Download
1 / 13
150 likes | 256 Views
Overview of Biostatistical Methods. Overview of Biostatistical Methods. ~ GOLD STANDARD ~ Designed to compare two or more treatment groups for a statistically significant difference between them – i.e., beyond random chance – often measured via a “ p-value ” (e.g., p < .05).

E N D
Overview of Biostatistical Methods ~ GOLD STANDARD ~ Designed to compare two or more treatment groups for a statistically significantdifference between them – i.e., beyond random chance – often measured via a “p-value” (e.g., p < .05). Examples: Drug vs. Placebo, Drugs vs. Surgery, New Txvs. Standard Tx • Let X = decrease (–) in cholesterol level (mg/dL); possible expected distributions: Treatment population Control population RANDOMIZE Treatment Arm Experiment End of Study T-test F-test (ANOVA) Patients satisfying inclusion criteria RANDOM SAMPLES X 0 significant? Control Arm
Overview of Biostatistical Methods ~ GOLD STANDARD ~ Designed to compare two or more treatment groups for a statistically significantdifference between them – i.e., beyond random chance – often measured via a “p-value” (e.g., p < .05). Examples: Drug vs. Placebo, Drugs vs. Surgery, New Txvs. Standard Tx • Let T = Survival time (months); population survival curves: survival probability Kaplan-Meier estimates S(t) = P(T > t) End of Study Log-Rank Test, Cox Proportional Hazards Model AUC difference 1 significant? S1(t) Treatment S2(t) Control T 0
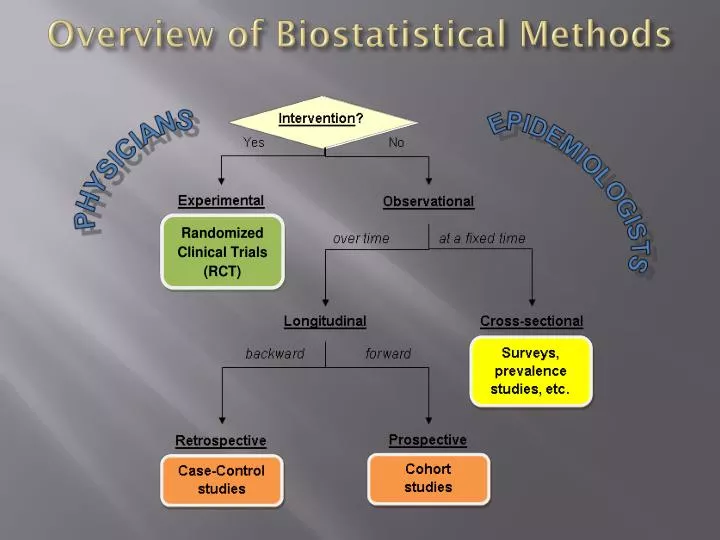
Overview of Biostatistical Methods Cohort studies Case-Control studies
Overview of Biostatistical Methods Observational study designs that test for a statistically significantassociation between a disease D and exposure E to a potential risk (or protective) factor, measured via “odds ratio,” “relative risk,” etc. Lung cancer / Smoking Case-Control studies Cohort studies PRESENT cases controls reference group E+ vs. E– ? D+ vs. D– E+ vs. E– D+ vs. D– ? PAST • relatively easy and inexpensive • subject to faulty records, “recall bias” • measures direct effect of E on D • expensive, extremely lengthy… • Example: Framingham, MA study FUTURE Both types of study yield a 22 “contingency table” of data: where a, b, c, d are the numbers of individuals in each cell. End of Study Chi-squared Test McNemar Test H0: No association between D and E.
Overview of Biostatistical Methods As seen, testing for association between categorical variables – such as disease D and exposure E – can generally be done via a Chi-squared Test. But what if the two variables – say, X and Y – are numericalmeasurements? Furthermore, if sample data does suggest that one exists, what is the nature of that association, and how can it be quantified, or modeled via Y = f(X)? Y Correlation Coefficient measures the strength of linear association between X and Y JAMA. 2003;290:1486-1493 Scatterplot –1 0 +1 r negative linear correlation positive linear correlation X
Overview of Biostatistical Methods As seen, testing for association between categorical variables – such as disease D and exposure E – can generally be done via a Chi-squared Test. But what if the two variables – say, X and Y – are numericalmeasurements? Furthermore, if sample data does suggest that one exists, what is the nature of that association, and how can it be quantified, or modeled via Y = f(X)? Y Correlation Coefficient measures the strength of linear association between X and Y JAMA. 2003;290:1486-1493 Scatterplot –1 0 +1 r negative linear correlation positive linear correlation X
Overview of Biostatistical Methods As seen, testing for association between categorical variables – such as disease D and exposure E – can generally be done via a Chi-squared Test. But what if the two variables – say, X and Y – are numericalmeasurements? Furthermore, if sample data does suggest that one exists, what is the nature of that association, and how can it be quantified, or modeled via Y = f(X)? Y Correlation Coefficient measures the strength of linear association between X and Y JAMA. 2003;290:1486-1493 Scatterplot –1 0 +1 r negative linear correlation positive linear correlation X
Overview of Biostatistical Methods As seen, testing for association between categorical variables – such as disease D and exposure E – can generally be done via a Chi-squared Test. But what if the two variables – say, X and Y – are numericalmeasurements? Furthermore, if sample data does suggest that one exists, what is the nature of that association, and how can it be quantified, or modeled via Y = f(X)? Correlation Coefficient measures the strength of linear association between X and Y For this example, r = –0.387 (weak, negative linear correl)
Overview of Biostatistical Methods As seen, testing for association between categorical variables – such as disease D and exposure E – can generally be done via a Chi-squared Test. But what if the two variables – say, X and Y – are numericalmeasurements? Furthermore, if sample data does suggest that one exists, what is the nature of that association, and how can it be quantified, or modeled via Y = f(X)? Regression Methods Simple Linear Regression gives the “best” line that fits the data. ? residuals Want the unique line that minimizes the sum of the squared residuals. For this example, r = –0.387 (weak, negative linear correl)
Overview of Biostatistical Methods As seen, testing for association between categorical variables – such as disease D and exposure E – can generally be done via a Chi-squared Test. But what if the two variables – say, X and Y – are numericalmeasurements? Furthermore, if sample data does suggest that one exists, what is the nature of that association, and how can it be quantified, or modeled via Y = f(X)? Regression Methods Simple Linear Regression gives the “least squares”regression line. residuals Want the unique line that minimizes the sum of the squared residuals. For this example, r = –0.387 (weak, negative linear correl) Y = 8.790 – 4.733X (p = .0055) For this example, r = –0.387 (weak, negative linear correl) Furthermore however, the proportion of total variabilityin the data that is accounted for by the line is only r2 = (–0.387)2 = 0.1497 (15%).
Overview of Biostatistical Methods • Extensions of Simple Linear Regression • Polynomial Regression – predictors X, X2, X3,… • Multilinear Regression – independent predictors X1, X2,… • w/o or w/ interaction (e.g., X5 X8) • Logistic Regression – binary response Y (= 0 or 1) • Transformations of data, e.g., semi-log, log-log,… • Generalized Linear Models • Nonlinear Models • many more…
Overview of Biostatistical Methods • Sincere thanks to • Judith Payne • Heidi Miller • Rebecca Mataya • Troy Lawrence • YOU!






















