Download
1 / 1
10 likes | 140 Views
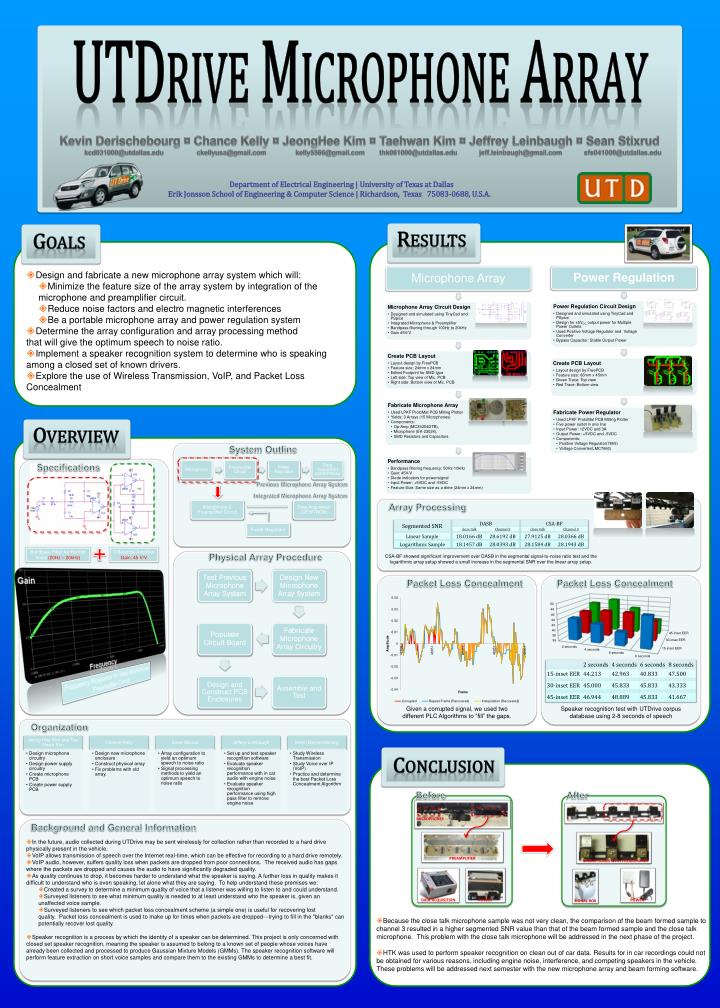
Power Regulator. Microphone & Preamplifier Circuit. Data Acquisition (DEWTRON). UTD rive M icrophone A rray. Kevin Derischebourg ¤ Chance Kelly ¤ JeongHee Kim ¤ Taehwan Kim ¤ Jeffrey Leinbaugh ¤ Sean Stixrud

E N D
Power Regulator Microphone & Preamplifier Circuit Data Acquisition (DEWTRON) UTDrive MicrophoneArray Kevin Derischebourg ¤ Chance Kelly ¤ JeongHee Kim ¤ Taehwan Kim ¤ Jeffrey Leinbaugh ¤ Sean Stixrud kcd031000@utdallas.edu ckellyusa@gmail.com kelly5566@gmail.com thk061000@utdallas.edu jeff.leinbaugh@gmail.com sfs041000@utdallas.edu Department of Electrical Engineering | University of Texas at Dallas Erik Jonsson School of Engineering & Computer Science | Richardson, Texas 75083-0688, U.S.A. Goals • Design and fabricate a new microphone array system which will: • Minimize the feature size of the array system by integration of the microphone and preamplifier circuit. • Reduce noise factors and electro magnetic interferences • Be a portable microphone array and power regulation system • Determine the array configuration and array processing methodthat will give the optimum speech to noise ratio. • Implement a speaker recognition system to determine who is speaking among a closed set of known drivers. • Explore the use of Wireless Transmission, VoIP, and Packet Loss Concealment Results System Outline Overview Previous Microphone Array System Integrated Microphone Array System Array Processing Physical Array Procedure CSA-BF showed significant improvement over DASB in the segmental signal-to-noise ratio test and the logarithmic array setup showed a small increase in the segmental SNR over the linear array setup. Packet Loss Concealment Packet Loss Concealment Specifications Bandpass Filter for Human Voice (20Hz – 20kHz) Differential Amplifier Gain: 45 V/V Given a corrupted signal, we used two different PLC Algorithms to “fill” the gaps. Speaker recognition test with UTDrive corpus database using 2-8 seconds of speech Organization Conclusion Before After microphones Frequency Response for Ideal Microphone Preamplifier Circuit Background and General Information preamplifier microphones with preamplifier • In the future, audio collected during UTDrive may be sent wirelessly for collection rather than recorded to a hard drive physically present in the vehicle. • VoIP allows transmission of speech over the Internet real-time, which can be effective for recording to a hard drive remotely. • VoIP audio, however, suffers quality loss when packets are dropped from poor connections. The received audio has gaps where the packets are dropped and causes the audio to have significantly degraded quality. • As quality continues to drop, it becomes harder to understand what the speaker is saying. A further loss in quality makes it difficult to understand who is even speaking, let alone what they are saying. To help understand these premises we: • Created a survey to determine a minimum quality of voice that a listener was willing to listen to and could understand. • Surveyed listeners to see what minimum quality is needed to at least understand who the speaker is, given an unaffected voice sample. • Surveyed listeners to see which packet loss concealment scheme (a simple one) is useful for recovering lost quality. Packet loss concealment is used to make up for times when packets are dropped---trying to fill in the "blanks" can potentially recover lost quality. • Speaker recognition is a process by which the identity of a speaker can be determined. This project is only concerned with closed set speaker recognition, meaning the speaker is assumed to belong to a known set of people whose voices have already been collected and processed to produce Gaussian Mixture Models (GMMs). The speaker recognition software will perform feature extraction on short voice samples and compare them to the existing GMMs to determine a best fit. data acquisition power power signal box • Because the close talk microphone sample was not very clean, the comparison of the beam formed sample to channel 3 resulted in a higher segmented SNR value than that of the beam formed sample and the close talk microphone. This problem with the close talk microphone will be addressed in the next phase of the project. • HTK was used to perform speaker recognition on clean out of car data. Results for in car recordings could not be obtained for various reasons, including engine noise, interference, and competing speakers in the vehicle. These problems will be addressed next semester with the new microphone array and beam forming software.