Download

1 / 8
80 likes | 223 Views
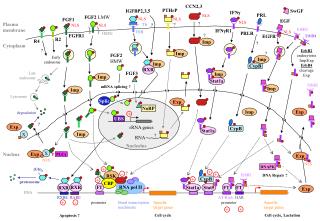
RoloDex Model The Data Cube Model gives a great picture of relationships, but can become gigantic (instances are bitmapped rather than listed, so there needs to be a position for each potential instance, not just each extant instance).

E N D
RoloDex ModelThe Data Cube Model gives a great picture of relationships, but can become gigantic (instances are bitmapped rather than listed, so there needs to be a position for each potential instance, not just each extant instance). The inefficiency described above is especially severe in the very common Bipartite - Unipartite on Part (BUP) relationships. Examples: In Bioinformatics, bipartite relationships between genes (one entity) and experiments or treatments (another entity) are studied in conjunction with unipartite relationships on one of the gene part (e.g., gene-gene or protein-protein interactions). In Market Research, bipartite relationships between items and customers are studied in conjunction with unipartite relationships on the customer part (or on the product part, or both). For this situation, the Relational Model provides no picture and the Data Cube Model is too inefficient (requires that the unipartite relationship be redundantly replicated for every instance of the other bi-part). We suggest the RoloDex Model.
The Bipartite, Unipartite-on-Part Experiment Gene Relationship, EGG So as not to duplicate axes, this copy of G should be folded over to coincide with the other copy, producing a "conical" unipartite card. 4 3 2 1 G G 1 2 3 4 1 1 3 Exp
Axis-Card pair (Entity-Relationship pair), ac(a,b), a support count for AxisSets(or ratio or %): A, for a graph relationship, suppG(A, ac(a,b))=|{b:aA, (a,b)c}| and for a multigraph, suppMG is the histogram over b of (a,b)-EdgeCounts, aA. Other quantifiers can be used also (e.g., the universal, is used in MBR) 16 6 itemset itemset card 5 Item 4 3 2 1 Author People 2 1 1 3 2 2 3 3 4 4 5 4 5 6 7 ItemSet ItemSet antecedent Customer 1 1 1 1 1 1 1 1 5 6 16 1 1 1 1 1 1 1 1 1 Doc 1 2 3 term G 1 2 3 4 5 6 7 Doc 4 3 2 1 PI Gene 3 4 t 5 1 6 1 2 1 3 Gene 3 Exp 4 5 6 7 Conf(AB) =Supp(AB)/Supp(A) Supp(A) = CusFreq(ItemSet) cust item card termdoc card authordoc card Most interestingness measure are based on one of these supports. In IR, df(t) = suppG({t}, tc(t,d)); tf(t,d) is the one histogram bar in suppMG({t}, tc(t,d)) In MBR supp(I)=suppG(I. ic(i,t)) In MDA, suppMG(GSet, gc(g,e)) Of course all supports are inherited redundantly by the card, c(a,b). genegene card (ppi) docdoc People expPI card expgene card genegene card (ppi) RoloDex Model termterm card (share stem?)
Cousin Association Rule Mining Approach (CARMA) card (RELATIONSHIP) c(I,T) one has Association Rules among disjoint Isets, AC, A,C I, with A∩C=∅ and Association Rules among disjoint Tsets, AC, A,C T, with A∩C=∅ Two measures of quality of AC are: SUPP(AC)where e.g., for any Iset, A, SUPP(A) ≡ |{ t | (i,t)E iA}|CONF(AC) = SUPP(AC)/SUPP(A) First Cousin Association Rules: Given any card sharing an axis with the bipartite relationship, B(T,I), e.g., C(T,U) Cousin Association Rules are those in which the antecedent, Tsets is generated by a subset, S, of U as follows: {tT|uS such that (t,u)C} (note this should be called an "existential first cousin AR" since we are using the existential quantifier. One can use the universal quantifier (used in MBR ARs)) E.g., S U, A=C(S), A'T then AA' is a CAR and we can also label it SA' First Cousin Association Rules Once Removed (FCAR1Rs) are those in which both Tsets are generated by another bipartite relationship and we can label antecedent and or the consequent using the generating set or the Tset.
The Cousin Association Rule Mining Approach (CARMA) Second Cousin Association Rules once removed are those in which the antecedent Tset is generated by a subset of an axis which shares a card with T, which shares the card, B, with I and the consequent is generated by C(T,U) (a first cousin, Tset) . 2CAR-1rs can be denoted using any combination of the generating (second cousin) set or the Tset antecedent and the generating (first cousin) or Tset consequent. Second Cousin Association Rules are those in which the antecedent Tset is generated by a subset of an axis which shares a card with T, which shares the card, B, with I. 2CARs can be denoted using the generating (second cousin) set or the Tset antecedent. Second Cousin Association Rules twice removed are those in which the antecedent Tset is generated by a subset of an axis which shares a card with T, which shares the card, B, with I and the consequent is generated by a subset of an axis which shares a card with T, which shares another first cousin card with I. 2CAR-2rs can be denoted using any combination of the generating (second cousin) set or the Tset antecedent and the generating (second cousin) or Tset consequent. Note 2CAR-2rs are also 2CAR-1rs so they can be denoted as above also. Third Cousin Association Rules are those.... We note that these definitions give us many opportunities to define quality measures
Measuring CARMA Quality in the RoloDex Model Item 4 3 2 1 People Author 1 2 3 2 4 3 4 5 5 6 7 Customer 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 Doc 1 2 3 term G 1 2 3 4 5 6 7 Doc 4 3 2 1 PI Gene 3 4 t 5 1 6 1 2 1 3 Gene 3 Exp 4 5 6 7 cust item card termdoc card authordoc card genegene card (ppi) docdoc People For Distance CARMA relationships, quality (e.g., supp or conf or???) can be measured using information on any/all cards along the relationship (multiple cards can contribute factors or terms or in some other way???) expPI card expgene card genegene card (ppi) termterm card (share stem?)
First, we propose definition of Generalized Association Rules (GARs) which contains the standard "1 Entity Itemset" AR definition as a special case. Association Pathway Mining (APM) is a DM technique (with application to bioinformatics?) Given Relationships, R1,R2 (RoloDex cards) with shared Entity,E2, (axis), E1R1E2R2E3 and given AE1 and CE3, then AC , is a Generalized E2 Association Rule, with SupportR1R2(AC) = | {tE2 | aA, (a,t)R1 and cC, (c,t)R2} | ConfidenceR1R2(AC) = SupportR1R2(AC) / SupportR1(A) where as always, SupportR1(A) = |{tE2|aA, (a,t)R1}|. E3=E1, the GAR is a standard AR iff AC=. Association Pathway Mining (APM) is the identification and assessment (e.g., support, confidence, etc.)of chains of GARs in a RoloDex. Restricting to the mining of cousin GARs reduces the number of strong rules or pathways links. Generalized CARMA:
More generally, A E1R1E2R2E3 C Support-SetR1R2(AC) = SSR1,R2(AC) = {tE2|aA (a,t)R1,cC (c,t)R2} If E2 has real labels, Label-Weighted-SupportR1R2(AC) = LWSR1R2(AC) =tSSR1R2label(t) 1 1 1 1 1 1 1 1 SSR1R2 Downward closure property of Support Sets: SS(A'C') SS(AC) A'A, C'C Therefore, if all labels are non-negative, then LSW(AC) LSW(A'C') (in order for LSW(AC) to exceed a threshold is that all LSW(A'C') exceed that threshold A'A, C'C). So an Apriori-like frequent set pair mine would go as: Start with pairs of 1-sets (in E1 and E3). The only candidate 2-antecedents with 1-consequents (equiv, 2-consequents with 1-antecedents) would be those formed by joining ... The weighted support concept can be extended to the case there R1 and/or R2 have labels as well. Vertical methods can be applied by converting E2 to vertical format (E2 instances are the rows and pertinent features from other cards/axes are "rolled over" to E2 as derived feature attributes l2,3 l2,2 E2 R3 R1 E3 E1 C A