Download

1 / 39
390 likes | 527 Views
Parallele und verteilte Systeme. Peter Brezany Institu t für Softwarewissenschaften Universit ät Wien. Für Rechensysteme mit mehreren CPU's gibt es die unterschiedlichsten Möglichkeiten der Organisation vor allem der Verbindungsstruktur.

E N D
Parallele und verteilte Systeme Peter Brezany Institut für Softwarewissenschaften Universität Wien
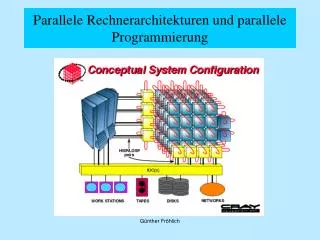
Für Rechensysteme mit mehreren CPU's gibt es die unterschiedlichsten Möglichkeiten der Organisation vor allem der Verbindungsstruktur. Für verteilte Systeme wurden unterschiedliche Klassifikationsschemata entwickelt, von denen sich jedoch keines allgemein durchsetzen konnte. Das wahrscheinlich am häufigsten angewendete Schema ist von Flynn (1972). Flynn unterscheidet zwei Merkmale: die Anzahl der Befehlsströme und die Anzahl der Datenströme. Damit ergeben sich die folgenden Klassen: SISD (Single Instruction Stream, Single Data Stream): Der Rechner hat einen Befehls- und einen Datenstrom. Alle herkömmlichen Einprozessorsysteme fallen unter diese Kategorie. SIMD (Single Instruction Stream, Multiple Data Stream): Hier werden mit einem einzigen Befehlsstrom gleichzeitig mehrere Datenströme verarbeitet. Hierbei handelt es sich um Prozessoren mit einer Befehlseinheit, die eine Anweisung holt und diese Anweisung dann auf mehrere Datenströme anwendet (z.B. sog. Feld, oder Vektorrechner, die eine Anweisung auf alle Komponenten eines Vektors anwenden). Einige Supercomputer gehören zu dieser Klasse. MSID (Multiple Instruction Stream, Single Data Stream): Hier würden mehrere Befehlsströme auf einen Datenstrom angewendet. Es gibt keine Rechner, die nach diesem Prinzip arbeiten. MIMD (Multiple Instruction Stream, Multiple Data Stream): Hier werden mehrere Befehlsströme parallel auf mehrere Datenströme angewendet. Zu dieser Klasse gehören alle verteilten Systeme, so dass diese Klassifikation für die Betrachtung unterschiedlicher Strukturen im Bereich der verteilten System wenig hilfreich ist. Klassifikation paralleler und verteilter Systeme
A typical scientific program spends approx. 90% of its execution time in loops. Example in Java: float A[1000], B[1000]; for (int i = 1; i < 1000; i++) { A[i-1] = B[i]; } The above loop can be expressed in Fortran 95 in the following way: A(0:998) = B(1:999) This statement can be directly mapped onto a SIMD processor. There is an initiative to extend Java by similar constructs. Schleifenparallelisierung für SIMDSs
Distributed-memory machines (DM Multiprocessors, DM MIMDS) Each processor has local memory and disk Communication via message-passing Hard to program: explicit data distribution Goal: minimize communication Shared-memory machines (SM Multiprocessors, SM MIMDs, SMPs) Shared global address space and disk Communication via shared memory variables Ease of programming Goal: maximize locality, minimize false sharing Current trend: Cluster of SMPs Parallele Mehrprozessor-Hardware(MIMD Architekturen)
Distributed Memory Architecture(Shared Nothing) Interconnection Network CPU CPU CPU CPU Local Memory Local Memory Local Memory Local Memory
DMM: Shared Disk Architecture Interconnection Network CPU CPU CPU CPU Local Memory Local Memory Local Memory Local Memory Global Shared Disk Subsystem
Example in Java: float A[10], B[10]; for (int i = 1; i < 10; i++) { A[i] = B[i-1]; } For two processors, P1 and P2, a straightforward solution would be: Schleifenparallelisierung für DM MIMDs
Code on P1: float A[5], B[5]; float temp; for (int i = 1; i < 6; i++) { if ( i == 5 ) { receive message from P2 into temp;A[i-1] = temp; { else A[i-1] = B[i]; } Code on P2: float A[5], B[5]; float temp; for (int i = 0; i < 5; i++) { if ( i == 0 ) { temp = B[0]; send temp to P1; { else A[i-1] = B[i]; } Schleifenparallelisierung für DM MIMDs
Shared Memory Architecture(Shared Everything, SMP) Interconnection Network CPU CPU CPU CPU Global Shared Memory
Example in Java: float A[1000], B[1000]; for (int i = 1; i < 1000; i++) { A[i-1] = B[i]; } If we have, e.g. two processors, P1 and P2, a straightforward (non-optimal) solution would be: Code on P1: for (int i = 1; i < 500; i++) { A[i-1] = B[i]; } Code on P2: for (int i = 500; i < 1000; i++) { A[i-1] = B[i]; } Data elements of A and B are stored in the shared memory. Schleifenparallelisierung für SMPs
Cluster of SMPs Interconnection Network CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU CPU 4-CPU SMP 4-CPU SMP 4-CPU SMP 4-CPU SMP
No Pipeline Pipeline
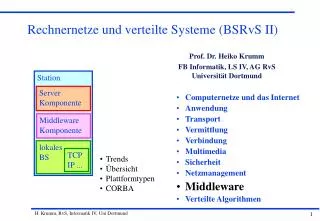
In der Literatur finden sich verschiedene Definitionen verteilter Systeme, die teilweise unterschiedliche Aspekte beleuchten. Für die folgenden Betrachtungen soll von einer sehr allgemeinen Definition ausgegangen werden. Ein verteiltes System ist eine Sammlung voneinander unabhängiger Rechner, die dem Benutzer des Systems den Eindruck vermitteln, es handle sich um einen einzigen Rechner. Die Definition hat zwei Aspekte. Der erste Aspekt betrifft die Hardware und bedeutet, dass es sich um autonome Rechner handelt. Der zweite Aspekt betrifft die Software und legt fest, dass die Benutzer eine gemeinsame Schnittstelle sehen. Eigenschaften verteilter Systeme
Triebkraft der Dezentralisierung der Rechnersysteme waren in der Vergangenheit überwiegend wirtschaftliche und strategische Aspekte. Für zentrale Mainframe-Systeme (der Zeit vor den Mikroprozessoren) wurde von Herb Grosch das sog. "Grosche Gesetz" formuliert, das besagt, dass die Leistungsstärke einer CPU proportional zum Quadrat ihres Preises ist. Wenn doppelt soviel ausgegeben wird, erhält man die vierfache Leistung. Für die Mikroprozessoren trifft dieses Gesetz nicht mehr zu, da man für den doppelten Preis i. a. nur eine etwas höher getaktete CPU erhält. Meist ist es kostengünstiger, eine größere Anzahl billiger CPU's in einem System zu verbinden. Mit den heutigen Mikroprozessoren ist es möglich, ein System mit z.B. 10.000 Prozessoren aufzubauen und so eine Gesamtleistung zu erreichen, die von einem einzigen Prozessor nicht erreicht werden kann. Vorteile verteilter Systeme gegenüber einem zentralen System
Beispiel Ein Rechner mit 10.000 CPU's, die jeweils 100 Mips leisten, hätte eine Gesamtleistung von 1000.000 Mips. Wenn ein einzelner Prozessor (ohne interne Parallelität) diese Leistung erbringen sollte, so müsste er eine Anweisung in 1 psec (1x10-12 sec) ausführen. Die maximale Ausbreitungsgeschwindigkeit von Signalen wird durch die Lichtgeschwindigkeit begrenzt und das ist 0,3 mm in 1 psec. Eine CPU mit einer Kantenlänge von 0,3 mm wurde bei dieser Taktrate eine so hohe Temperatur erzeugen, dass sie schmelzen würde. Ein weiterer Grund für die Entwicklung verteilter Systeme sind Anwendungsbereiche, die inhärent verteilt sind, wie z.B. Warenhausketten mit vielen Verkaufsstellen und mehreren Warenlagern, das Filialsystem von Banken oder die Zusammenarbeit verteilter Entwicklungsgruppen an einem Projekt. Vorteile verteilter Systeme (2)
Ein weiterer Vorteil eines verteilten Systems ist die gegenüber einem zentralen System gesteigerte Verfügbarkeit, z.B. bei einem Ausfall eines Rechners). Daneben ist schließlich die Möglichkeit des inkrementellen Wachstums ein weiterer Pluspunkt. Oft müssen Daten gemeinsam genutzt werden. So benötigen Reisebüros Zugriff auf Datenbanken für die Flugreservierung oder für Hotelbelegungen. Entwicklungsteams arbeiten auf gemeinsamen Projektdaten. Oft sollen nicht nur Daten sondern auch teuere Peripherie wie z.B. Farblaserdrucker oder große Archiv-Speichergeräte gemeinsam genutzt werden. Verteilte Systeme ermöglichen einen flexiblen Lastausgleich, falls rechenaufwendige Arbeiten verteilt werden können. Vorteile verteilter Systeme (3)
Das verteilte System im Vergleich zu einem zentralisierten System zusätzliche Komplexität für den Anwendungsprogrammierer im Umgang bedeutet. Es ist wünschenswert, diese Komplexität zu verbergen - diese Eigenschaft wird in der Literatur als Transparenz bezeichnet. Transparenzkriterien: Ortstransparenz: Sie ermöglicht den Zugriff auf eine Komponente ohne Wissen um ihre physische Lokation. Zugriffstransparenz: Die Art und Weise, wie auf lokale und entfernte Komponenten zugegriffen wird, ist identisch. Ausfalltransparenz: Der Ausfall einer Komponente ist für den Anwender transparent. Technologie-Transparenz: Unterschiedliche Technologien, wie beispielsweise Programmiersprachen oder Betriebssysteme, werden vor dem Anwender verborgen. Concurrency-Transparenz: Dem Anwender bleibt verborgen, dass er sich die Komponenten mit anderen Anwendern teilt. Nachteile verteilter Systeme und Lösungen
Prozessstruktur eines vert. Systems Nachricht Prozess/ Rechner
Die Software ist in verteilten Systemen entscheidend dafür, wie sich das System an der Benutzerschnittstelle präsentiert. Prinzipiell können zwei Arten von Betriebssystemen für System mit mehreren CPU's unterschieden werden: Lose gekoppelte und eng gekoppelte Systeme. Lose gekoppelte Software ermöglicht es den Rechnern und den Anwendern eines verteilten Systems grundsätzlich unabhängig voneinander zu agieren und dennoch in dem notwendigen Maße zu interagieren. Beispiel für ein solches System ist eine Gruppe von PC's (oder Workstations), die alle ihr eigenes BS haben, die aber über ein LAN miteinander verbunden sind und die z.B. gemeinsame Netzwerk-Drucker verwenden. Software-Konzepte
Bei eng gekoppelten Systemen soll z.B. auf allen CPU's an einer gemeinsamen Aufgabe gearbeitet werden, z.B. ein Schachprogramm, bei dem den CPU's jeweils die Auswertung einer Stellung zugewiesen wird. Wenn die Auswertung beendet ist, gibt der Knoten das Ergebnis zurück und erhält eine neue Stellung zugewiesen. Software Konzepte (2)
Das Client-Server-Modell ist eine Möglichkeit, ein verteiltes System zu organisieren. Im Gegensatz zu einem üblichen lokalen System, in dem Services häufig über Unterprogrammaufrufe zur Verfügung gestellt werden, baut das Client-Server-Modell explizit (und für die Anwendung nicht transparent) auf Nachrichten auf. Das Konzept des Remote Procedure Calls (RPC) ermöglicht es Programmen, Prozeduren aufzurufen, die auf anderen Rechnerknoten laufen. Wenn ein Prozess auf einem Rechnerknoten A eine Prozedur auf einem Rechnerknoten B aufruft, dann wird der Prozess auf A solange blockiert, bis die Prozedur auf Rechner B ausgeführt und das Ergebnis zurückgeliefert wurde. Die Probleme, die dabei berücksichtigt werden müssen, sind: Aufrufende und aufgerufene Prozedur laufen in getrennten Adressräumen ab. Parameter und Ergebnis müssen zwischen unterschiedlichen Rechnern übergeben werden. Aspekte der Kommunikation
Client/Server-Model Klient Server Auftrag Klient Antwort Klient
RPC Local vs. remote procedure RPC is an extension of the same type of communication to programs running on different computers; there is still a single thread of execution and the transfer of data between the involved components.
RPC (2) Abbildung 2: Ablauf eines RPC-Aufrufs