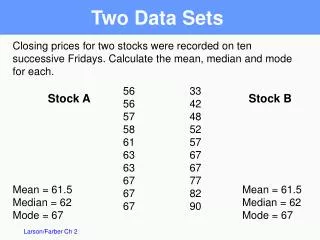
UK Kenya Kenya UK US US Italy Italy Ron Howard Ron Howard Norman Jewison Norman Jewison Carl Weathers Carl Weathers Talia Shire Talia Shire Botswana Botswana China Thailand Thailand Japan Japan China acted-in acted-in directed directed directed directed acted-in acted-in • Overview • Data clustering is the task of detecting patterns in a set of data. • Most algorithms take non-relational data as input and are sometimes unable to find significant patterns. • Many data sets can include relational information, as well as independent object attributes. • Relational data clustering techniques can help find strong patterns in such sets. • Two areas of interest in relational data clustering are: clustering heterogeneous data, and relation selection. Heterogeneous Data It can be very difficult to compare different typed objects. For example, how can actors be compared to directors? One possibility is an inter-cluster relation signature. Open Problems in Relational Data ClusteringUniversity of Maryland Baltimore CountyAdam Anthony aanthon2@umbc.eduMarie desJardins mariedj@cs.umbc.edu 1 Boxing 1 Comedy 1 Boxing 1 Drama • Cluster one set of homogeneous data. This is • the reference clustering. • 2. For each object, Create a vector that records the number of links from that object to each cluster discovered in step 1. This • is the inter-cluster • relation signature. • 3. Cluster all objects based • on the inter-cluster • relation signatures. acted-in directed directed acted-in acted-in acted-in directed directed Boxing Comedy Drama Example Data Sets Relation Selection It is intuitive that, just as some features are not helpful for clustering a data set, some relations might provide little information for a relational clustering algorithm, or even harm the performance of an algorithm. As relational clustering algorithms continue to develop, detecting such graphs will become more important. Feature Space A feature space is a set of objects with attributes, FS = {o1, o2, …, on}, where oi = < a1 , a2, …, am> • Relation Space • A relation space is a set of relation graphs, • RS = {RG1, RG2, ..., RGK}, • where • RGi = {Oi, Ri}, • Oi FS, • and Ri is a set of edges for a specific relation Internet Movie Database Attributes include personal data such as awards received, financial earnings, age, gender, or Hollywood stock exchange rating. Examples of relations are acted-in, directed, and sequel. CIA World Factbook Attribute values come from categories like government, economics, and population. Relations can be derived from sources such as common membership in international organizations. The graph on the right includes an additional relation graph (blue links) that represents the World Trade Organization, which fully connects all countries shown (redundant links omitted). Including the WTO as one of the relation graphs obscures the patterns that can be seen in the graph on the left, making a clustering harder to find. We find this situation to be similar to cases in the feature space where an attribute has the same value for all objects. Removing the WTO graph reduces the size of the total graph, and makes finding patterns easier. G-8 G-8 G-8 UNSC G-8 G-8 UNSC UNSC G-77 G-8 G-77 UNSC AU G-77 G-77 AsDB AsDB UNSC UNSC G-77 G-77 G-77 AsDB G-77 AU G-77 AsDB AsDB • Conclusion • Early research in relational clustering has been successful. • Analyzing relational patterns can help us develop methods for comparing heterogeneous data objects. • Development of relation selection techniques will help improve existing relational clustering algorithms. G-77 AsDB • Prior Research • Join related objects to form independent compound objects, cluster normally (Yin et al., 2005). • Use attribute-based distance measures as weights in a relation graph; adapt a graph cutting algorithm to use edge weights (Neville et al., 2003). • Probabilistic relational model with an adapted EM algorithm (Taskar et al., 2001). • Calculate a hybrid metric that linearly combines relation similarity and attribute similarity, run single-link algorithm (Bhattacharya and Getoor, 2005) References Bhattacharya, I., & Getoor, L. (2005). Entity resolution in graph data (Technical Report CS-TR-4758). University of Maryland. Neville, J., Adler, M., & Jensen, D. (2003). Clustering relational data using attribute and link information. Proceedings of the Text Mining and Link Analysis Workshop. Taskar, B., Segal, E., & Koller, D. (2001). Probabilistic classification and clustering in relational data. Proceeding of IJCAI-01, 17th International Joint Conference on Artificial Intelligence (pp. 870–878). Seattle, US. Yin, X., Han, J., & Yu, P. S. (2005). Cross-relational clustering with user’s guidance. KDD ’05: Proceedings of the Eleventh ACM SIGKDD International Conference on Knowledge Discovery in Data Mining (pp. 344–353). New York, NY, USA: ACM Press. This research funded by NSF grant #0545726