Download

1 / 56
560 likes | 699 Views
LAST : A single-mechanism account of type amd token frequency effects. Vsevolod Kapatsinski. Indiana University Speech Research Lab. and their relatives. SRL Talk, Fall ‘05. The Problem.

E N D
LAST: A single-mechanism account of type amd token frequency effects Vsevolod Kapatsinski Indiana University Speech Research Lab and their relatives SRL Talk, Fall ‘05
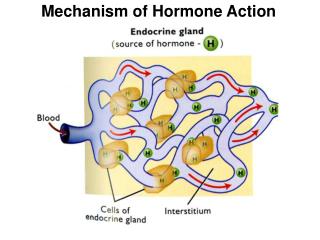
The Problem • Usage-based approaches to language are committed to explaining language structure in terms of domain-general abilities and mechanisms influencing language use • The major focus of the investigation of how use impacts structure have been frequency effects • However, how does frequency do what it does?
Word recognition • High-frequency words are accessed faster in both recognition and production (both for RT’s and M350) • Coltheart et al. (1977), Becker (1979), Glanzer and Ehrenreich (1979), McClelland and Rumelhart (1981), Schvaneveldt and McDonald (1981), Paap et al. (1987), Gordon (1983), Norris (1984), Goldinger et al. (1989), Monsell (1991), Luce et al. (2000), Plaut and Booth (2000), Embick et al. (2001)
Token frequency effects in semantic and orthographic priming • high frequency words are primed by their orthographic and semantic neighbors less than are low frequency words • Perea and Rosa (2000a); Schuberth and Eimas (1977), Schuberth et al (1981), Becker (1979), Stanovich and West (1981, 1983), Stanovich et al (1981), West and Stanovich (1982), Neely (1991), Borowski and Besner (1993), Plaut and Booth (2000)
Token frequency effects in inhibitory phonological priming • Goldinger et al (1989), Luce et al (2000): RT’s are slower when the target is preceded by a phonologically related prime • More inhibition is produced when primes are low frequency than when they are high frequency words The effect holds across excitatory and inhibitory priming.
Token frequency effects in morphological priming • Low frequency stems prime past tense patterns associated with them more than do high frequency stems (Moder 1992)
Token frequency effects in identity priming • Scarborough et al (1977), Jacoby and Dallas (1981), Jacoby (1983), Forster and Davis (1984), Norris (1984), Jacoby and Hayman (1987), Nevers and Versace (1998), Versace (1998), Perea and Rosa (2000a), Versace and Nevers (2003):high frequency words prime themselves less than low frequency words
Network Theory • Moder (1992), Bybee (2001): High frequency weakens a word’s connections to neighboring words PROBLEM • Why does high token frequency reduce the amount of identity priming?
Compound Cue Theory • Ratcliff and McKoon (1988): the prime and the target form a compound cue used to access LTM, the greater the familiarity of the cue, assessed as a function of familiarities of prime and target, the faster LTM access PROBLEM • Why does high frequency of the prime reduce priming and does not increase it?
Distributed Connectionism • Plaut and Booth (2000): prime and target are overlapping patterns of activation distributed over nodes with sigmoid activation functions; the greater the frequency of a prime/target, the smaller the ratio of input activation to output activation
Plaut and Booth 2000 • PROBLEM • The prime and the target do not have an independent existence. Why does frequency of the prime and target and not just frequency of the shared part(s) matter?
Architectural assumptions of the model • Memory is a network • In this network, each unit corresponds to a node • There are type nodes and token nodes such that every memorized chunk, e.g. a word, a morpheme, a phoneme, a construction, owns a type node, and every presentation of a chunk forms a token node • Most or all of the token’s activation spreads to one type (its best match) • Every type is connected to all other types (in a module)
Architecture of memory TYPES TOKENS
Evidence for type and token nodes • Token nodes are necessary to represent sequential structure (Pinker and Prince 1988, Marcus 1998, Pinker 1999) • If there are no token nodes, there is no way to unambiguously represent sequences with repetition Hipppopopotamus? Hipoppotamus? Hippopotamus? H I P O T A M U S
Evidence for type and token nodes • The token nodes are needed to represent exemplar-specific information (e.g. Palmeri et al. 1993, Miller 1994, Pierrehumbert 2002) • Type frequency and token frequency have the opposite effects on morphological productivity: type frequency increases productivity, token frequency decreases it (Bybee 1988, 1995, 2001) • Voice variation influences the magnitude of identity priming (Palmeri et al. 1993) but allophonic variation does not (McLennan et al. 2003) • Identity priming can be preserved across large variations in perceptual input, e.g. cross-modal morphological priming, capital vs. lower-case letters (Bowers 2000)
Evidence for full connectedness among types • Ratcliff and McKoon (1981, 1988): Degree of similarity influences the magnitude of the priming effect in semantic priming but does not influence priming onset (how soon after prime presentation the effect is observed) • If every type was not connected to all other types and activation spread was not instantaneous, activation would reach targets similar to the prime first and those targets would show the effect due to prime presentation earlier
Dynamics of Activation Spread • The amount of activation leaving a node is limited (Anderson 1974, 2000, Lewis and Anderson 1976) • As activation is leaving a node, it is divided between all links connected to that node (Anderson 1974, 2000, Lewis and Anderson 1976) and the node itself.
Account of token frequency effects A new token node is formed, activation spreads to the type node Activation reaches the type node The greater the type node’s r, the less input activation is needed to Recognize/activate the type
Account of token frequency effects Activation is divided between the type node and the links it heads. The more links are connected to the node, the less activation remains in the node and the less activation is allocated to any one link. The greater the frequency of the prime the less priming; also habituation
Account of token frequency effects After activation is divided between the target type and links it heads, the target is presented. Speed of target recognition is increased by priming because presentation of the prime raises the target’s resting activation level. The higher the token frequency of the target, the smaller the increase in resting activation level. Hence, the smaller the increase in speed of recognition due to priming.
Further support for the model:Lexicon size effects • Perfetti and Hogaboam (1975), Stanovich et al (1981), Simpson and Lorsbach (1983), Schwantes (1985), Emmorey et al (1995), Nation and Snowling (1998), Castles et al (1999), Morford (2003) • more priming in younger children, poorer readers, late signers who all have smaller lexicons • Why? • In a small lexicon, each word type node heads fewer links than in a large lexicon more priming
Further support for the model:Speed of recognition and priming • Castles et al. (1999), Plaut and Booth (2000), Morford (2003) • More priming in subjects who are slower at word recognition (even when lexicon size is controlled) • Why? • Slow word recognition comes from low token frequency (r). Low token frequency leads to increased priming (number of Tt links).
Further support for the model:Age of acquisition effects • Bonin et al (2001), Meschyan and Hernandez (2002), Morrison et al (2002, 2003), Newman and German (2002), Zevin and Seidenberg (2002, 2004), Ghyselinck et al (2004): • words learned earlier are recognized and retrieved faster when token frequency is controlled • When the lexicon is small, more activation would reach any given node a greater change to its resting activation level will be produced words with the same token frequency will have a higher resting activation level if they accumulate frequency when the lexicon is small
Type and token frequency • Bybee (1995, 2001): Affixes that attach to many word types are more productive than affixes with low type frequency while high token/type ratio reduces productivity of an affix • In a nonce-probe task, activation spreads from the new type node representing the nonce word • A nonce word is not strongly connected to any of the competing affixes most of activation reaching each of the competing affixes will come through existing words similar to the nonce word • More activation will reach affixes with higher type frequency since there are more possible mediators • High frequency of a mediator decreases its effectiveness at letting through activation less activation will reach affixes with high token/type ratio
Further support for the model:Associative activation/Habituation • Hall (2003): subjects habituate to a stimulus A iff presentations of the tokens of the stimulus are notinterspersed with presentations of tokens of a related stimulus B • When A and B are presented in alternation, strong connections develop between them and presentations of B lead to activation of A. • Direct activation leads to habituation while associative activation counteracts this effect. • When B is activated, it activates A increasing A’s strength/resting activation level while keeping the number of links A heads constant
VI. Neighborhood density effects in priming and equitable distribution of activation
Further features of the model:Dynamics of Activation Spread • Equity Principle: the amount of activation allocated to a link is positively correlated with the strength of the link • A node will attract more activation if the links it heads are weak more identity priming in sparse neighborhoods (Perea and Rosa 2000, Thomsen et al. 1996) • Relative strength effect: an associate of given strength will receive more activation if it has to compete with weak associates than if it has to compete with strong ones (Anaki and Henik 2003), e.g. hammer-nail vs. cat-mouse
TP effects • Aslin et al. 1998: infants can segment speech based solely on transitional probabilities; • TP of B given A = relative strength of AB
VII. The basics of the LAST account of (frequency effects in) associative learning
The model’s view of associative learning • If two nodes are activated simultaneously due to co-occurrence or similarity (shared attributes), the link between them is strengthened because some activation spreads to the link’s propagation filter (PF) • Propagation filters (PF’s): nodes whose resting activation levels determine the strength and sign of links they are situated on but are not influenced by activation passing through the link (Sumida and Dyer 1992, Sumida 1997) more activation would spread through the link if the PF has a high r due to more activation being allocated to the link;
Linktron PF Tail-driven: the tail of the link is the head of the excitatory linktron whose tail is the link’s PF Head Tail
Link structure • Tail driven because • Preceding following > following preceding • Following at higher activation level when preceding and following become co-activated • The link whose PF tailed by a linktron headed by the following must be stronger than the link tailed whose PF is tailed by a linktron headed by the preceding • The link whose tail is the following is stronger • Tail-driven link structure
Linktron PF’s • Binary (+ or -) • Otherwise, link strength would depend equally on characteristics of both the head and the tail of the link • Non-trainable • Otherwise, head-driven inhibitory linktron would weaken tail-driven inhibitory linktron on first trial, leading to link strengthening when the tail is presented in isolation at later trials
Parameter setting time=n time=n+1
Pre-exposure, Desensitization, Blocking • The greater the token frequency of a node, the less activation would reach a given PF the slower the speed of associative learning (lower associability) • Also, if a stimulus has a strong associate, it becomes harder to associate with other stimuli (e.g. Kamin 1969) • Not just rats: • /tlip/ less acceptable than /bwip/ (Moreton 2002) • */tl/ */bw/ • But /t/ and /l/ are more frequent than /b/ and /w/ harder to associate • Cf. also ‘He disappeared it’ vs. ‘He vanished it’ (Brooks and Tomasello 1999)
Logarithmicity of frequency effects • Increase tF by 1 • increase T’s r, • add a T t link • High prior r • Less activation stays in T increase in r is smaller • Less activation is received by the new link’s PF decrease in connectivity is smaller
Size and decay • Activation unit – the cluster of stars in the diagrams; an amount of activation defined by its current location and time and location of creation • The younger the activation unit, the faster it decays • The larger the activation unit, the slower it decays
Asymmetries in priming • Hi freq lo freq < lo freq hi freq • Semantic: Koriat 1981, Chwilla et al. 1998 • Visual: Rueckl 2003 • Morphological: Schriefers et al. 1992, Feldman 2003 • Acoustic: Goldinger et al. 1989 • Phonological: Radeau et al. 1995 • Hi lo – divided into smaller chunks earlier more decay • That is, links headed by a high-frequency node are generally absolutely stronger (because their PF’s are headed by low-frequency nodes) but relatively weaker (because there are more Tt links) • Reduces to rlinktron < rTt
Persistence of morphological, syntactic, and identity priming • Morphological priming – id priming of roots • Syntactic priming (Bock 1986, Bock et al. 2000) – id priming of constructions • Identity priming persists because activation units are larger: relatively much activation from a type’s token(s) stays in the type (rT >> rTt, rTT) rT is same for all nodes • The higher the frequency of a type, the smaller the activation unit remaining in the type don’t find morphological priming with affix repetition, don’t find in phonological, orthographic priming (Emmorey 1989, Feldman 2003, although cf. VanWagenen 2005) • Masked priming: small activation unit, fast decay