Download

1 / 36
530 likes | 1.15k Views
Multistep Virtual Metrology Approaches for Semiconductor Manufacturing Processes. Presenter: Simone Pampuri (University of Pavia, Italy). Authors: Simone Pampuri , University of Pavia, Italy Andrea Schirru, University of Pavia, Italy Gian Antonio Susto , University of Padova, Italy

E N D
Multistep Virtual Metrology Approaches for Semiconductor Manufacturing Processes Presenter: Simone Pampuri (University of Pavia, Italy) Authors:Simone Pampuri, University of Pavia, Italy Andrea Schirru, University of Pavia, Italy Gian Antonio Susto, University of Padova, Italy Cristina De Luca, Infineon Technologies AT, Austria Alessandro Beghi, University of Padova, Italy Giuseppe De Nicolao, University of Pavia, Italy
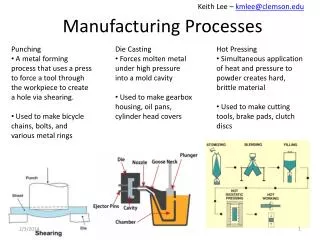
Introduction • Collaboration between University of Pavia (Italy), University of Padova (Italy) and Infineon Technologies AT (Austria) • Activity funded by the European project EU- • IMPROVE: Implementing Manufacturing science solutions to increase equiPment pROductiVity and fab pErformance
Introduction • Collaboration between University of Pavia (Italy), University of Padova (Italy) and Infineon Technologies AT (Austria) • Activity funded by the European project EU- • IMPROVE: Implementing Manufacturing science solutions to increase equiPment pROductiVity and fab pErformance • Duration: 42 months (since Jan 2009) • Global fundings: 37.7 M€ • 32 partners, including • Semiconductor fabs • Academic institutions • Research centers • Software houses • Thematic Work Packages
Contents Motivations 1 Machine Learning 2 Multilevel framework 3 Multistep VM 4 Results and Conclusions 5 5
What is Virtual Metrology? • In semiconductor manufacturing, measurement operations are costly and time-consuming • Only a small part of the production is actually measured
What is Virtual Metrology? • In semiconductor manufacturing, measurement operations are costly and time-consuming • Only a small part of the production is actually measured • Virtual metrology exploits sensors and logistic information to predict process outcome Sensor Data VM Recipe Data Logistic Data
What is Virtual Metrology? • In semiconductor manufacturing, measurement operations are costly and time-consuming • Only a small part of the production is actually measured • Virtual metrology exploits sensors and logistic information to predict process outcome Sensor Data Controllers VM Sampling tools PredictiveInformation Recipe Data Decision tasks Logistic Data
Contents Motivations 1 Machine Learning 2 Multilevel framework 3 Multistep VM 4 Results and Conclusions 5 5
Machine learning (in a nutshell) • Machine learning algorithms create models from observed data (training dataset), using little or no prior informations about the physical system Modelf(X) LearningAlgorithm Output (Y) Input (X) Training dataset
Machine learning (in a nutshell) • Machine learning algorithms create models from observed data (training dataset), using little or no prior informations about the physical system • The model is then able to predict patterns similar to the observed ones Modelf(X) LearningAlgorithm Output (Y) Input (X) Training dataset Input (Xnew) Prediction (Ynew) Model
Machine learning (in a nutshell) • Machine learning algorithms create models from observed data (training dataset), using little or no prior informations about the physical system • The model is then able to predict patterns similar to the observed ones Most famous algorithm: Ordinary Least Squares (OLS) that consists in solving the optimization problem defined by the loss function Modelf(X) LearningAlgorithm Output (Y) Input (X) Training dataset Input (Xnew) Prediction (Ynew) Model
The curse of dimensionality Problem: the so-called “curse of dimensionality” Consequence: the predictive power of machine learning models reduces as the number of candidate predictors increases In semiconductor manufacturing, it is common to have hundredsof candidate predictors: how totackle the problem? The number of selected predictors grows almost linearly with the number of candidate predictors
The curse of dimensionality Problem: the so-called “curse of dimensionality” Consequence: the predictive power of machine learning models reduces as the number of candidate predictors increases In semiconductor manufacturing, it is common to have hundredsof candidate predictors: how totackle the problem? The number of selected predictors grows almost linearly with the number of candidate predictors Regularization (or Penalization) methods
The curse of dimensionality Problem: the so-called “curse of dimensionality” Consequence: the predictive power of machine learning models reduces as the number of candidate predictors increases Ridge (or Tikhonov) regression: in order to improve the least squares method, stable (“easier”) solutions are encouraged by penalizing coefficients through the parameter a 1943 The number of selected predictors grows almost linearly with the number of candidate predictors
The curse of dimensionality Problem: the so-called “curse of dimensionality” Consequence: the predictive power of machine learning models reduces as the number of candidate predictors increases Ridge (or Tikhonov) regression: in order to improve the least squares method, stable (“easier”) solutions are encouraged by penalizing coefficients through the parameter a 1943 The number of selected predictors grows almost linearly with the number of candidate predictors • Best value for hyperparameter is chosen via validation • Computationally easy (closed form solution) • No sparse solution
The curse of dimensionality Problem: the so-called “curse of dimensionality” Consequence: the predictive power of machine learning models reduces as the number of candidate predictors increases The number of selected predictors grows almost linearly with the number of candidate predictors L1-penalized methods: by constraining the solution to belong to an hyper-octahedron, sparse models can be obtained (variable selection). Most famous example: LASSO 1996 – today
The curse of dimensionality Problem: the so-called “curse of dimensionality” Consequence: the predictive power of machine learning models reduces as the number of candidate predictors increases The number of selected predictors grows almost linearly with the number of candidate predictors • Best value for hyperparameter is chosen via validation • Sparse solution (variable selection) • Solved by iterative algorithms (e.g. SMO) L1-penalized methods: by constraining the solution to belong to an hyper-octahedron, sparse models can be obtained (variable selection). Most famous example: LASSO 1996 – today
Contents Motivations 1 Machine Learning 2 Multilevel framework 3 Multistep VM 4 Results and Conclusions 5 5
The hierarchical variability We deal every day with multiple levels of variability: Every equipment has several chambers In some cases, these chambers are splitted in sub-chambers Different process groups, recipes run on the same equipment
The hierarchical variability We deal every day with multiple levels of variability: Every equipment has several chambers In some cases, these chambers are splitted in sub-chambers Different process groups, recipes run on the same equipment Simple (“naive”) solution: create one model for every possible combination of factors We’ll never have enough data to that, especially for low volume recipes
The hierarchical variability We deal every day with multiple levels of variability: Every equipment has several chambers In some cases, these chambers are splitted in sub-chambers Different process groups, recipes run on the same equipment Simple (“naive”) solution: create one model for every possible combination of factors We’ll never have enough data to that, especially for low volume recipes Better solution: handle those different levels of variability inside the model
The hierarchical variability We deal every day with multiple levels of variability: Every equipment has several chambers In some cases, these chambers are splitted in sub-chambers Different process groups, recipes run on the same equipment Simple (“naive”) solution: create one model for every possible combination of factors We’ll never have enough data to that, especially for low volume recipes Better solution: handle those different levels of variability inside the model Multilevel Techniques: Multilevel Ridge Regression (RR) & Multilevel Lasso
The Multilevel Transform • First step is to create an extended input matrix to reflect the relationships between the j clusters. For instance, in the case of j mutually exclusive nodes, • The input matrix reflects the dependency on logistic paths
Contents Motivations 1 Machine Learning 2 Multilevel framework 3 Multistep VM 4 Results and Conclusions 5 5
Standard scenario • Production flow: sequence of steps; each step represents an operation that must be performed on a wafer in order to obtain a specific results • Each step is performed by different equipment (composed by multiple chambers): • The knowledge of which wafer is processed by a specific equipment is available (logistic information) • The information about processed wafer (e.g. sensor readings and recipe setup) might be available • On some equipments a “single step” VM system is already in place (estimated measures for each processed wafer are available)
Cascade Multistep VM • This approach allow to build a pipe system in which the predictive information is propagated forward to concur to further model estimation. • The generation of multilevel input matrix consists in replace j-th cluster’s process variables with j-th VM-j estimation
Cascade Multistep VM • This approach allow to build a pipe system in which the predictive information is propagated forward to concur to further model estimation. • The generation of multilevel input matrix consists in replace j-th cluster’s process variables with j-th VM-j estimation • Pros: • Small overhead append to the input space • Computational effort very similar to “single step” VM case • Cons: • Steps without “single step” VM must be excluded • There might be some information loss between two or more steps
Process and Logistic Multistep VM • With this approach, all the relevant logistic, process and recipe information from all the considered steps is included in the input set • In this case, the generation of input matrix fully follows the previous Multilevel Transform
Process and Logistic Multistep VM • With this approach, all the relevant logistic, process and recipe information from all the considered steps is included in the input set • In this case, the generation of input matrix fully follows the previous Multilevel Transform • Pros: • Steps with no (or meaningless) measurements can be included • All the available information is provided to the learning algorithm • Cons: • Input space dimension is significantly increased by this approach • More observations are needed to train the learning algorithm
Contents Motivations 1 Machine Learning 2 Multilevel framework 3 Multistep VM 4 Results and Conclusions 5 5
Production flow for methodologies validation: Chemical Vapor Deposition (CVD) Thermal Oxidation Coating Lithography Target: post-litho CDs Dataset: 583 wafers anonymized Hyper-parameter tuning: 10-fold crossvalidation Multistep VM setups: CVD-Litho Cascade CVD-Litho Process and Full Logistic Scenario
Cascade The cascade VM allows to further improve the VM performances using RR. This result might be related to the additional hidden knowledge provided by the intermediate CVD metrology prediction. The cascade approach performs worse with the LASSO. It should be noted that this is the only case in which the extended input space does not improve the predictive performances.
Process and Full Logistic Validation RMSE results for Ridge Regression: it is apparent how the full step choice allows to improve the predictive performances. LASSO is consistently outperformed by Ridge Regression in the dataset that was used for the experiment; nevertheless, the extended input space proves to be fruitful also in this case, with respect to the Lithography based approach.
Best Lasso and Best RR The best overall results for Ridge Regression are obtained with the cascade approach and by considering all the process steps. For the LASSO, the best overall results are obtained by considering the extended process values for all the involved steps.
Research and design of Multistep VM strategies targeted to specific semiconductor manufacturing needs Main features: Enhancing precision and accuracy of regular VM system Taking in account process without measurements Tests showed promising results; however, the strategy to be implemented must be carefully designed: Sample size and relevance of the steps are fundamental criteria to obtain the best performances Conclusions
Thanks for your attention! www.themegallery.com Presenter: Simone Pampuri (University of Pavia, Italy) Authors:Simone Pampuri, University of Pavia, Italy Andrea Schirru, University of Pavia, Italy Gian Antonio Susto, University of Padova, Italy Cristina De Luca, Infineon Technologies AT, Austria Alessandro Beghi, University of Padova, Italy Giuseppe De Nicolao, University of Pavia, Italy