Download

1 / 53
530 likes | 770 Views
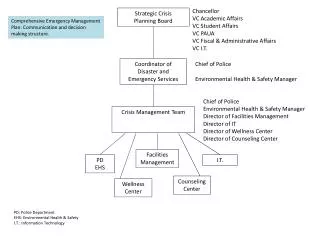
Storage Troubleshooting with VC Ops 5. Things we want to know in performance. The storage team have requested for greater visibility Joint troubleshooting, capacity planning, performance monitoring . Is there any storage bottlenect? If yes, where?

E N D
Things we want to know in performance • The storage team have requested for greater visibility • Joint troubleshooting, capacity planning, performance monitoring. • Is there any storage bottlenect? If yes, where? • You need to know both Big Picture and details • Your needs: • Be able to quickly tell the overall workload • Be able to quickly tell which VMs are generating the big IOPS. • Be able to tell the total IOPS generate from all VMs, and see a chart to see if there is a spike. • You want to know the 3 dimensions • IOPS: Read, Write, Read/Write Ratio, Total IOPS • Latency: Read, Write, Total • Throughput This is a Level 300 material. I’m assuming you’re hands-on on both vSphere 5 and VC Ops 5. This is based on vSphere 5.0.1 and VC Ops 5.0.1 Please read speaker notes.
The challenges • Your environment • Production Site • 500 servers VM, 3000 desktop VM • 2 vCenters, 80 ESXi, 10 clusters, 60 datastores, 6 RDM. • 50 physical servers (mostly UNIX) • You use VMFS on FC and NFS on 10 GE • 2 storage arrays: 1 high end, 1 midrange • DR Site • Let’s not talk about this. The production is complex enough already!
Storage counters: ESXi host Datastore Disk Storage Adapter or Storage Path
ESXi: Adapter, Device and Path 1 adapter can many Devices (LUN). 1 Device is accessed via many paths. 1 path can only access 1 Device.
ESXi: Adapter, Device and Path ESXi 5.0 Storage Adapter 1 Storage Adapter 2 vmnic vmhba2 vmhba3 Storage Path Storage Path Storage Path Storage Path Storage Path Storage Path vmhba3 VMFS VMFS NFS RDM Datastore Datastore Datastore Disk Disk Disk
Storage counters: VM Virtual Disk (VMDK, RDM) VM Drive 1 Drive 2 Drive 3 vDisk vDisk vDisk scsi0:0 scsi0:2 Datastore VMFS NFS RDM Datastore Datastore Disk Disk Disk
VC Ops has 4 groups of Storage metrics for a VM ? Not sure what this is Why only at Disk level? ? Not sure what this is These don’t exist in vCenter. RDM? IOPS counters Other counters Latency counters Thruput counters Don’t use Which counters do you take? There are so many of them. Say you want Write Latency. Which one do you take: Virtual Disk, Datastore, Disk, or Storage? I’ll try to answer in the next few slides. If you want to know now, the counter with the black arrow is the counters that I think we should use.
Comparing VC Ops with vCenter Datastore shows the metric for this VM only, not for every VM in that datastore. Datastore figures will be higher if your VM has snapshot. Disk = physical LUN backing up the datastore. If there is no extent, then Disk = Datastore. Where does the Storage counter come from, as there is no Storage in vCenter? vCenter only has Datastore, Disk, Virtual Disk, as shown in this screenshot. If you know, let me know.
VC Ops has 2 groups of Storage metrics for a Datastore NFS datastore VMFS datastore IOPS counters Other counters Latency counters Not sure the difference between Max Observed and Highest Observed Which counters do you take? There are so many of them. Say you want Write Latency. Which one do you take: Virtual Disk, Datastore, Disk, or Storage? I’ll try to answer in the next few slides. Thruput counters
VC Ops has 4 groups of Storage metrics for a ESXi IOPS counters Other counters Latency counters Thruput counters Which counters do you take? There are so many of them. Say you want Write Latency. Which one do you take: Virtual Disk, Datastore, Disk, or Storage? I’ll try to answer in the next few slides.
VC Ops: Storage metrics from Cluster until World Cluster Datacenter vCenter World Notice Storage is not the group, but Disk. I was hoping for Storage as it is more intuitive. For IOPS or Throughput, it is the sum of all components (e.g. all VM in that vCenter) For Latency, I’m not sure if it is an average, or the max. If it is a Max, that would be an awesome Super Metric! IOPS counters Other counters Latency counters Thruput counters
vCenter: performance chart This is the object name. In this case, this is a VM and its name is vCenter5 This one tells us that it is the Datastore group, and it is showing Past day data (last 24 hours)
vCenter Ops might aggregate differently than vCenter Same info, but this time from vCenter Ops. They are similar, but not identical. Is this because the way VC Ops aggregate? Read peaks at 245 in vCenter vs 217 in VC Ops. Around 13% lower in VC Ops. Write peaks at 137 vs 135. This is close enough.
IOPS: Snapshot causes real IOPS penalty This is from the Virtual Disk counters. 173 reads at Virtual Disk translates into 245 reads at Datastore. This is 40% more 70 writes at Virtual Disk translates into 137 writes at Datastore. This is almost 200%! So a snapshot can cause much higher IOPS.
IOPS: Conclusion • Use the Datastore counter for vmdk • The Virtual Disk counter is useful if you are comparing with actual IOPS issued at Guest OS level. It will be too low if you have snapshot. • The Storage counter = Virtual Disk • The Disk counter is useful if you are discussing with the Storage team, who is showing you LUN by LUN metrics. Disk = LUN. • It is not useful if your datastore spans multiple LUNs due to Extent. • In most cases, Disk = Datastore as you should avoid Extent. • Use the Disk counter for RDM • VC Ops counter may differ to vCenter • If the number looks strange, check with vCenter. • Sometimes the data in vCenter itself is wrong. • Check a few VMs, not just 1.
Latency: Conclusion • Use the Datastore counter for vmdk • The Virtual Disk counter is useful if you are comparing with actual IOPS issued at Guest OS level. It will be too low if you have snapshot. • The Storage counter = Virtual Disk • The Disk counter is useful if you are discussing with the Storage team, who is showing you LUN by LUN metrics. Disk = LUN. • It is not useful if your datastore spans multiple LUNs due to Extent. • In most cases, Disk = Datastore as you should avoid Extent. • Use the Disk or Virtual Disk counter for RDM • VC Ops counter may differ to vCenter • If the number looks strange, check with vCenter. • Sometimes the data in vCenter itself is wrong. • Check a few VMs, not just 1.
Latency: Conclusion • Do not use the Total Latency • When creating super metric, manually add the Read and the Write. • Use the Datastore counter for vmdk • Use the Disk counter for RDM • VC Ops counter may differ to vCenter • If the number looks strange, check with vCenter. • Sometimes the data in vCenter itself is wrong. • Check a few VMs, not just 1.
Throughput: Conclusion • Use the Datastore counter for vmdk • The Virtual Disk counter is useful if you are comparing with actual IOPS issued at Guest OS level. It will be too low if you have snapshot. • The Storage counter = Virtual Disk • The Disk counter is useful if you are discussing with the Storage team, who is showing you LUN by LUN metrics. Disk = LUN. • It is not useful if your datastore spans multiple LUNs due to Extent. • In most cases, Disk = Datastore as you should avoid Extent. • Be careful with the Disk counters, as they can report large numbers • vCenter: Disk | Disk Throughput usage • vC Ops: Disk | IO Usage capacity • VC Ops counter may differ to vCenter • If the number looks strange, check with vCenter. • Sometimes the data in vCenter itself is wrong. • Check a few VMs, not just 1.
Built-in Super Metric? • The 3 chart below shows summary at World level • The actual world is on the right. It has 5 vCenters