Download

1 / 16
160 likes | 269 Views
Implementation of Cache Coherency in NoC Mike Cika 2/29/2012. Brief Overview. What is Cache Coherency Problems with Cache Coherency Some Solutions to These Problems. What is Cache Coherency?. Shared Memory Multiprocessors every processor has its own cache

E N D
Brief Overview • What is Cache Coherency • Problems with Cache Coherency • Some Solutions to These Problems
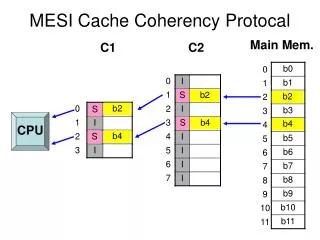
What is Cache Coherency? • Shared Memory Multiprocessors • every processor has its own cache • DRAM Slices Split Among Processors • faster access to required data • read/write requests require communication • must maintain data integrity Culler, Singh “Parallel Computer Architecture: A Hardware/Software Approach” 1999
What is Cache Coherency? • Provide a Set of Locations That Hold Data • Data at Location Must be Up-to-Date Culler, Singh “Parallel Computer Architecture: A Hardware/Software Approach” 1999
Problems in NoC • Directory Based Lookup Required for Scalable Designs • Maintaining Coherency is Much More Difficult than Before Requestor Directory Node Write Miss Invalidations Received P P P P L2 L2 L2 L2 L1 L1 L1 L1 Respond With Sharers ID Invalidations Sent Sharer Sharer
Problems in NoC • With Large Number of Nodes Problems Arise • 1-to-M Communication • duplicate unicast messages • how/where to duplicate • avoid double duplications
Towards the Ideal On-chip Fabric for 1-to-Many and Many-to-1 Communication • Motivation for Work • Overview Tushar Krishna, Li-ShiuanPeh, Bradford M. Beckmann, and Steven K. Reinhardt Dept. of EECS, MIT, Cambridge, MA AMD Research, Bellevue, WA {tushar, peh}@csail.mit.edu, {Brad.Beckmann, Steve.Reinhardt}@amd.com
Ideal 1-to-M Motivation • Traffic Patterns • research shows high number of 1-to-M traffic • performance of 1-to-M needs to rival 1-to-1 Krishna, T. Peh, L. Beckmann, B. Reinhardt, S. Towards the Ideal On-Chip Fabric for 1-to-Manh and Many-to-1 Communication. Micro’11..
FANOUT: Flow Across Network Over Uncongested Trees • Load Balancing • links may go unused • Whirl Algorithm • virtual multicast trees • need to be load balanced
FANOUT: Flow Across Network Over Uncongested Trees • Algorithm Constraints • load balanced for broadcasts and dense 1-to-M • ensure non-duplicate reception • not table based • deadlock free Krishna, T. Peh, L. Beckmann, B. Reinhardt, S. Towards the Ideal On-Chip Fabric for 1-to-Manh and Many-to-1 Communication. Micro’11..
FANOUT: Flow Across Network Over Uncongested Trees • Routing for Multicast Messages • left turn bit (LTB), right turn bit (RTB) • each direction carries these two bits • each LTB is randomly chosen for a given direction • ensures load balanced approach RTBs = ~LTBwRTBe = ~LTBs RTBw = ~LTBnRTBn = ~LTBe Krishna, T. Peh, L. Beckmann, B. Reinhardt, S. Towards the Ideal On-Chip Fabric for 1-to-Manh and Many-to-1 Communication. Micro’11..
FANOUT: Flow Across Network Over Uncongested Trees • All Turns Except U-turns Allowed • deadlock avoidance required • Conventional Virtual Channel Management • VC-a in south direction • VC-b in in all other directions Krishna, T. Peh, L. Beckmann, B. Reinhardt, S. Towards the Ideal On-Chip Fabric for 1-to-Manh and Many-to-1 Communication. Micro’11..
mXbar: Forking Packets • Duplicating Packets in Router • reading same flit multiple times • serialization delay, increased buffer occupancy • reading flit once and forking it in the crossbar Krishna, T. Peh, L. Beckmann, B. Reinhardt, S. Towards the Ideal On-Chip Fabric for 1-to-Manh and Many-to-1 Communication. Micro’11..
Single-cycle Fanout Router • 2-Stage Pipeline Realized Using Lookahead Routing • multiple flits can have multiple next routers • 1-Stage Realized by Sending k+4 Bit Vector, Bufferless Kumar, A. Peh, L. Kundu, P. Jha, N. Express Virtual Channels: Toward the Ideal Interconnection Fabric. ISCA, June 2007.
Fanin Performance Evaluation Krishna, T. Peh, L. Beckmann, B. Reinhardt, S. Towards the Ideal On-Chip Fabric for 1-to-Manh and Many-to-1 Communication. Micro’11..
Further Discussion/Questions • Other Topologies • router forking scalable for N-dimension cubes • non cube/mesh topology require more overhead • Utilizing Optics • broadcast by nature • used more in high core numbers (1024+) • Changing Router Design • rotary based routers • flit travel around circle twice for a duplicate