Download

1 / 85
850 likes | 924 Views
Learn about syntax analysis, context-free grammar, parsing methods, and ambiguity in programming language structure. Explore derivations, parse trees, and associativity rules for better language comprehension.

E N D
Organization • Introductory Ideas • Top Down Parsing • Backtracking Top Down Parser • Predictive Top Down Parser • Recursive Descent Parsing • Table driven predictive parser • Bottom Up Parsing • Operator Precedence Parsing • LR Parsing
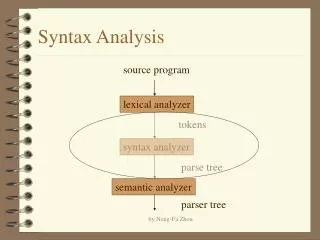
The role of parser token Parse tree Lexical Analyzer Parser Rest of Front End Intermediate representation Source program getNext Token Symbol table
Syntax Analysis • Verifies if the tokens are properly sequenced in accordance with the Grammar of the Language. • Grammar naturally describes the hierarchal structure of programming language. For ex -if else statement can have the form:-> If(expression) statement else statement If-else statement is the concatenation of keyword if, an opening parenthesis, an expression, a closing parenthesis , a statement, the keyword else, and other statement
Specifying Legal Syntax • The sequence of Tokens that are legal in a Programming Language are specified by Context Free Grammar (CFG). stmt-> if(expr) stmt else stmt Such rule are called as production rule. Elements like keyword If and the paranthesis are called terminals. Variables like expr and stnt represent sequence of terminals and are called non-termianls
Production of a grammer specify the manner in which terminals and non-terminals can be combined to form strings. • Each production consist of: • A non-terminal called the head or left side of the production. • The symbol -> . Sometimes ::=has been used in place of the array. • A body or right side consisting of zero or more terminals and non-terminals.
Language of Grammar • Word of grammar is generated by: Productions • Derivation of string starts from Start symbol and repeatedly replacing a non-terminal by the body of production for that non-terminal. • Final state should contain terminals
Parsing • Taking a string of terminals and figuring out how to derive it from the start symbol of the grammar. • If string can not be derived from the start symbol of the grammar , then syntax error is reported.
Derivation Derivations are represented by: • Sentential Form (Using Productions) • Parse Tree (rep. by tree) • Recursion • Grouping of Symbols
Grammars E -> E+E | E*E | id T={id, +, *} N={E} S={E} Derivation: • Right Most Derivation (rightmost non-terminal is always chosen also called canonical derivation) • Left Most Derivation( leftmost non-terminal is always chosen)
Parse tree -(id+id)
Grammars (Example) Given Production is: E -> E+E | E*E | id Derive string : id+id*id using • Right Most Derivation • Left Most Derivation
Grammars (Example) Given Production is: E-> A1B A -> 0A | epsilon B-> 0B | 1B | epsilon Derive string : 00101 using • Right Most Derivation • Left Most Derivation
Parse Tree Given Production is: E -> E+E | E*E | id Draw Parse tree to derive string : id+id*id
Parse Tree Given Production is: E-> A1B A -> 0A | epsilon B-> 0B | 1B | Epsilon Draw Parse tree to derive string : 00101
Example: Parse Tree Given Production is: S-> aS | Sa |a Draw Parse tree to derive string : aa
Example: Parse Tree Given Production is: S-> aSbS | bSaS | epsilon Draw Parse tree to derive string : abab
Parse Tree: Example Given Production is: R-> R+R | RR| R* |a|b|c Draw Parse tree to derive string : a+bc Given the production is: s -> ss+|ss*|a String is: aa+a* • Give the left most derivation • Give the right most derivation • Give the parse tree
s-> 0s1|01 with string 000111 • s-> +ss|*ss|a with string +*aaa • s -> s(s)s|𝞮 with string (()()) • s->s+s|ss|(s)|s*|a with string (a+a)*a
Ambiguity • For some strings grammar generate more than one parse tree • Or more than one leftmost derivation • Or more than one rightmost derivation • Example: id+id*id
Associativity • Because we are not defining grammar in any order. • Left most element on RHS = LHS • For associativity, grammar should be left recursive.
Precedence • High precedence expression should be evaluated first • Should be at lower level of tree • Replace the non terminal with another non terminal
Precedence • If * , + , • Operator which is close to Start symbol Low Precedence
Example: unambiguous grammar • * -> left associative { *.>*} • + -> right associative { +<.+} • - -> both left and right associative. • - has highest precedence • * and + has equal precedence. • So grammar is unambiguous
Recursion • Left recursion:-> Left most variable of R.H.S is equal to L.H.S • A -> A α • Right recursion :-> Right most variable of R.H.S is equal to L.H.S • A -> α A
To remove left recursion: • A -> A α|β A -> β A’ A’ -> 𝞮|αA’
E -> E+T|T • S-> S0S1S|01 • S-> (L)|x L -> L,S|S • A-> A α1| A α2 | A α3…………. β1| β2| β3…….
Examples: • S -> Aa|b A ->Ac | Sd| 𝟄
S -> Aa|a A -> Sb|b
S->A α|d A->S β
A-> AB |Aab |BA| a B->Bb |Aa| b
Left Factoring • Non-deterministic grammar: • A -> 𝞪𝞫1| 𝞪𝞫2| 𝞪𝞫3……. • Decision is taken on the basis of 𝞪. • Grammar is non-deterministic • It is called left-factoring, we need to remove left factoring
To remove left factoring we need to postpone the decision till 𝞫 is encountered • A -> 𝞪A’ • A’ -> 𝞫1|𝞫2|𝞫3……
S -> iEtS|iEtSeS|a E->b • S ->aSSbS|aSaSb|abb|b • S-> bSSaaS|bSSaSb|bSb|a • E -> T+E|T • T->int|int*T|(E) • E-> int|int+E|int-E
S-> a|ab|abc|abcd • S->aAd|aB A->a|ad B->ccd|ddc
Error Handling • Common programming errors • Lexical errors • Syntactic errors • Semantic errors • Lexical errors • Error handler goals • Report the presence of errors clearly and accurately • Recover from each error quickly enough to detect subsequent errors • Add minimal overhead to the processing of correct programs
Error-recover strategies • Panic mode recovery • Discard input symbol one at a time until one of designated set of synchronization tokens is found • Phrase level recovery • Replacing a prefix of remaining input by some string that allows the parser to continue • Error productions • add to the grammar, productions that generate the erroneous constructs • Global correction • Choosing minimal sequence of changes to obtain a globally least-cost correction