Download

1 / 7
70 likes | 218 Views
Skip Lists – Why?. BSTs Worse case insertion, search O(n) Best case insertion, search O(log n) Where your run fits in O(n) – O(log n) depends on the order of the data Hard to keep balanced 2-3 trees Guaranteed to be balanced Complicated to implement. Skip List.

E N D
Skip Lists – Why? • BSTs • Worse case insertion, search O(n) • Best case insertion, search O(log n) • Where your run fits in O(n) – O(log n) depends on the order of the data • Hard to keep balanced • 2-3 trees • Guaranteed to be balanced • Complicated to implement
Skip List • Still no guarantee to be O(log n) for insertion, search, deletion, in every situation. • Will give O(log n) performance with high probability (in most runs). • Good compromise between performance and difficulty of implementation.
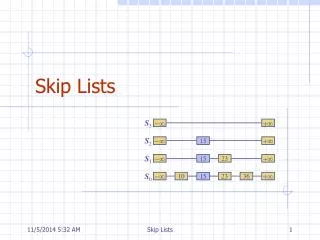
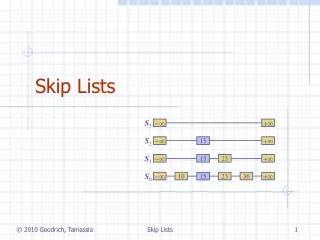
What is it? • Recall the ordered linked list with one pointer to the next item. (worst case O(n), avg O(n/2) ) • Add a pointer to every other node that points to the second next (current+2). (worst case O(n/2) ) 37 49 2 15 21 29
What (cont.) • Now add in a third level so that every 4th item points 4 beyond it • • Add a (log n) level so that every (n/2)th item points n/2 away from it. • Now search is O(log n) • But insertion (and keeping “balanced”) is VERY difficult.
Probabilistic Structure • Rather than worrying about being perfect, just be good in the long run (especially if it is difficult to be perfect. • The number of pointers is the level of the node. • Randomly pick a level. • Want an exponential distribution with 50% being level 1, 25% being level 2, …
Sidebar – Implementing this Random Function • Flipping a coin gives us a 50% chance of getting a head. • If we get a tail on the first flip, then flip again. The chance of getting a TH is 25% • P(TTH) = 12.5% • Use a random number generator that generates uniformly distributed random numbers 0 or 1) • Count the number of times it takes to get a 0 • This will be the level and it will occur with the proper frequency (in the long run, i.e. with big enough data sets.
Operations • Search – easy • Insert • Pick level • Find position • Keep track of previous node for each level used in the search. • Update next pointers in “previous nodes” from level “picked level” to 0 (as well as the next in the inserted node). i.e., splice the node into the lists that it is part of.