Download

1 / 15
150 likes | 298 Views
The use of OCR in the digitisation of herbarium specimens. Robyn E Drinkwater, Robert Cubey & Elspeth Haston. What is happening in digitisation?. … and these minimal data records are going to need data added to them. What are the options when using optical character recognition (OCR)?.

E N D
The use of OCR in the digitisation of herbarium specimens Robyn E Drinkwater, Robert Cubey & Elspeth Haston
… and these minimal data records are going to need data added to them.
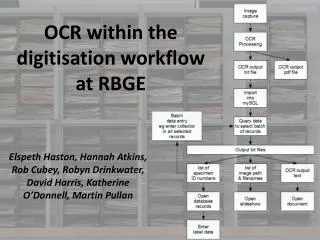
What are the options when using optical character recognition (OCR)? • Parse OCR text directly into the database fields • Use OCR data to prepare the specimens for manual / semi automated data entry
We have had a digitisation project running to digitise all the specimens from SW Asia and the Middle East at RBGE. • Minimal data had been captured originally* • Filing name • Geographical filing region • Barcode • We have been routinely processing all our specimen images through ABBYY OCR software. • * E Haston, R Cubey, DJ Harris (2011). Data concepts and their relevance for data capture in large scale digitisation of biological collections. International Journal of Humanities and Arts Computing 6 (1-2), 111-119.
Step One • We used the OCR output text to pull out over 7,000 specimen images and associated data records • These were then prepared into batches: • some random • some sorted by collector and / or country
Step Two • A team of six digitisers at RBGE completed a series of trials • They used two different protocols for data entry • complete records • partial records (including collector and geographical information but not habitat and description) • In total 7,200 specimens were processed
Results… • Compared to unsorted, random specimens, those which were sorted based on data from the OCR output were quicker to digitise • Of the methods tested here, the most efficient used a protocol based on partial data entry, working with specimens which had been filtered by Collector and Country
The human factor… • Digitisation staff preferred working with sorted specimens • They also preferred working with physical specimens rather than images
Some more thoughts… • This work is more easily applied than parsing data from the OCR output • It can be used in conjunction with other tools later in the digitisation process since these other processes will almost certainly be more efficient with sorted batches of specimens • Other tasks can also be built on top of this: eg condition assessment, QC, etc
It’s surprising what can be used to help filter specimens – the black art of search terms!
Acknowledgments • The digitisation team at RBGE: Nicky Sharp, David Braidwood, Muhammad Ghazali, Lorna Glancy, DorotaJaworska, Esther Nieto. • The Andrew W Mellon Foundation • Dr Antje Ahrends (RBGE) & Dr Chris Glaseby (BIOSS) for statistical advice