Download

1 / 42
420 likes | 541 Views
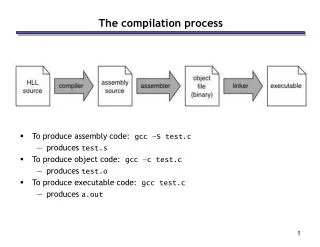
Automatic compilation. Student name: Eldad Uzman Student ID : 036544062 Lecturer : DR Itzhak Aviv. Introduction to compilation. A compiler is a program that translates one programming language to another. Its input is the source language; its output is the target language.

E N D
Automatic compilation Student name: Eldad UzmanStudent ID : 036544062Lecturer : DR Itzhak Aviv
Introduction to compilation A compiler is a program that translates one programming language to another. Its input is the source language; its output is the target language. The most known form of compiling is to read a program in one programming language, namely: C, C++, JAVA, C# and VB, and to translate it to an equivalent Assembly code or binary code for the machine to execute. Far more than just writing a program, these tools are needed in many other fields of software engineering.
Why compilation tools are needed? A common mistake among many programmers is the attitude that if your code is being compiled successfully, release it. It is clear that more complex software, that involves many external tools and have a rough need for integration, there’s a need for more than just to compile the code.
System concept System design Functional specifications Component design Program and unit tests Integration and system tests Conversion and installation Operation and maintenance System engineer life cycle
Release management Release Management is the relatively new but rapidly growing discipline within software engineering of managing software releases. As software systems, software development process, and resources become more distributed, they invariably become more specialized and complex. Furthermore, software products are typically in an ongoing cycle of development, testing, and release. Add to this an evolution and growing complexity of the platforms on which these systems run, and it becomes clear there are a lot of moving pieces that must fit together seamlessly to guarantee the success and long-term value of a product or project.
My engine version Software binary code JS files C++ code My final project I don’t want to compile ALL the code, but just some fragments of it. I need an external tool that will allow me to chose the exact fragments that are necessary for the specific version.
How does a compiler works? There are countless source languages and target languages and there are many kinds of compilers as well. However, despite of this apparent complexity, the fundamental tasks that any compiler must implement are virtually the same. There are two parts to compilation: 1) Analysis – breaking up the source program into constitute pieces and creates an intermediate representation (IR) of the source program. 2) Synthesis – construction of the desired target code from the IR.
Analysis In order to break up the structure and to understand the meaning of the program, the compiler will execute the three phases in the analysis stage: • Lexical analysis – breaking the input to words or tokens. • Syntax analysis – parsing the phrase structure of the program • Semantic analysis – calculating the meaning of the program.
Intermediate representation (IR) Intermediate representation is a data structure that is constructed from the data to a program and from which parts of the output data of the program is constructed in turn.
Lexical analysis Also called linear analysis or scanning. In this phase we will break the source code to tokens , place them on a tree with a left to right reading process. Example: position = initial +rate*60; Would be grouped as: • The identifier position. • The assignment symbol. • The identifier initial • The plus sign • The identifier rate. • Times sign • The number 60
Syntax analysis Also called hierarchical analysis or parsing. In this phase we will group the tokens into grammatical phrases into a syntax tree. Note: The division between syntax analysis and lexical analysis is debatable.
typedef char* string; typedef struct A_stm_ *A_stm; typedef struct A_exp_ * A_exp; typedef struct A_expList_ *A_expList; typedef enum {A_plus, A_minus, A_times, A_div} A_binop; //statement struct struct A_stm_ {enum {A_compoundStm, A_assignStm, A_printStm }kind; union{struct {A_stm stm1, stm2;}compound; struct {string id, A_exp exp;}assign; struct {A_expList exps;} print; }u; }; //statement types constructors A_stm A_CompoundStm(A_stm stm1, A_stm stm2) { A_stm s = malloc(sizeof(*s)); if(s ==null){ stderr("error allocating memory"); exit(0); } s->kind = A_compoundStm; s->u.compound.stm1 = stm1; s->u.compound.stm2 = stm2; return s; } A_stm A_AssignStm(string id, A_exp exp) { A_stm s = malloc(sizeof(*s)); if(s ==null){ stderr("error allocating memory"); exit(0); } s->kind = A_assignStm; s->u.assign.id = id; s->u.assign.exp = exp; return s; } A_stm A_PrintStm ( A_expList exps) { A_stm s = malloc(sizeof(*s)); if(s ==null){ stderr("error allocating memory"); exit(0); } s->kind = A_printStm; s->u.print.exps = exps; return s; }
//Expression constructors A_exp A_numExp ( int num ) { A_exp e = malloc(sizeof(*e)); if(e ==null){ stderr("error allocating memory"); exit(0); } e->kind = A_numExp; e->u.num = num; return e; } A_exp A_opExp ( A_stm stm , A_exp exp ) { A_exp e = malloc(sizeof(*e)); if(e ==null){ stderr("error allocating memory"); exit(0); } e->kind = A_opExp; e->u.op.left = left;e->u.op.oper = oper; e->u.op.right = right; return e; } //Expression struct struct A_exp_ { enum { A_idExp, A_numExp, A_opExp, A_eseqExp } kind; union { string id; int num; srtuct { A_exp left; A_binop oper; A_exp right;}op struct { A_stm stm; A_exp exp ; }eseq; } u; }; A_exp A_IdExp (string id) { A_exp e = malloc(sizeof(*e)); if(e ==null){ stderr("error allocating memory"); exit(0); } e->kind = A_idExp; e->u.id = id; return e; }
A_exp A_EseqExp ( A_exp left , A_binop oper , A_exp right ) { A_exp e = malloc(sizeof(*e)); if(e ==null){ stderr("error allocating memory"); exit(0); } e->kind = A_eseqExp; e->u.eseq.stm = stm; e->u.eseq.exp = exp;e->u.op.right = right; return e; } //experessions list struct struct A_expList_ {enum { A_pairExpList, A_lastExpList } kind; union { struct {A_exp head; A_expList tail;} pair; A_exp last; } u; //expression list constructor A_expList A_PairExpList (A_exp head, A_expList tail) { A_expList el = malloc (sizeof(el)); If(el == null){ stderr("error allocating memory"); exit(0); } el->kind = A_pairExpList; el->u.pair.head = head; el->u.pair.tail = tail; return el; } A_expList A_LastExpList (A_exp last) { A_expList el = malloc (sizeof(el)); If(el == null){ stderr("error allocating memory"); exit(0); } el->kind = A_lastExpList; el->u.last = last; return el; }
Syntax analysis example A_stm prog = A_CompoundStm(A_AssignStm(“a”, A_OpExp(A_NumExp(5),A_plus, A_numExp(3))), A_CompoundStm(A_AssignStm(“b”, A_EseqExp(A_printStm(A_PairExpList(A_IdExp(“a”), A_LastExpList(A_OpExp(A_IdExp(“a”),A_minus, A_NumExp(1))))), A_OpExp(A_NumExp(10), A_times, A_IdExp(“a”)))), A_printStm(A_LastExpList(A_IdExp(“b”)))));
compoundStm assignStm compoundStm a opExp assignStm printStm numExp b eseqExp numExp plus lastExpList 5 printStm 3 opExp idExp pairExpList idExp times numExp b idExp lastExpList 10 a opExp a idExp minus numExp 1 a syntax analysis tree
Semantic analysis In this phase we will check the source program for semantic errors and gather type information for the code generation phase. There are many checks included in the semantic analysis phase but the most important one is the type checking. Type checking verifies that each operator has the permitted number of operands. To do that, we need to write all our identifiers on a special data structure called the symbol table.
key1 key2 key3 key4 key5 key6 Symbol table The basic data structure of the symbol table is the HASH table, that allows us to find each key in a constant complexity value Hash function value1 value2
Implementation of hash table struct bucket {string key; void* binding; struct bucket* next;}; #define SIZE 109 struct bucket *table[SIZE]; Unsigned int hash (char* s0){ Unsigned int h =0 ; char *s; for(s=s0;*s;s++) h=h*65599 +*s return h; } struct bucket* Bucket(string key, void* binding, struct bucket* next){ struct bucket* b= malloc(sizeof(*b)); if(b==null) {stderr(“error allocating memory”); exit(0); } b->key = key; b->binding = binding; b->next = next; return b; } void insert (string key, void *binding){ int index = hash(key)%SIZE; Table[index] = Bucket(key,binding, table[index]); } void * loockup(string key){ int index = hash(key)%SIZE; struct bucket *b; for(b= table[index]; b; b= b->next) If(0==strcmp(b->key,key))return b->binding; return null; } Typedef struct S_symbol_ *S_symbol; Struct S_Symbol_ { string name, S_symbol next;};
Types module typedef struct TY_ty_ *TY_ty; typedef struct TY_tyList_ *TY_tyList; typedef struct TY_field_ *TY_field; typedef struct TY_fieldList_ *TY_fieldList; struct TY_ty_ {enum{Ty_record, Ty_nil, Ty_int, Ty_string, ty_array, Ty_name, Ty_void} kind; union {TY_fieldList record; TY_ty array; struct{ S_symbol sym; Ty_ty ty;}name}name; } u; }; TY_ty TY_Nill(){ TY_ty ty = malloc(sizeof(*ty)); if(ty == null) { stderr(“error allocating memory”); exit(0); } Ty->kind = Ty_nil; return ty; } TY_ty TY_Int(); TY_ty TY_String(); TY_ty TY_Void(); struct TY_tyList_ { TY_ty head; TY_tyList tail}; TY_tyList TY_TyList(TY_ty head, TY_tyList tail){ TY_tyList tyl = malloc(sizeof(*tyl)); if(tyl==null) { stderr(“error allocating memory”); exit(0); } tyl->head = head; tyl->tail = tail; return tyl; } struct TY_field_ {S_symbol name; TY_ty ty}; TY_field TY_Field(S_symbol name; TY_ty ty); {…} struct TY_fieldList {TY_field head; TY_fieldList tail}; TY_fieldList TY_FieldList (TY_field head, TY_fieldList tail);
Type checking Now it’s all simple, All we need to do is to make a left to right scan over the syntax tree produced in the syntax analysis, and each time we found an operators, we need to check the descending nodes of the current operators.
compoundStm assignStm compoundStm a opExp assignStm printStm numExp b eseqExp numExp plus lastExpList 5 printStm 3 opExp idExp pairExpList idExp times numExp b idExp lastExpList 10 a opExp a idExp minus numExp 1 a
Intermediate code typedef struct T_stm_ *T_stm; struct T_stm_ { enum {T_SEQ, T_LABEL, T_JUMP, T_CJUMP, T_MOVE, T_EXP} kind; union{ struct {T_stm left , right} SEQ; Label LABEL; struct { T_exp dst; labelList labels } JUMP; struct { T_relOP op; T_exp left, right; Label true , false;} CJUMP; struct { T_exp dst , src;} MOVE; struct { T_exp exp; } T_EXP; } u; }; {T_stm Constructors…} typedef struct T_exp_ *T_exp; Struct T_exp_ {enum { T_BINOP, T_MEM, T_TEMP, T_ESEQ, T_NAME, T_CONST, T_CALL} kind; union {struct {T_binOp op ; T_exp left, right;} BINOP; T_exp MEM; Temp_ TEMP; struct {T_stm stm ; T_exp exp;} ESEQ; Label NAME; int CONST; struct {T_exp exp; T_expList expList; } CALL; } u; }; {T_exp constructors…} Now after the analysis is completed, we know the meaning of the source code, we know the code is correct, we can generate the intermediate code.
Intermediate code (cont) typedef struct T_expList_ *T_expList; struct T_expList_{T_exp head; T_expList tail;} T_expList T_ExpList (T_exp head, T_expList tail); typedef struct T_stmList_ *T_stmList; struct T_stmList_{T_stm head; T_stmList tail;} T_stmList T_StmList (T_stm head, T_stmList tail); Typedef enum {T_plus, T_minus, T_mul, T_div, T_and, T_or, T_lshift, T_rshift, T_arshift, T_xor} T_binOp; Typedef enum {T_eq, T_ne, T_lt, T_div, T_gt, T_le, T_ge, T_ult, T_ule, T_ugt , T_uge} T_relOp; So far we have dealt with expressions that computes a value, we must expend it to expressions that do not compute values, namely : void functions (or procedures), while instructions and Boolean conditions that may jump to true or false labels.
Intermediate code (cont) //patch list: typedef struct patchList_ *patchList; struct patchList_ {Label *head ; patchList tail}; patchList PatchList(Label *head , patchList tail); Tr_ex – stands for expressions Tr_nx – stands for “no result” Tr_cx – stadns for conditions, the statement may jump to one of the true or false labels in the two given lists. //translation: typedef struct Tr_exp_ *Tr_exp; struct Cx {patchList trues , falses ; T_stm stm;}; struct Tr_exp_ {enum {Tr_ex , Tr_nx, Tr_cx} kind union {T_exp ex; T_stm nx ; struct Cx cx;}u; }; {constructors…}
assignStm opExp id1 opExp id2 + numExp id3 * 60 What do we get so far? Position = initial + rate * 60; Lexical analysis Id1, EQ, id2, PL, id3, Mul, number(60), endl Syntax analysis Semantic analysis
Intermediate code generator temp 1 = number(60) temp2 = id3 * temp1 temp 3 = id2 + temp2 id1 = temp3 What do we get so far? (cont) Intermediate representation has been generated, we are ready for the synthesis phase, now we can generate the machine code.
Synthesis • Now that we have the intermediate representation, we • can generate the machine code. • In fact , the intermediate code is a code for an abstract • machine, so all we need to take care of in the Synthesis • phase is: • Instruction selection – finding the appropriate machine instructions to implement a given intermediate tree. • Registers allocation – allocations of variables to machine registers.
Instruction selection Unlike other phases when we performed a left to right scan over the tree, this time the scan will be DFS. Our intention is to find tree patterns.
+ * / MEM MEM + MEM + const + + const const const const MOVE MEM + const const MEM MOVE MEM + const
Maximum munch In order to generate a target code with the minimal number of machine instructions, we need to find the optimal tiling for a pattern. An optimal tiling is one where no adjacent tiles can be combined into a single tile. There’s an algorithm that finds the optimal tiling in a tree, and it’s the maximum munch also known as largest match. Maximum munch has the concept of a greedy algorithm, once it found the largest match, it doesn’t need any improvements afterward.
void maximuMunchStm (T_stm s){ switch(prog->kind) { case T_SEQ: { maximuMunchStm (s->u.left); maximuMunchStm (s->u.right); } case T_MOVE{ T_exp dst = s->u.MOVE.dst , src = s->u.MOVE.src; if (dst ->kind==T_MEM) if(dst->u.MEM->kind ==T_BINOP && dst->u.BINOP.op==T_plus && dst->u.MEM->u.BINOP.right->kind == T_CONST{ T_exp e1 = dst->u.MEM->u.BINOP.left, e2=src; munchExp(e1); MunchExp(e2); emit(“STORE”); else if(dst->u.MEM->kind ==T_BINOP && dst->u.BINOP.op==T_plus && dst->u.MEM->u.BINOP.left->kind == T_CONST{ T_exp e1 = dst->u.MEM->u.BINOP.right, e2=src; munchExp(e1); MunchExp(e2); emit(“STORE”); else if (src->kind==T_MEM ){ T_exp e1 = dst->u.MEM, e2=src->u.MEM; munchExp(e1) ; munchExp(e2) emit(“MOVEM”); else{ T_exp e1 = dst->u.MEM, e2=src; munchExp(e1) ; munchEcp(e2); emit(“STORE”); else if (dst->kind == T_TEMP) { T_exp e2 = src; munchExp(e2); emit(“ADD”);} Maximum munch (cont)
MunchExp(T_exp exp){ switch (exp->kind){ case T_ESEQ:{ maximummunchStm(Exp->u.ESEQ->stm); MunchExp(Exp->u.ESEQ->exp); } case T_MEM: { T_exp e =exp->u.MEM ; If(e.kind ==T_BINOP && e->u.BINOP.op = T_plus && e->u.BINOP.right->kind ==T_CONST){ MunchExp(e->u.BINOP.left); emit (itoa(e->u.BINOP.right->u.CONST));emit (“LOAD”); } else If(e.kind ==T_BINOP && e->u.BINOP.op = T_plus && e->u.BINOP.left->kind ==T_CONST){ MunchExp(e->u.BINOP.right); emit (itoa(e->u.BINOP.left->u.CONST)); emit (“LOAD”); } else if (e.kind ==T_CONST){ emit (itoa(e->u.BINOP.right->u.CONST)); emit (“LOAD”); } else { emit (“LOAD”); } case T_BINOP:{ T_exp e = exp->u.BINOP; If(e->kind == T_plus && e->right->kind == T_CONST){ MunchExp(e->u.BINOP.left); emit (itoa(e->u.BINOP.right->u.CONST));emit (“ADD1”); } else if(e->kind == T_plus && e->left->kind == T_CONST){ MunchExp(e->u.BINOP.right); emit (itoa(e->u.BINOP.left->u.CONST)); emit (“ADD1”); } //cont…
else If(e->kind == T_minus && e->right->kind == T_CONST){ MunchExp(e->u.BINOP.left); emit (itoa(e->u.BINOP.right->u.CONST));emit (“SUB1”); } else if (b->kind = T_plus){ MunchExp(e->u.BINOP.left); MunchExp(e->u.BINOP.right);emit (“ADD”); } else if (b->kind = T_minus){ MunchExp(e->u.BINOP.left); MunchExp(e->u.BINOP.right);emit (“SUB”); } else if (b->kind = T_mul){ MunchExp(e->u.BINOP.left); MunchExp(e->u.BINOP.right);emit (“MUL”); } else if (b->kind = T_div){ MunchExp(e->u.BINOP.left); MunchExp(e->u.BINOP.right);emit (“DIV”); } case T_CONST:{ emit (“ADD1”); } }
Register allocation All the phases we discussed assumes that there are an Unlimited amount of registers. We know that this number is limited and hence we need a method to deal with it. Two temporaries can fit into the same register if the are not “in use” at the same time, so the compiler needs to analyze the intermediate program to determine which temporaries are in use at the same time. This phase called, liveness analysis.
2 1 3 4 5 5 b=a+1 a=0 c=c+b a=b*2 a<N return c Control flow graph In order to solve the problem, we’ll use controlflow graph the nodes in the graph stands for the statements. If the statement X can be followed by statement y the edge (x,y) exists on the graph. a <- 0 L1 : b <- a+1 c <- c+b A <- b*2 If a < N goto L1 return c
Liveness analysis terminology - A flew graph has out-edges that leads to the successors (succ). - A flew graph has out-edges that leads to the predecessors (pred). - An assignment to a variable or temporary defines it (def). - An occurrence of a variable or temporary on the right side of the assignment uses it (use).
Liveness of a variable definition A variable lives on an edge if there’s a path to a use of the variable through that edge that doesn’t go through any of it’s def A variable is live-in a node if it lives on any one of it’s in edges. A variable live-out a node if it lives on any one of it’s out edges. equations
Liveness of a variable (cont) algorithm
Liveness of a variable (cont) Run time complexity For a control flow graph with N nodes: The first foreach provides N iterations. Then there’s a nested loops, in which the inner loop is a foreach and each iteration of the foreach loop has a union operation in it, worst case for this union is if the control flow graph is whole, and the union will provide N iterations maximum, so with the complexity of the inner foreach loop is Each iteration of the repeat iteration deals with a single edge that can be either in or out edge, so the complexity of the repeat loop is
Liveness of a variable (cont) Run time complexity (cont) The worst case complexity of the algorithm is However in reality, it runs in time between and