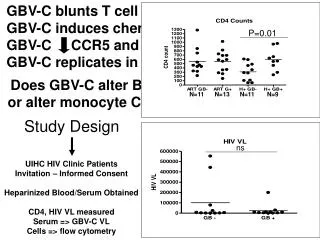
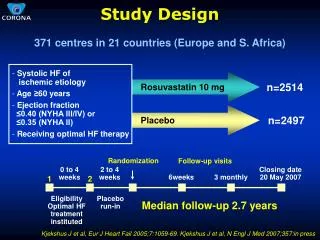
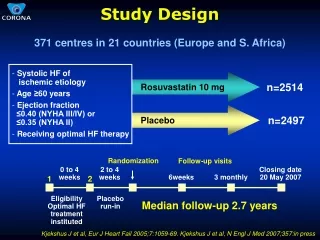
Download

1 / 24
250 likes | 479 Views
Study Design. Topics for today Different kinds of study designs and their advantages and disadvantages Power and sample size calculations Readings Jewell Chapter 5. Conceptual framework. Target population – group on whom we want to draw inferences

E N D
Study Design Topics for today • Different kinds of study designs and their advantages and disadvantages • Power and sample size calculations Readings • Jewell Chapter 5
Conceptual framework Target population – group on whom we want to draw inferences Study population – convenient population (possibly, but not necessarily a subpopulation of target population) from which we can sample Study sample – actual individuals sampled for study
Issues • In essence, we are interested in the following table P(E)? P(D)? Or their association? • Differences between target and study population may lead to bias • How to appropriately draw samples from the study population • Depending on study design, we may not be able to estimate everything
Types of study design • Population-based study • Cohort study • Case-control study
Population-based studies Idea is simple – choose a random sample from the study population How do we do this? It is easier said than done! • Door to door survey? • Phone survey? Ideally, want a sampling frame - listing of all subjects in the population. Sampling frames can be hard to come by, except for small, well defined population (e.g. a list of students enrolled at a university)
Population-based studies (cont’d) Many population-based studies (e.g. NHANES) use classic multi-stage probability-based sampling design, often exploiting population structure characterized through national census. State County Census tract Census block group Households enumerated within block Can account for sampling probabilities in order to estimate disease and exposure prevalences for whole population
Population-based studies (cont’d) Can be • Retrospective - questionnaires and medical tests used to assess past and current exposures and disease outcomes (NHANES). Allows estimation of disease prevalence. Incidence possible based on past reconstruction, but difficult and prone to bias. • Prospective – exposures measured at the time of sampling, then subjects followed forward in time to assess disease onset. Allows estimation of disease incidence NHANES is retrospective. CPP study has both a retrospective and a prospective component
Ecological studies A special kind of population-based study where individuals are not examined, but exposures and possibly even outcomes measured at population level • Arsenic (exposure measured at village level) • Seatbelt laws vs state accident rates Many people argue that ecological studies are a low quality epidemiological study because they are subject to confounding as well as ecological bias.
Cohort studies One of the most common epidemiological designs • Identify exposed and unexposed subgroups from study population and select randomly • Measure disease outcome, other characteristics and confounders. Disease can be assessed • At the time of sampling (prevalence) • Retroactively, e.g. when did person get disease • Prospectively (need to follow cohort forward in time) • Cannot estimate exposure prevalence, but can estimate relative risks, odds ratios etc. • Cannot estimate attributable risk
Examples of cohort studies • Epilepsy study – women identified at the time they gave birth. Subsets of controls and exposed identified for more detailed study. • Womens Health Initiative (University of Washington, Seattle) . This is a randomized cohort study since women are randomly assigned to Hormone Replacement Therapy (HRT) vs placebo
Case-control studies Like a cohort study, except role of exposure and disease reversed: • Identify subpopulation of disease subjects • Identify a subpopulation of non-diseased subjects • Take random sample and measure exposure (and other characteristics and confounders of interest). • Analyze with logistic regression, treating outcome as disease status. Why does this work?
Case/control theory (cont’d) This result tells us that logistic regression applied to case/control data will result in the correct odds ratios associated with exposure X. Only the intercept will be affected by the sampling process. Note that if s1=s0 (cases and controls have same sampling prob), then the usual model applies.
Case/control practical challenges While appealing in theory, case/control studies can be notoriously difficult to execute properly. Cases can usually be found easily (e.g. from hospitals, disease registries etc). Picking appropriate controls is extremely hard. Biggest challenge is ensuring that sampling mechanisms are random with respect to everything except disease status. Best illustrated with some examples.
Case/control example 1 Professor David Christiani from HSPH has been conducting a case-control study in lung cancer. Exposures of interest include smoking, genetic characteristics etc. Cases are patients diagnosed at Massachusetts General Hospital. Controls are spouses or friends of cases Dr Christiani has successfully recruited about 1000 cases and 1000 controls and is getting good results for this study.
Case/control example 2 Dr Christiani has also been conducting a study of arsenic and skin cancer in Taiwan. Exposures of interest are whether or not patients live in arsenic endemic area, as well as measures of toenail arsenic. Cases are patients diagnosed with other diseases at those same hospitals. This was not a successful study in the sense that it did not show an association between skin cancer and arsenic. It was probably “overmatched”. Dr Christiani has another study underway in Bangladesh
Case/control example 3 Dr Christiani has also been conducting a study of petrochemical exposure and childhood leukemia in Taiwan. Exposures of interest are whether or not patients live near a petrochemical plant. Cases are children diagnosed at one of the local hospitals. Cases are randomly from a list of population identification numbers maintained by the city and known to be independent with regard to geography.
Case/Control variants • Nested case/control. Cases and controls both select from a larger cohort. Economical because data collected on large cohort can be very simple. But avoids bias associated with poor control selection since cohort is well defined. Several specialized strategies possible • Risk set sampling • Case-cohort • Matching – pick controls to match certain case characteristics (e.g. age, sex).
Power and Sample Size Consider designing a study to assess association between binary exposure X and binary outcome Y. Let subscript 1 denote control or unexposed and 2 denote exposed group. A popular version of the two-sample binomial is:
Power and Sample Size (cont’d) See SAS PROC POWER
SAS PROC POWER procpower; twosamplefreq test=pchi relativerisk=1.5 refproportion=.1 groupns=800 | 800 power=.; run;