Download

1 / 11
110 likes | 277 Views
Distributed Parity Cache Table. Motivation. Parity updating is a high cost operation Especially for small write operations Read old data 、 Read Old Parity 、 write new data 、 write new parity Basic ideas Delay the generation of parity Cached data could be used without reread

E N D
Motivation • Parity updating is a high cost operation • Especially for small write operations • Read old data、Read Old Parity、write new data、write new parity • Basic ideas • Delay the generation of parity • Cached data could be used without reread • Parity & newly written data could be cached for “the same” write • Beyond parity? • A server-side cooperative cache
Distributed Parity Cache Table • A whole stripe is more meaningful than partial blocks • Local file system cache knows nothing about a whole stripe • Distributed parity cache table knows !! • Small write phenomenon • Could aggregate small writes • Benefits from previous read • Cooperative cache • PVFS does not provide cache
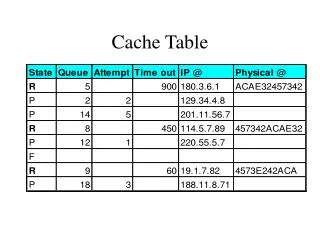
Cache Block • Each block contains 16K data + 256 bytes metadata • DTag : Data tag • PTag : Parity tag • LRef : # of hits in this block • GRef: # of hits in this stripe
Cache Replacement Algorithm IF PTag is null THEN IF Operation is READ THEN USE LRef Field & LRU ELSE IF Dirty bit is Set THEN Write the Parity Block and the replaced Block END IF Write Operation Proceed Update the PTag Field END IF ELSE IF PTag == itself.DTag and DTag != itself.DTag THEN Replace the block ELSE IF PTag != DTag USE LRef Field & LRU END IF END IF