Download

1 / 55
550 likes | 561 Views
Discover the importance and challenges of live TV captioning, including manual transcription and speech recognition methods. Learn how automatic captioning improves accessibility and enhances viewer experience in various languages and settings. Explore the future potential of live captioning in translating content and its impact on audiences worldwide. References and insights from industry experts provide valuable information on the evolving landscape of captioning technologies and applications.

E N D
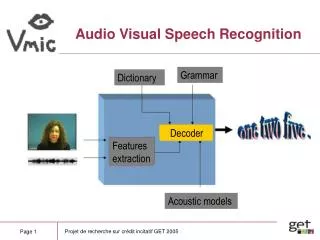
Automatic Speech Recognition and Audio Indexing E.M. Bakker LIACS Media Lab
Topics • Live TV Caption • Audio-based Surveillance Systems • Speaker Recognition • Music/Speech Segmentation
Live TV Captioning • TV Captioning transcribe and display the spoken parts of television programs • BBC pioneer started live captioning in 2001 and is captioning all of its broadcasted programs since May 2008 • Czech Television live captions for Parliament broadcasts since November 2008
Live TV Captioning • Essential for people with hearing ompairment • Helps non-native viewers with their language • Improve first-language literacy • Studies show • In UK 80% of viewers of TV with captions have no hearing impairment [] • In India watching TV with captions improved literacy skills []
Live TV Captioning • Manual transcription of pre-recorded programs • Human captioner listens to and transcribes all speech in a program • Transcription is edited, positioned and aligned • 16 hours work for 1 hour program
Live TV Captioning Captioning of pre-recorded programs using Speech Recognition • Human dictates the speech audio of the program • Transcription is produced by speech recognition • Manually edited if necessary • Significant reduction of effort
Live TV Captioning Live Captioning of TV Programs • Challenge is to produce captions with a minimum delay • Delay should be less than a few seconds • Live is essential for sport events, parliamentary broadcast, live news, etc. • Highly skilled stenographers (200 words/minute) • Have to have a break every 15 minutes. • Difficult to find enough people for large events (Olympic games, World Championship Soccer, …)
Live TV Captioning • BBC started live captioning using speech recognition in April 2001 [] • Since May 2008 100% of its broadcasted programs are captioned • Typical scheme: • a captioner listens to the live program • Re-speak, rephrase and simplify the spoken speech • Enter punctuation and speaker-change info • Speech Recognition engine is adapted to the voice of the captioner
Live TV Captioning Czech Television in cooperation with the University of Bohemia in Pilsen started in November 2008 to do live captioning of parliament meetings Pilot study: • The speech recognition is done on the original speech signal which is sent 5 seconds ahead. • Transcription is sent back immediately • System is trained on 100 hours of Czech Parliament broadcast with their stenographic records Near future • Re-speakers will be used for sports programs, and other live events • Note: Slavic languages have the difficulty of having high degree of inflection, and large numbers of pre- and suf-fixes => much larger vocabulary
Live TV Captioning Application: Automatic Translation • Youtube offers translations of the captions in 41 languages • Translation modeling • Robust error handling of transcription errors made by the sp[eech recognition engine • More difficult for languages that are further apart: English – Japanese, Chinese • Although with errors, it still may be beneficial: human interpretable
References [1] F. Jurcicek, Speech Recognition for Live TV, IEEE Signal Processing Society – SLTC Newsletter, April 2009 [2] M.J. Evans: Speech Recognition in Assited and Live Subtitling for Television, BBC R&D White Paper WHP 065, July 2003 [3] B. Kothari, A. Pandey, and A.R. Chudgar: Reading Out of the "Idiot Box": Same-Language Subtitling on Television in India, Information Technologies and International Development, Volume 2, Issue 1, September 2004 [4] Ofcom: Television access services - Summary, March 2006 [5] R. Griffiths: Giving voice to subtitling: Ruth Griffiths, director of Access Services at BBC Broadcast, July 2005 [6] BBC: Press Releases - BBC Vision celebrates 100% subtitling, May 2008 [7] Blog YouTube: Auto Translate Now Available For Videos With Captions, November 2008
Fear-Type Emotion Recognition [1] • Fear-Type emotion recognition for future audio based surveillance systems • Fear-Type emotions expressed during abnormal situations, possibly life threatening => Public Safety (SERKET Project addressing multi sensory data) • Specially developed corpus SAFE
Fear-Type Emotion Recognition • The HUMAINE network of excellence evaluated emotional databases and noted the lack of corpora that contained strong emotions with a good level of realism. • (Justin, Laukka, 2003): from 104 studies, 87% of the experiments conducted on acted data • For strong emotions this percentage is almost 100%.
Fear-Type Emotion Recognition Acted databases • Stereotype • Realism depends on acting skills • Depends on the context given to the actor • Recently (Banziger and Priker, 2006), (Enos and Hirschberg, 2006), more realistic emotions captured by application of certain acting techniques for more genuine emotions Induce realistic emotions • eWIZ database (Auberge et al. 2003), SAL (Douglas-Cowie et al. 2003). • Fear type emotions: maybe medically dangerous, and/or unethical. Therefore not available. Real-Life databases • Contain strong emotions • Very typical: emergency call center and therapy sessions • Restricted scope of concepts
Annotation of Emotional Content Scherer et al. (1980) push/pull opposite effects in emotional speech. • Physiological excitations push the voice into one direction • Conscious cultural driven effects pull in another direction Represent Emotions in Abstract Dimensions • Various dimensions have been proposed • Whissel (1989) activation/evaluation space is used most frequently because of th elarge range of emotional variation Emotional Description Categories • Basic emotions, Orthony and Turner (1990) • Primary emotions, Damasio (1994) • Ekman and Friesen (1975), the big six, (fear, anger, joy, disgust, sadness, surprise) • And more fuller richer lists of ‘basic’ emotions. Challenges • Real-life emotions are rarely basic emotions, much more a complex blend. • This makes annotating real-life corpora a difficult task. • Diversity of data. • Not living up to industrial expectations. • EARL (Emotion and Annotation Representation Language) by the W3C
Acoustic Features Physiologically related and salient for fear characterization. Voice quality features: High Level Features • Pitch • Intensity • Speech rate • Creaky, breathy, tensed Initially used for speech processing but also for emotion recognition: Low Level Features • Spectral feature • Cepstral features
Classification Algorithms For emotion recognition studies used: • Support Vector Machine • Gaussian Mixture Models • Hidden Markov Models • K-Nearest Neighbors • … Evaluation of the methods is difficult: • Diversity of data and context • The different number and type of emotional classes • Training and test conditions: speaker dependent or independent, etc. • Acoustic feature extraction which are depending on prior knowledge on linguistic content, speaker identity, normalization by speaker, phone, etc.
Audio-Surveillance • Audio clues work even if there are no visual clues: gun shot, human shouts, events out of the camera shot • Important emotional category: Fear Constraints • High diversity of number and type of speakers • Noisy environments: stadium, bank, airport, subway, station, bank, etc. • Speaker independent, high number of unknown speakers • Text-independent (i.e., no speech recognition, quality of recordings is of less importance)
Approach • New emotional database with a large scope of threat concepts following previously listed constraints • A task dependent annotation strategy • Feature extraction of relevant acoustic features • Classification robust to noise and variability of data • Performance evaluation
SAFE Situation Analysis in a Fictional and Emotional Corpus • 7 hours of recordings, fictional movies • 400 audio visual sequences (8 secs – 5 minutes) • Dynamics: normal and abnormal situation • Variability: high variety of emotional Manifestations • Large number of unknown speaker, unknown situations in noisy environment
Annotation • Speaker track: genre and position: aggressor, victim, other • Threat track: degree of threat (no threat, potential, latent, immediate, past threat) plus intensity • Speech track: categories verbal and non-verbal (shouts, breathing, etc.) contents, audio environment (music/noise), quality of speech
Fear-Type Emotion Recognition Emotional categories and subcategories Broad categories Subcategories Fear Stress, terror, anxiety, worry, anguish, panic, distress, mixed subcategories Other negative emotions Anger, sadness, disgust, suffering, deception, contempt, shame, despair, cruelty, mixed subcategories Neutral – Positive emotions Joy, relief, determination, pride, hope, gratitude, surprise, mixed subcategories
Features • Pitch related features (most useful for the fear vs neutral classifier) • Voice quality: jitter and shimmer • Voiced classifier: spectral centroid • Unvoiced classifier: spectral features, Bark band energy
References [1] C.Clavel, I. Vasilescu, L.Devillers, G. Richard, T. Ehrette, Fear-type Emotion Recognition for Future Audio-Based Surveillance Systems, Speech Communication, pp 487-503, Vol. 50, 2008
Special Classes • A. Drahota, A. Costall, V. Reddy, The Vocal Communication of Different kind of Smiles, Speech Communication, pp. 278 – 287, Vol. 50, 2008 • H. S. Cheang, M. D. Pell, The Sound of Sarcasm, Speech Communication, pp. 366 – 381, Vol. 50, 2008
Speaker Recognition/Verification Text independent speaker verification systems (Reynolds et al. 2000) • Short-term spectra of speech signals used to train speaker dependent Gaussian Mixture Models (GMMs) • A GMM-based background model is used to represent the distribution of imposters speech. • Verification is based on th elikelihood-ratio hypothesis test where • Client GMM is distribution of the 0-hypotheses • Background GMM is distribution of the alternative hypotheses
Speaker Recognition/Verification Training the background model is relatively straightforward using large speech corpora of non-target speakers But: Speaker verification based on high-level speaker features requires a large amount of speech for enrollment. Therefore: Adaptation techniques are necessary
Speaker Recognition/Verification Text dependent & very short utterances: • Phoneme dependent HMMs Text Independent & moderate enrollment data (adaptation techniques) • Maximum a Posteriory (MAP) • Maximum Likelihood Linear Regression (MLLR) • Low-level speaker models and speaker clustering • Linear combination of reference models in an eigen voice (EV) • EV adaptation => EVMLLR • Non-linear adaptation by introducing kernel PCA Kernel eigenspace MLLR outperforms other adaptation models when the amount of enrollment data is extremely limited
Speaker Recognition/Verification Features from high- to lower-level Features (Shriberg, 2007) • Pronunciations (Place of birth, education, socioeconomic status, etc.) • Idiolect (Education, socioecconomic status, etc.) • Prosodic (Personality type, parental influence, etc.) • Acoustic (Physical structure of vocal organs)
Speaker Recognition/Verification Pronunciations: • Multilingual phone streams obtained by language dependent phone ASR (N-grams, Bin-tree) • Multilingual phone cross-streams by language dependent phone ASR (N-gram, CPM) • Articulatory features by MLP and phone ASR (AFCPM) Idiolect (Education, socioecconomic status, etc.) • Word streams by word ASR (N-gram, SVM) Prosodic (Personality type, parental influence, etc.) • F0 and Energy distribution by Energy estimator (GMM) • Pitch contour by F0 estimator and word ASR (DTW) • F0 & Energy contour & duration dynamics by F0 & energy estimator & phone ASR (N-gram) • Prosodic statistics from F0 & duration by F0 and energy estimator & word ASR (KNN) Acoustic (Physical structure of vocal organs) • MFCC & its time derivatives (GMM)
Training of Unadapted Phoneme Dependent AFCPM Speaker Models
Adaptation Method A • Classical MAP. Adapted from phoneme dependent background models. • This is based on the classical MAP used in (Leung et al., 2006).
Adaptation Method B • Method B: Phoneme-independent adaptation (PIA). • Adapted from phoneme-dependent speaker models and phoneme-independent speaker models.
Adaptation Method C • Scaled phoneme-independent adaptation (SPI). • Adapted from phoneme-independent speaker models with a phoneme-dependent scaling factor that depends on both the phoneme-dependent and phoneme-independent background models.
Adaptation Method D • Mixed phoneme-dependent and scaled phoneme independent adaptation (MSPI). • Adapted from phoneme-dependent background models and phoneme-independent speaker • models with a phoneme-dependent scaling factor that depends on both the phoneme-dependent and phoneme-independent background models. • This method is a combination of Methods A and C.
Adaptation Method E • Method E: Mixed phoneme-independent and scaled phoneme-dependent adaptation (MSPD). • Adapted from phoneme-independent speaker models and phoneme-dependent background models with a speakerdependent scaling factor that depends on both the phoneme-independent speaker model and background models. • This method is a combination of Methods B and C.