Download
1 / 12

E N D
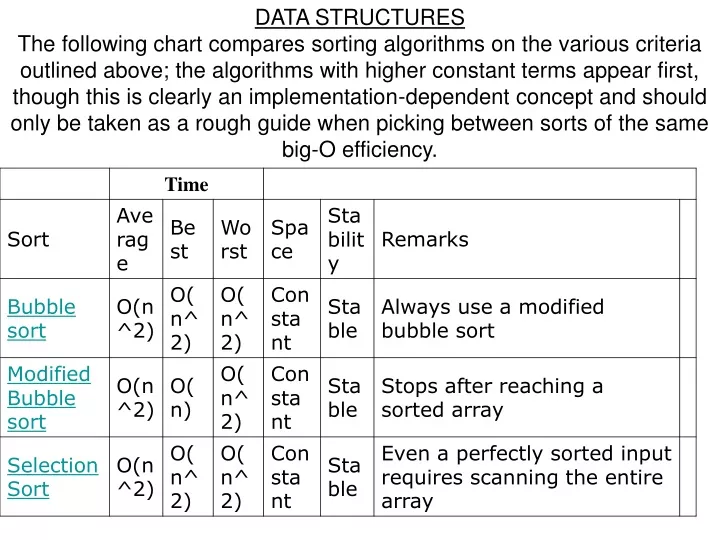
DATA STRUCTURES The following chart compares sorting algorithms on the various criteria outlined above; the algorithms with higher constant terms appear first, though this is clearly an implementation-dependent concept and should only be taken as a rough guide when picking between sorts of the same big-O efficiency.
Linked lists are the most basic self-referential structures. Linked lists allow you to have a chain of structs with related data. So how would you go about declaring a linked list? It would involve a struct and a pointer: struct llnode { <type> data; struct llnode *next; }; Enter hash tables. Hash tables provide O(1) performance while having the ability to grow dynamically. The key to a well-performing hash table is understanding the data that will be inserted into it. By custom tailoring an array of pointers, you can have O(1) access. But you are asking, how do you know where a certain data piece is in within the array? This is accomplished through a key. A key is based off the data, the most simple one's involve applying a modulus to a certain piece of information within the data. The general rule, is that if a key sucks, the hash table sucks. A data structure is said to be linear if its elements form a sequence or a linear list. Examples: • Arrays • Linked Lists • Stacks, Queues
A data type describes representation, interpretation and structure of values manipulated by algorithms or objects stored in computer memory or other storage device. The type system uses data type information to check correctness of computer programs that access or manipulate the data. Computer storage such that information is fixed in space and available at any time,. A priority queue is an abstract data type in computer programming, supporting the following three operations: add an element to the queue with an associated priority remove the element from the queue that has the highest priority, and return it (optionally) peek at the element with highest priority without removing it The simplest way to implement a priority queue data type is to keep an associative array mapping each priority to a list of elements with that priority.
(2) In programming, a queue is a data structure in which elements are removed in the same order they were entered. This is often referred to as FIFO (first in, first out). In contrast, a stack is a data structure in which elements are removed in the reverse order from which they were entered. This is referred to as LIFO (last in, first out). 1.1. Static vs Dynamic Memory Allocation The issue we address in this lecture is the efficient use of memory. The issue arises because of inefficiencies inherent in the way memory is allocated for arrays. When you declare an array of size 1000, all 1000 memory locations are reserved for the exclusive use of that array. No matter how many values you actually store in the array, you will always use 1000 memory locations. The same memory allocation strategy is used for most implementations of strings. I will use the term static allocation to refer to this memory allocation strategy, in which all the memory that a data structure might possibly need (as specified by the user) is allocated all at once without regard for the actual amount needed at execution time. The opposite strategy, dynamic allocation, involves allocating memory on an as-needed basis.
There always is an absolute maximum of memory that can be allocated: this is simply the amount of memory that is physically available on your computer (more precisely, the amount of memory that is addressable by your computer). No allocation strategy can get around this. Three applications of stacks are presented here. These examples are central to many activities that a computer must do and deserve time spent with them. Expression evaluation Backtracking (game playing, finding paths, exhaustive searching) Memory management, run-time environment for nested language features. Linked lists concepts are useful to model many different abstract data types such as queues stacks and trees. If we restrict the process of insertions to one end of the list and deletions to the other end . Skewed tree : a tree which have only one side to any level (right or left )
an adjacency list is the representation of all edges or arcs in a graph as a list. A binary search algorithm (or binary chop) is a technique for finding a particular value in a linear array, by ruling out half of the data at each step, widely but not exclusively used in computer science. A binary search finds the median, makes a comparison to determine whether the desired value comes before or after it, and then searches the remaining half in the same manner. A binary search is an example of a divide and conquer algorithm (more specifically a decrease and conquer algorithm) and a dichotomic search If the graph is undirected, every entry is a set of two nodes containing the two ends of the corresponding edge; if it is directed, every entry is a tuple of two nodes, one denoting the source node and the other denoting the destination node of the corresponding arc. Typically, adjacency lists are unordered.
Fibonacci search A very similar algorithm can also be used to find the extremum (minimum or maximum) of a sequence of values that has a single local minimum or local maximum. In order to approximate the probe positions of golden section search while probing only integer sequence indices, the variant of the algorithm for this case typically maintains a bracketing of the solution in which the length of the bracketed interval is a Fibonacci number. For this reason, the sequence variant of golden section search is often called Fibonacci search. a hash collision is a situation that occurs when two distinct inputs into a hash function produce identical outputs A hash function[1] is a reproducible method of turning some kind of data into a (relatively) small number that may serve as a digital "fingerprint" of the data. The algorithm "chops and mixes" (i.e., substitutes or transposes) the data to create such fingerprints, called hash values. These are commonly used as indices into hash tables or hash files. Cryptographic hash functions are used for various purposes in information security applications.
a sparse matrix is a matrix populated primarily with zeros. The naive data structure for a matrix is a two dimensional array. Each entry in the array represents an element ai,j of the matrix and can be accessed by the two indices i and j. For a n×m matrix we need at least (n*m) / 8 bytes to represent the matrix when assuming 1 bit for each entry. Depth-first search (DFS) is an algorithm for traversing or searching a tree, tree structure, or graph. Intuitively, one starts at the root (selecting some node as the root in the graph case) and explores as far as possible along each branch before backtracking. In graph theory, breadth-first search (BFS) is a graph search algorithm that begins at the root node and explores all the neighboring nodes. Then for each of those nearest nodes, it explores their unexplored neighbor nodes, and so on, until it finds the goal Definitions for rooted trees A directed edge refers to the link from the parent to the child (the arrows in the picture of the tree). A leaf is a node that has no children. The depth of a node n is the length of the path from the root to the node. The set of all nodes at a given depth is sometimes called a level of the tree. The height of a tree is the length of the path from the root node to its furthest leaf. Siblings are nodes that share the same parent node.
If a path exists from node p to node q, then p is an ancestor of q and q is a descendant of p. The size of a node is the number of descendants it has including itself. A full binary tree, or proper binary tree, is a tree in which every node has zero or two children. A perfect binary tree (sometimes complete binary tree) is a full binary tree in which all leaves are at the same depth. A complete binary tree may also be defined as a full binary tree in which all leaves are at depth n or n-1 for some n. In order for a tree to be the latter kind of complete binary tree, all the children on the last level must occupy the leftmost spots consecutively, with no spot left unoccupied in between any two. For example, if two nodes on the bottommost level each occupy a spot with an empty spot between the two of them, but the rest of the children nodes are tightly wedged together with no spots in between, then the tree cannot be a complete binary tree due to the empty spot. An almost complete binary tree is a tree in which each node that has a right child also has a left child. Having a left child does not require a node to have a right child. Stated alternately, an almost complete binary tree is a tree where for a right child, there is always a left child, but for a left child there may not be a right child..
A threaded binary tree may be defined as follows: A binary tree is threaded by making all right child pointers that would normally be null point to the inorder successor of the node, and all left child pointers that would normally be null point to the inorder predecessor of the node." To traverse a non-empty binary tree in preorder, we perform the following three operations: 1. Visit the root. 2. Traverse the left subtree in preorder. 3. Traverse the right subtree in preorder. To traverse a non-empty binary tree in inorder, perform the following operations: 1. Traverse the left subtree in inorder. 2. Visit the root. 3. Traverse the right subtree in inorder. To traverse a non-empty binary tree in postorder, perform the following operations: 1. Traverse the left subtree in postorder. 2. Traverse the right subtree in postorder. 3. Visit the root. Finally, trees can also be traversed in level-order, where we visit every node on a level before going to a lower level.
Converse of inorder is right root left Converse of pre order is root right left Converse of inorder is right left root a binary search tree (BST) is a binary tree data structure which has the following properties: Each node has a value. A total order is defined on these values. The left subtree of a node contains only values less than the node's value. The right subtree of a node contains only values greater than or equal to the node's value. Sortd form of data if we perform inorder on BST



















